YOLO9000: Better, Faster, Stronger
Links
- PDF Attachments: 2016’YOLO9000_Redmon,Farhadi_.pdf
- Zotero Links: Local library
My Comments and Inspiration
Cores, Contributions and Conclusions
- 添加 Trick
- 引入K-means来找bbox size
Motivation
Yolo v1 有2个缺点
- v1会产生很多定位错误 (localization error)
- 相比于双阶段网络,v1 的召回率很差
为此,本文主要想在保持准确率的前提下解决上面两个问题。
Methods

Better
本文的重点在于在 Yolo v1 的基础上添加了更多新的策略来提升。
最最重要的一个策略是从 anchor free 变成了 anchor based 的方法。
- 添加 Batch Normalization 层
- 彼时 BN 刚刚出现,v1 中还未添加
- 在所有卷积层后面添加 BN 层,mAP 提升 2%左右
- 添加了 BN 就可以去掉 Dropout 了
- 高分辨率分类器 (High Resolution Classifier)
- 本质上就是高分辨率输入 (),v1 也有
- 和 v1 不同:v1 是 224 的尺寸直接在 ImageNet 上训,然后拿过来扩到 448 后 直接用 ;v2 拿过来后扩到 448 后,先在 ImageNet 再跑 10 个 epoch,然后再用来检测
- 大约有 4%的 mAP 提升
- 引入 Anchor 并修改最后的网络层
- v1中使用全连接层直接预测bbox参数,而在 v2中移除了v1中的全连接层和最后一层pooling层(由于官方代码已经被v3替换,详细细节无从得知,感觉可能是替换成为了1*1的卷积)
- 预测 bbox 的偏移量而非直接预测 bbox(对 Faster RCNN 进行了改进)
- 原始Fast RCNN中的预测偏移量的公式在这里不稳定(为什么)
- 为了解决这个问题,v2 对于每个 bbox 同样预测 5 个参数,分别是 。但是v2预测的是边界框中心点相对于对应cell左上角位置的相对偏移值。为了将bbox的中心点约束在当前cell中,使用sigmoid函数将归一化处理,将值约束在
0~1,这使得模型训练更稳定(都已经归一化了)。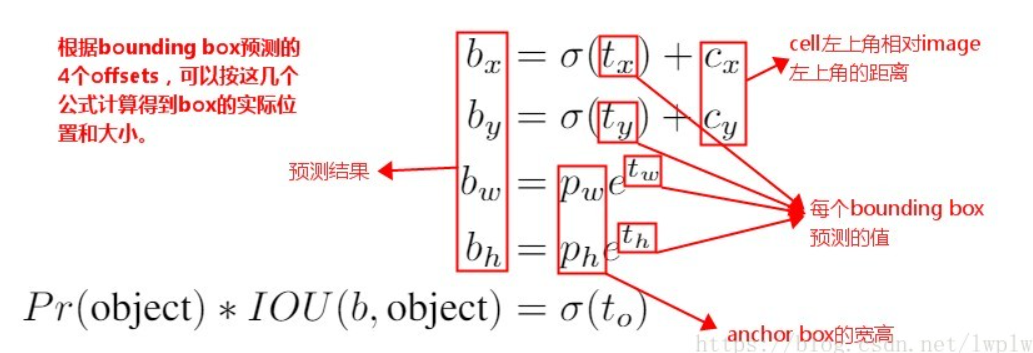
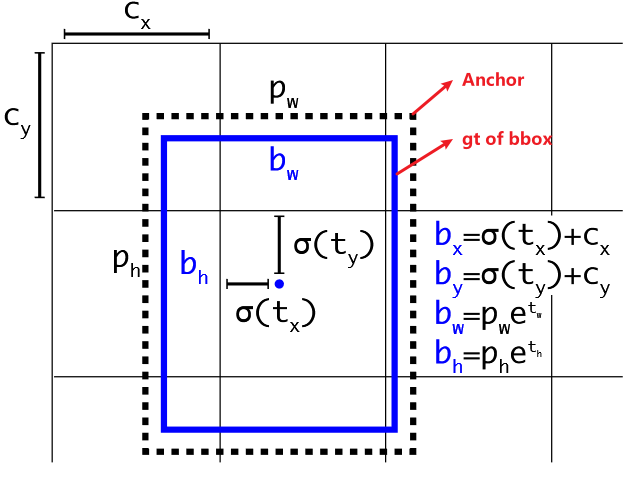
- 采用聚类方式自动选择 Anchor ratio / size
- 先利用训练集的 bbox label 使用 K-means 去找 anchor size 的
- 原文中
- 作者指出仅选取5种box就能达到Faster RCNN的9种box的效果
- 浅层特征与深层特征融合 (Fine-Grained Features.)
- 作者将网络中间层的输出尺寸为 的特征图和最终输出尺寸为 的特征图进行了融合,作者认为这样可以减少细粒度特征的损失,更好的识别小物体
- 的特征图首先经过passthrough层,变成,然后直接和最后一层卷积层输出的的特征图融合,得到的特征图
- 多尺度训练
- 由于 v2 中只含有卷积层和 pooling 层,因此 v2 实际上是可以接受任意尺寸的输入图像的。只是需要注意作者原文中的网络降采样倍数为 32,所以输入图像的尺寸需要限制在 32 的倍数。
- 这里,作者引入多尺度训练的策略,每隔 10 个 batches,输入图像的尺寸从{320, 352, …, 608}中重新选择。不同的输入图像尺寸意味着切分的 grid Cell 的数量不一样(cell 边长相等的话),也就是说最终输出的 tensor 宽高不同(对应 cell 的数量)。
- 举个例子,当输入为 320*320 时,输出为 10*10 的 Tensor,若每个 cell 分配 5 个 anchor,则 tensor 尺寸为 (假设有 20 类),而当输入尺寸为 608 时,tensor 尺寸为
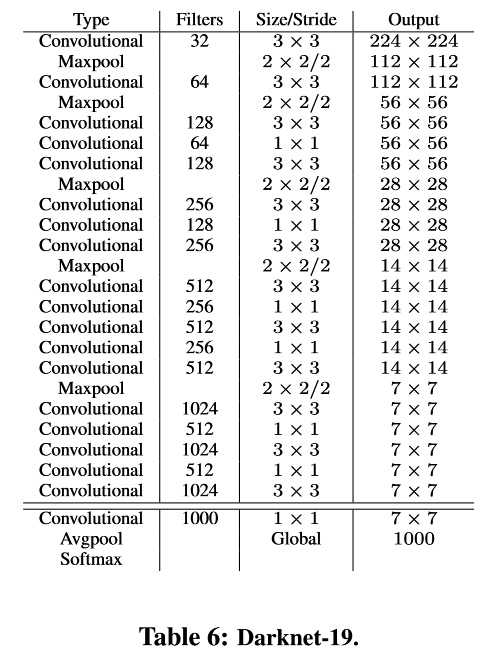
Faster: 新的 Backbone (Darknet-19)
19 个卷积层,5 个 maxpooling 层,比VGG-16参数量更少
72.9% top-1 accuracy and 91.2% top-5 accuracy on ImageNet.
为什么说原来Fast RCNN中的bbox预测方式不稳定?
在 two stage 的 Fast RCNN 中,对于 (x, y) 预测的是 offset,即
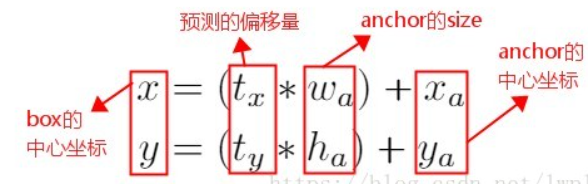
由于上面的公式是没有约束的,即
当时,box将向右偏移一个anchor box的宽度;
当 时,box 将向左偏移一个 anchor box 的宽度
这就可能导致每个 cell 预测出来的 bbox 可能会在图片中的任意位置,即中心不在这个 cell 中。
但是,yolo 的一个前提就是每个 cell 只负责预测物体中心落在这个 cell 里的 bbox,那么自然对应bbox中心也在应该在这个cell里。
这就导致模型的不稳定性,在训练时需要很长时间来预测出正确的 offsets
Stronger
带标注的检测数据集量比较少,而带标注的分类数据集量比较大,因此YOLO9000主要通过结合分类和检测数据集使得训练得到的检测模型可以检测约9000类物体。 一方面要构造数据集(采用WordTree解决),另一方面要解决模型训练问题(采用Joint classification and detection)。
Loss 细节
- 和 YOLOv1 一样,对于训练图片中的 ground truth,若其中心点落在某个 cell 内,那么该 cell 内的 5 个先验框所对应的边界框负责预测它,具体是哪个边界框预测它,需要在训练中确定,即由那个与 ground truth 的 IOU 最大的边界框预测它,而剩余的 4 个边界框不与该 ground truth 匹配,即被压制。YOLOv2 同样需要假定每个 cell 至多含有一个 grounth truth,而在实际上基本不会出现多于 1 个的情况。与 ground truth 匹配的先验框计算坐标误差、置信度误差(此时 target 为 1)以及分类误差,而其它的边界框只计算置信度误差(此时 target 为 0)。
- YOLOv2 和 YOLOv1 的损失函数一样,为均方差函数。但是看了 YOLOv2 的源码(训练样本处理与 loss 计算都包含在文件 region_layer. c 中),并且参考国外的 blog 以及 allanzelener/YAD2K(Ng 深度学习教程所参考的那个 Keras 实现)上的实现,发现 YOLOv2 的处理比原来的 v1 版本更加复杂。
Loss 计算公式
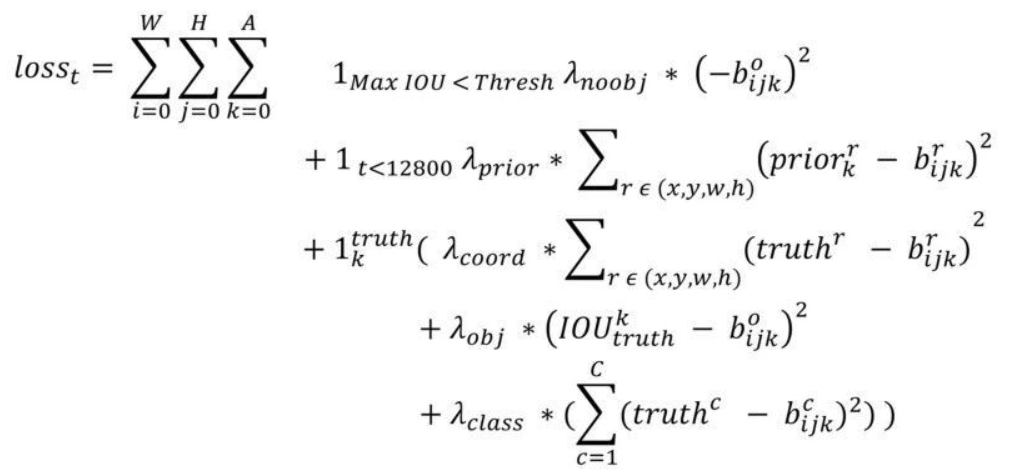 (1)W,H分别指的是特征图(13*13)的宽与高;
(2)A指的是先验框数目(这里是5);
(3)各个λ值是各个loss的权重系数,参考YOLOv1的loss;
(4)第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差;
(5)第二项是计算先验框与预测宽的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状;
(6)第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。
先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。
在计算 obj 置信度时,在 YOLOv1 中 target=1,而 YOLOv2 增加了一个控制参数 rescore,当其为 1 时,target 取预测框与 ground truth 的真实 IOU 值。对于那些没有与 ground truth 匹配的先验框(与预测框对应),除去那些 Max_IOU 低于阈值的,其它的就全部忽略,不计算任何误差。这点在 YOLOv3 论文中也有相关说明:YOLO 中一个 ground truth 只会与一个先验框匹配(IOU 值最好的),对于那些 IOU 值超过一定阈值的先验框,其预测结果就忽略了。这和 SSD 与 RPN 网络的处理方式有很大不同,因为它们可以将一个 ground truth 分配给多个先验框。
(1)W,H分别指的是特征图(13*13)的宽与高;
(2)A指的是先验框数目(这里是5);
(3)各个λ值是各个loss的权重系数,参考YOLOv1的loss;
(4)第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差;
(5)第二项是计算先验框与预测宽的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状;
(6)第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。
先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。
在计算 obj 置信度时,在 YOLOv1 中 target=1,而 YOLOv2 增加了一个控制参数 rescore,当其为 1 时,target 取预测框与 ground truth 的真实 IOU 值。对于那些没有与 ground truth 匹配的先验框(与预测框对应),除去那些 Max_IOU 低于阈值的,其它的就全部忽略,不计算任何误差。这点在 YOLOv3 论文中也有相关说明:YOLO 中一个 ground truth 只会与一个先验框匹配(IOU 值最好的),对于那些 IOU 值超过一定阈值的先验框,其预测结果就忽略了。这和 SSD 与 RPN 网络的处理方式有很大不同,因为它们可以将一个 ground truth 分配给多个先验框。
尽管YOLOv2和YOLOv1计算loss处理上有不同,但都是采用均方差来计算loss。 另外需要注意的一点是,在计算boxes的和误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale * (2 - truth.w*truth.h),这样对于尺度较小的boxes其权重系数会更大一些,起到和YOLOv1计算平方根相似的效果。
Experiments
Training for Classification
这部分前面有提到,就是训练处理的小trick。 这里的 Training for Classification 都是在 ImageNet 上进行预训练。
YOLOv2 的训练主要包括三个阶段:
第一阶段:在 ImageNet 分类数据集上从头开始预训练 Darknet-19,训练 160 个 epoch。输入图像的大小是 224*224,初始学习率为 0.1。另外在训练的时候采用了标准的数据增加方式比如随机裁剪,旋转以及色度,亮度的调整等。
第二阶段:将网络的输入调整为 448*448,继续在 ImageNet 数据集上 fine-tuning 分类模型,训练 10 个 epoch。参数的除了 epoch 和 learning rate 改变外,其他都没变,这里 learning rate 改为 0.001。
Training for Detection
第三阶段:修改Darknet-19分类模型为检测模型,并在检测数据集上继续fine-tuning网络。
网络修改包括:移除最后一个卷积层、global avgpooling 层以及 softmax 层,新增了三个 332014 卷积层,同时增加了一个 passthrough 层,最后使用 1*1 卷积层输出预测结果。输出通道数计算如下。
**对于 VOC 数据,每个 cell 预测 num=5 个 bounding box,每个 bounding box 有 5 个坐标值和 20 个类别值,所以每个 cell 有 125 个 filter。即:filter_num = num * (classes + 5) = 5 * (20 + 5) = 125 **
注意: (1)这里filter_num的计算和YOLOv1不同,在YOLOv1中filter_num = classes + num * (coords + confidence) = 20 + 2 * (4 + 1) = 30,在YOLOv1中,类别概率是由cell来预测的,一个cell对应的两个box的类别概率是一样的,但是在YOLOv2中,类别概率是属于box的,每个box对应一个类别概率,而不是由cell决定,因此这边每个box对应25个预测值(5个坐标加20个类别值)。 (2)YOLOv2和YOLOv3的计算方式是一致的。
Some Descriptions
参考