On the Relationship between Self-Attention and Convolutional Layers
Links
- PDF Attachments: 2020’On the Relationship between Self-Attention and Convolutional Layers_Cordonnier et al.pdf
- Zotero Links: Local library
- Official codes: GitHub
- Interactive website: Link
My Comments and Inspiration
Preface
随着 attention 在 NLP 领域的大放异彩,其在 CV 领域也开始发力。一些工作尝试将 Self-attention 引入或者替换进 CNN 中,亦或者完全依靠 attention 构建骨干网络。本文中,作者理论上证明了有足够 heads 数的 multi-head self-attention layer 是可以模拟卷积层的操作的,而在实际实验中,他们也确实经常学习到这样的结果。
Conclusions
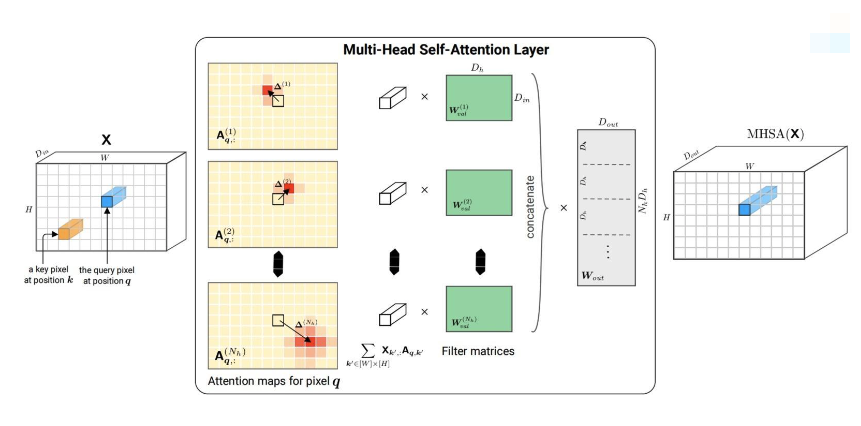
定理 1:给定一个多头自注意力层(Multi-head self-attention layer)满足下列条件: ① 含有 个 heads ②每个 head 的维度是 ③该 MHSA 的输出维度是 ④相对位置编码的维度 。 那么这样的一个多头自注意力层能够模仿任何一个 kernel size 大小为 ,并且输出通道数为 2D卷积层操作
定理 1 与 Conv2D 中一些超参的关系
- Pooling:满足定理 1 的 MHSA 默认使用”SAME”的 padding 模式,即输出的特征图大小会减少 K-1 个像素,为了避免这种情况,可以提前对输入的特征图 padding 个像素
- Stride:定理 1 模拟的卷积 stride 为 1,文中表示加入固定尺寸的 pooling 层即可模拟任意的步长了
- Dilation:可以模拟满足上述条件的,有任意 Dilation value 的卷积。
Proof
严重参考:郑之杰的个人网站
将 MHSA 操作计算写为
上述 是 Attention score,最后一行的方括号表示切片 最后一步我们按照矩阵乘法进行一些变形,其中涉及到的维度分别是 (全部的 ,这里只是一个 block),上式中的 的维度计算一下就知道是
然后我们按照上式进行替换有
则其每一个输出的像素 (位置为[i, j])表示为
表示所有的 key 的位置。
[! Note]-
- 首先明确,每一个输出的位置 q,其对应一个 query,就是输入的对应位置的像素 (token)。那么自然,只考虑一个 query 的情况下,attention map 就可以认为是这个 query 和所有的 key 的相关性,因此有 , 表示输入的像素总数量 (Token sequence),也是 key 的数量(这里 query 数量=key 数量=value 数量)
- 因此, 是一个标量,表示第 q 行的第 k 个元素,物理意义是 query 和第 k 个 key 的相关性
- 是输入特征图,这里我们认为是 reshape 成了 token sequence, 是其第 行。
- 上式中的括号里面,就是对应的权重乘对应的 key embedding,然后求和,得到的结果尺寸自然是
==作者在文中假设,每个 head 限制每个输入的 query 只会关注一个 key (即只会关注到一个像素)==,并且认为这个位置的像素满足条件 。由于输入的一个 query 只会关注到一个 key,则这个只有对应 位置的 attention score = 1,其他都是 0(因为关注不到其他的 key,即最后很 value 加权的时候,不考虑其他的 key 对应的 value,那么就都是 0),即
那么我们将对应的关注位置对应的 attention score 代入进去,则括号里只剩下 q 关注的位置的 token,即
我们与卷积的计算公式进行对比 (q 表示位置,即 (i, j))
可以看出,当每个 head 的注意力计算只关注某一具体位置的像素时, 个 head 的计算与 的卷积核计算是等价的
[! Note] 这里我感觉应该假设 限制关注像素 的位置和某个卷积核关注的位置一样的,且不同 head 之间所关注到的位置应该正好覆盖满卷积核关注的所有位置。 (原文没声明)
Experiments
实验的主要目的在于验证 self-attention 进行类似卷积的操作,以及 self-attention 在实际中是否学习到了类似卷积的属性
实验请看该文章,ICLR 2020|抛开卷积,multi-head self-attention能够表达任何卷积操作 - 知乎 (zhihu.com)
因为涉及到了相对位置编码,我没有记录在这里,也请一并查看上述文章。
如果想了解本文主要研究的相对位置编码,请查看文章 Transformer-XL