You Only Look Once: Unified, Real-Time Object Detection
Links
- PDF Attachments: 2016’You Only Look Once_Redmon et al_.pdf
- Zotero Links: Local library
My Comments and Inspiration
牛,真的牛。
Cores, Contributions and Conclusions
本文最重要的贡献在于提出了一个端到端的单阶段目标识别网络,直接能够通过一次推理获得 bbox 和 bbox 的分类概率。 这其中包含了作者大量的思考以及特别的设计。虽然 YOLO V1 的效果不如 Fast/Faster RCNN,但是综合考虑其实时性和表现,YOLO V1 在当时已经无出其右。
YOLO V1 的优点
- 很快,V1 普通版本 45fps, Fast YOLO 155 fps
- 直接全局推理,避免像二阶段网络一样只能感知 ROI 附近的局部区域
- 泛化性强。譬如在野外数据库上进行训练,在艺术数据集上测试,见过的类预测的结果挺好的。
- crose to fine的框架。
YOLO V1 的缺点
- 由于每个 cell 只会预测一个 class,因此 Grid 的分辨率决定了 yolo 可能很难预测小于这个分辨率的物体
- yolo 对于新的物体或者 aspect ratio 比较特别的物体都预测不好。
- Loss 同样有缺点,因为小 bbox 的小错误预测位移和大 bbox 的小预测错误位移对于损失影响一样。
- 密集物体、小物体的预测效果不好
Motivation
- 当前二阶段,分阶段的作者感觉不好
- 当前的都慢,效果还不好。
Methods
网络设计
YOLO 的设计目标是接受整张图片的输入,并通过一次推理获得网络中的所有 bbox 和对应的分类概率。
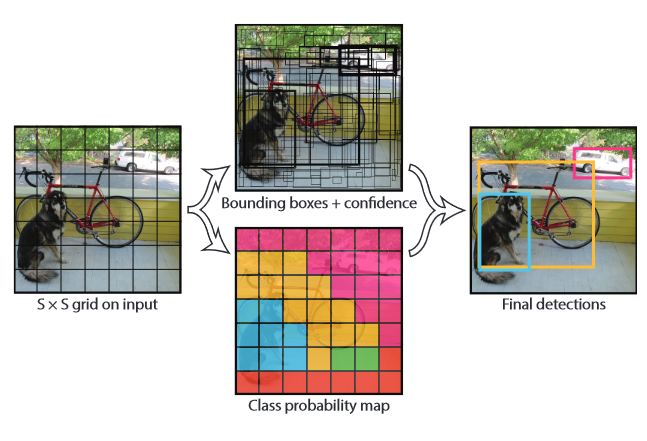
- 输入图像分成 的 Grid,每个区域称为Grid cell
- 对于每个 Grid Cell,网络会输出:
- 个 bbox 的坐标 和每个 bbox 对应的置信度;
该置信度反应了当前bbox含有物体的概率和当前bbox位置的准确程度,表示为。若没有物体在cell中,则,故置信度为0。(关于如何定义”没有物体在当前cell中”,见下)
- 条件类别概率,用来表示当前Cell中在含有物体的条件下的分到某类的概率。
因此,网络的输出是一个 Tensor,其尺寸为
- 个 bbox 的坐标 和每个 bbox 对应的置信度;
一些细节提示
- 步骤 1 和步骤 2 之间就是正常的经过一个 CNN 网络
- 这个 在输入的图像上不会有体现,只会影响最后的 output size
- 每个 Grid cell 只负责检测一个物体,即中心点落在该 cell 中的那个物体。若一个物体覆盖了多个 cell,也只有中心点所在的那个 cell 负责预测该物体,其他的 cell 算作“不含有物体”
- 一个含有物体的 grid cell 只会有一个 bbox 来预测这个物体的位置,剩下的 bbox 的置信度都会在训练中被压成 0,即认为“不含有物体”。
- 对于一个含有物体的cell,怎么决定哪个bbox用来预测该物体?看该cell所有输出的bbox中哪个和对应的truth的IOU最大,就预测哪个(文中称之为 responsible for this object),其余的置信度都被损失压成0。
- bbox的位置中,是相对当前grid cell的中心的位移。同时,是box相对于整幅图像的尺寸,并根据图像的宽和高进行归一化,以让所有的参数范围在(0-1)之间。
- 作者在每个 Cell 中设置的 B 个 bbox 都输出的置信度,理想情况下,当存在物体时,,此时置信度只反应 bbox 位置准不准,即 IOU;反之,置信度为 0。
- 测试时,计算最终的每个 bbox 的置信度得分方法为 显然,yolo中对于每个cell的输出,作者对于两类输出是有明确的分工的。一个专门用来预测该cell中的物体的bbox,另一个只用来判定当前cell中的物体分类,而此物体分类和个bbox没什么关系。
同时,我们能够轻易的知道,有多少个cell,yolo v1 最多预测多少个物体。
网络建模
说完网络的设计思路,下面应该讲一下作者是怎么通过CNN将上面的思路实现的。
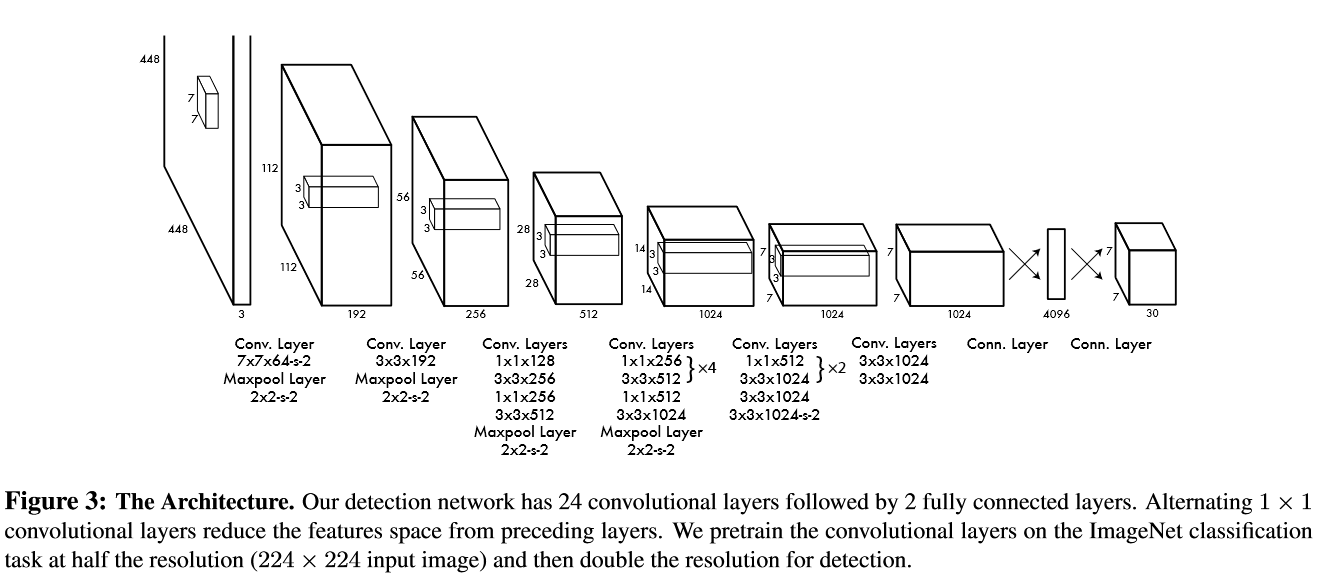
- Inspired by GoogleNet
- 24个卷积层,跟着2个全连接
- 将原 Inception modules 换成 1 × 1 reduction layers followed by 3 × 3 convolutional layers.
PASCAL VOC数据库上一共有20个类,同时本文在该数据库上取,因此,网络的最终输出为。
损失函数
本文中,作者对于所有的输出(bbox的计算,类别的估计)都是采用平方差来计算的loss,作者认为这样方便优化。
同时,作者也考虑到一些特别的设计
- bbox和分类两个损失权重不好分配。如果相等的话,由于太多的cell可能不存在物体,就会导致有关bbox的置信度输出为0,严重影响网络对于有物体的cell的学习能力。
为此,作者增大了计算bbox坐标的loss的权重,并且降低了那些不含有物体的cell计算得到的bbox的置信度loss。使用两个参数 (noobj 是 no object的意思)
- 当偏移量一样时,大的bbox和小的bbox贡献的损失是一样的。然而作者希望在大的bbox中如果pred 和 truth的偏移量较小时,应该对loss的影响小一些。
换句话说,作者觉得预测偏移了多少,要跟bbox的大小有关。比方说同样的偏移了10个pix,如果这个bbox非常大,那么这个预测歪了10个pix就不算什么;但是如果这个bbox就10个pix,结果还预测歪了10个pix,那就很离谱了。
作者通过计算bbox的长宽开方的值的MSE,而不是直接计算w和h的MSE来缓解这种问题(但并没有解决),下图第二行。
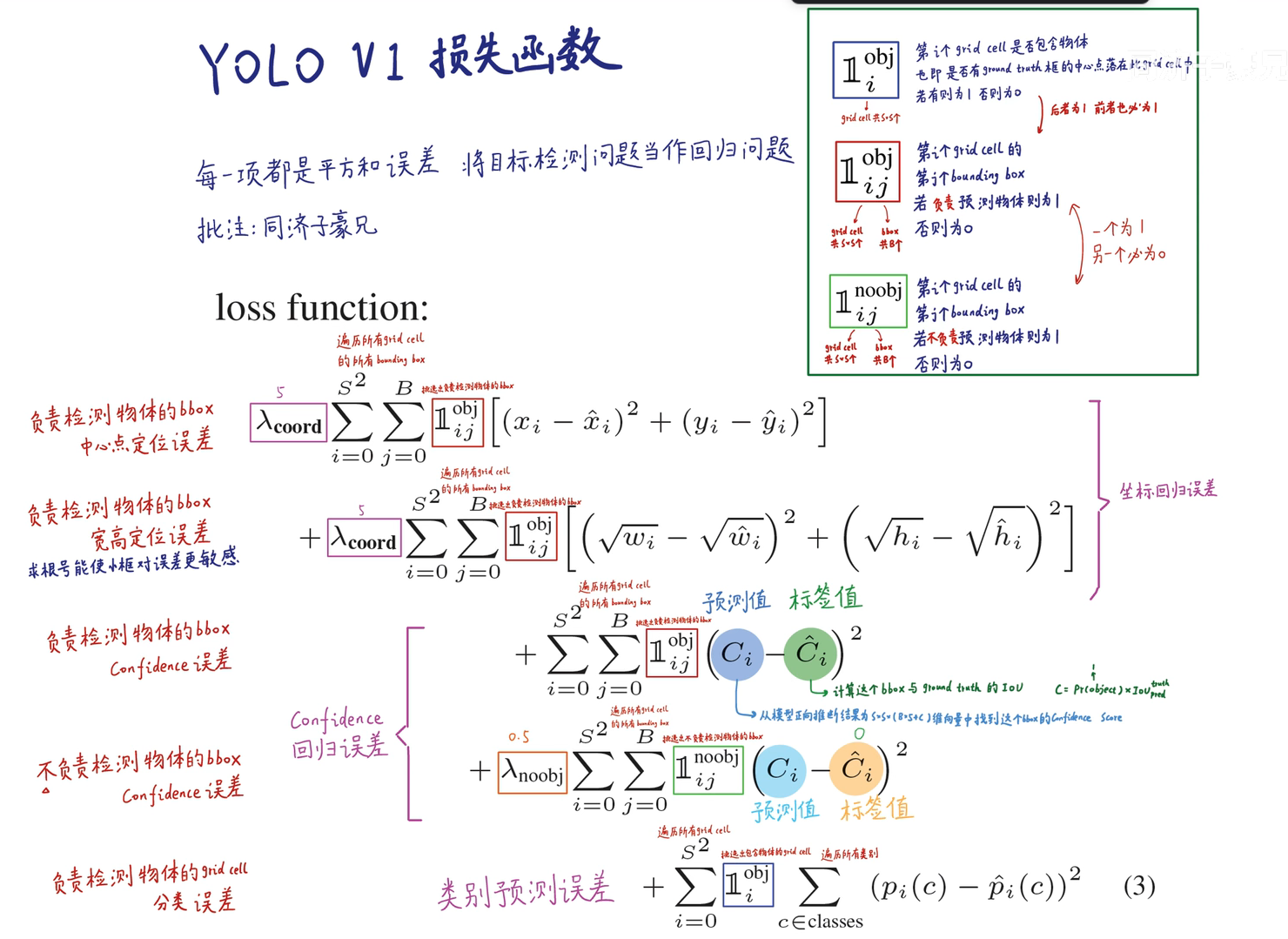
负责检测物体的bbox的误差(第一、二行)
- 只有那些负责检测物体的bbox才会被在这里计算loss
- 相对的,那些 ‘Cell中没有任何物体的中心点所预测的bbox’ 和 ‘该Cell中有物体中心点但是该bbox不负责预测物体’ 的bbox,是不会被用来计算loss的。
- 务必记住,一个有物体的Cell(回忆一下什么是’有物体的Cell’)只能有一个bbox用来预测该物体,剩下的都没用。
bbox confidence误差项(第三、四行)
- 一定是成对出现的
- 用来计算的是 ‘含有物体的Cell’ 预测出来的两个(假设S=2)bbox,其中一个负责预测该物体(和Truth的IOU大的那个,围文中称为’responsible for this object’),送入第二行; 另一个就不会用来预测物体,则送入第三行。
含有物体的cell的分类误差
- 只会计算 ‘含有物体的cell’ 的物体类别预测的loss
- 其他不含有物体的cell,不计算。
Experiments
训练细节
-
Pretrain on ImageNet
-
预训练完后,作者又额外添加了 4 层卷积(位置在哪?)和 2 层全连接,都采用了随机初始化
作者受到[29]启发,添加卷积和全连接能够获得更好的表现。 同时,这一行为导致输入尺寸从变成
-
除了最后一层,其余都是leaky relu激活函数。
-
about 135 epochs on the training and validation data sets from PASCAL VOC 2007 and 2012
-
testing on 2012 we also include the VOC 2007 test data for training.
-
bs=64
-
a momentum of 0.9 and a decay of 0.0005
-
warm up, raise the learning rate from 10−3 to 10−2 on the first epoch
-
training with 10−2 for 75 epochs, then 10−3 for 30 epochs, and finally 10−4 for 30 epochs.
-
A dropout layer with rate = .5
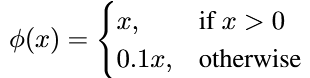
Data augmentation
- random scaling of up to 20% of the original image size
- translations of up to 20% of the original image size.
- randomly adjust the exposure and saturation of the image by up to a factor of 1.5 in the HSV color space.
测试细节
在推理结束后需要先进行NMS
实验结果
-
和Fast RCNN预测的错误类别分析
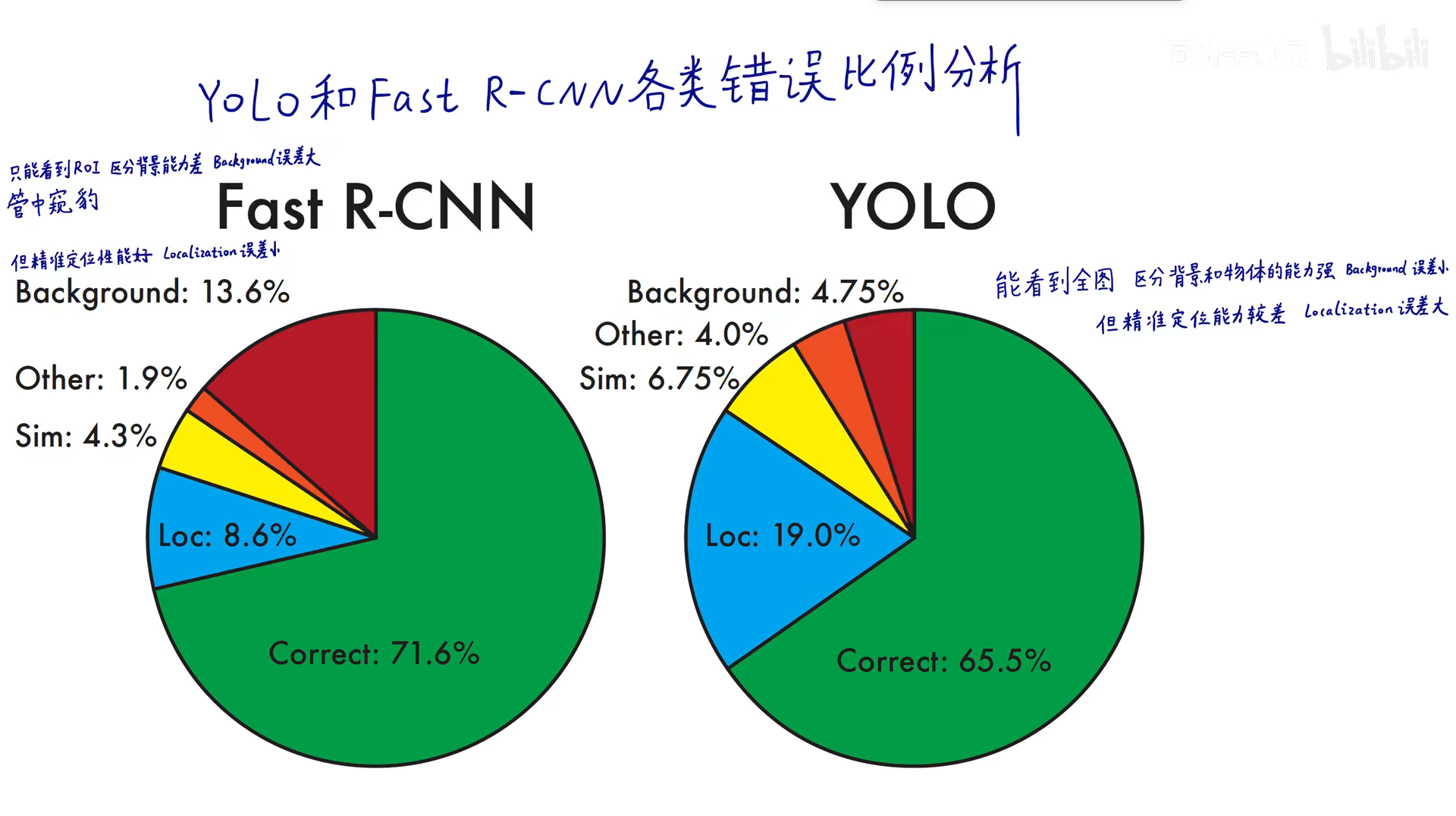
- Yolo 定位能力较差,原因可能是其输入分辨率低,同时作为一阶段网络,干的事情有点多了,鱼和熊掌不可兼得。
- Yolo 对于背景的预测好,原因在于它能够看到全图,对于物体和背景的区分能力较强。
-
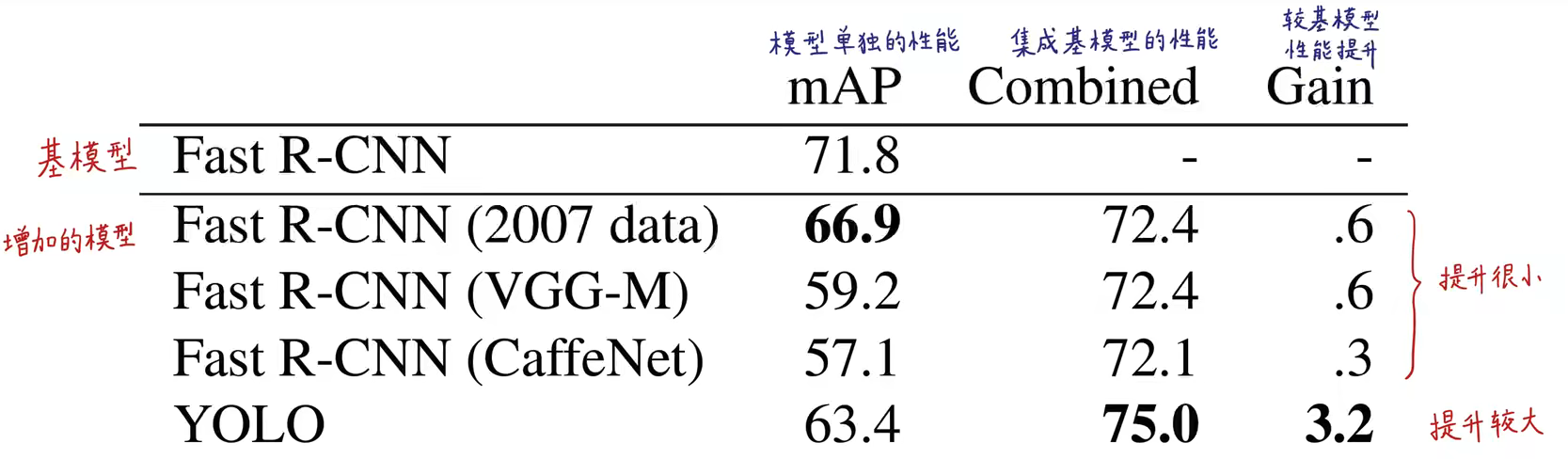
Fast RCNN + YOLO 集成,能获得更好的结果
-
yolo的迁移泛化能力比较强
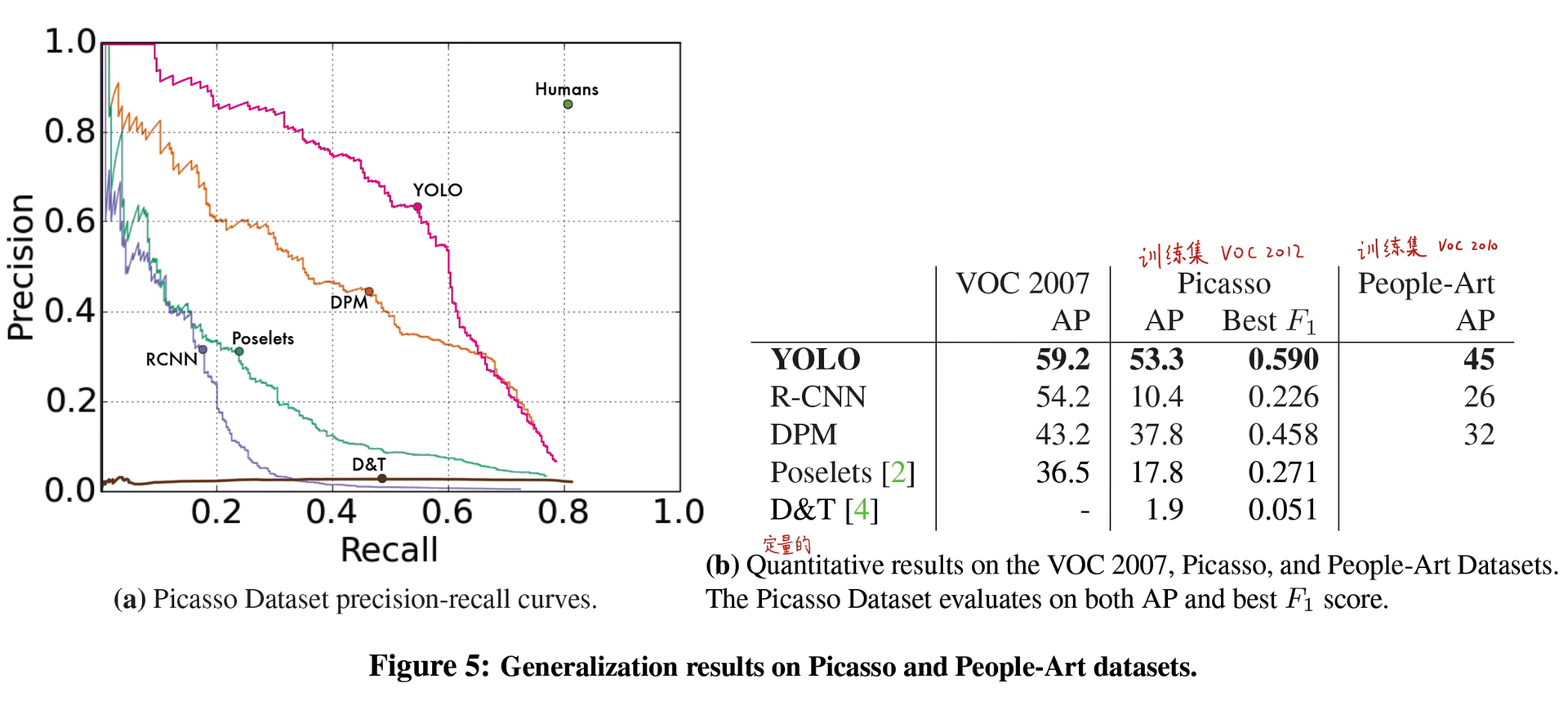
- 都在野外的数据集上进行训练
- 但在不同类型的数据集上进行测试
- 可以看到yolo指标下降的不大。
Some Descriptions
“YOLO still lags behind state-of-the-art detection systems in accuracy.”