Better plain ViT baselines for ImageNet-1k
Links
- PDF Attachments: 2022’Better plain ViT baselines for ImageNet-1k_Beyer et al_.pdf
- Zotero Links: Local library
- Official code: Github
My Comments and Inspiration
在此之前,在 ImageNet-1K 上训练 ViT 的时候,都要复杂的正则化技术来限制模型的自由度,进而让其在该尺度的数据上有一个比较好的表现。作者在本手稿中对其实验设置进行重新的审视和修改,通过采用一些数据增强的方式和一些微小的细节修改,大幅提升了 ViT-S/16 在 ImageNet-1k 上的训练表现。
Cores, Contributions and Conclusions
Cores and Contributions 通过大量实验来验证什么样子的实验设置能够进一步提升 ViT 的表现(实验数据库是 ImageNet-1K)
在 ImageNet-1K 上
- 在 TPUv3-8 上训练 90 个 epoch (7h) 获得了超过 76%的 Top-1 Acc,这已经与 ResNet50 类似了
- 训练 300 epochs (<1d) 能够达到 80% 的 Top-1 Acc。
Preface & Motivation
- ViT 在 ImageNet-1K 上的训练时需要复杂的正则化技术才能保证具有理想的表现
作者发现使用标准的数据增强也足够了,并在本手稿中详细的阐述了相关的实验设置和结果。
Methods
模型就是使用 ViT 文中的 ViT-S/16 模型,不做任何修改,并且只在 ImageNet-1K 上做 (预) 训练和验证。这是因为作者认为 ViT-S/16 模型是一个速度和精度平衡上很好,同时大家都可能会使用的一个模型。
- 作者在原文中提到,当有更多的计算资源和数据时,强烈建议使用 ViT-B/32 或者 ViT-B/16
- Note that increasing patch-size is almost equivalent to reducing image resolution
Experiments
Settings
Data augmentation:
- inception crop” [13] at 224px² resolution
- random horizontal flips
- RandAugment (level 10)
- Mixup augmentations (p=0.2)
Others:
- 2D sin-cos position embeddings
- Batch size = 1024
- 使用 global average pooling 而不是 [cls] token
- Head 是 MLP 而不是 Linear
Results
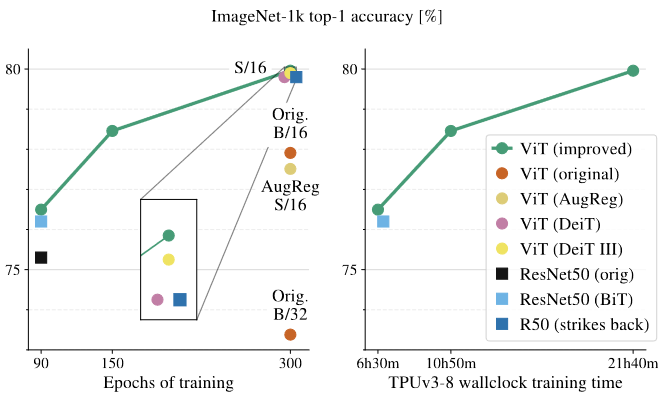
- 左图展示了结果和 Epochs 的关系,可以看到当训练到 90epochs 时,本文设置下的 ViT 效果已经优于 ResNet50 了,在 300epochs 下,同样。
[! thinking]- 这不是说明通过某些特殊的实验设置,可以更快的让 Transformer 获取到 inductive bias? 那么在更小的数据库上,会不会这种实验设置更加的挑剔? 具体来说,能把这些实验设置分类吗? 哪些类型的设置能够让 Transformer 更快地学习到 Inductive bias?
- 右侧显示训练时间和表现的关系,同样的训练时间下,本设置的 ViT 表现和 ResNet50 稍好一点。
各种实验设置的消融实验
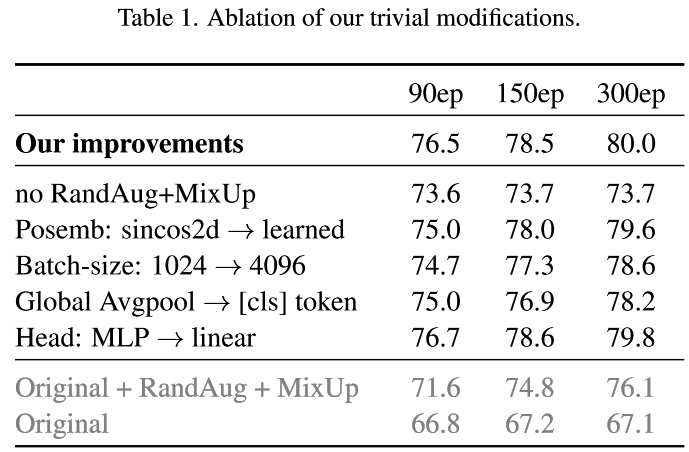
- RandAug + MixUp 的数据增效效果十分显著
- 使用 Linear 或者是 MLP 的 Head 影响微乎其微
- Position embedding 从最终结果看似乎影响也并不是很大,在前期可能会有较大的影响,这种影响会随着训练的进一步进行而降低。
- 不使用 cls token 而使用 GAP 能够提升表现
[! question] 问题
- Position embedding 采用学习的方案效果没有那么理想,这对于任何一个合理的 fixed position embedding 都是这样吗?能否找到更多的实验或者文献支撑?整体看下来,好的 position embedding 可能会加速训练过程,但是当全部收敛时,影响并不是时分明显
- 为何 Batch size 影响感觉也这么大?batch size 越小越好?怎么解释,有 batch size 的下限吗
- GAP 比 cls token 表现好能说明什么?能不能说明数据量有限的情况,cls token 效果有限,当数据量超大时,两者孰优孰劣?为什么 GAP 比 cls token 的效果要好?这和数据量有关吗
- GAP 替换 cls token 怎么操作?
Some Descriptions
- “It is always worth striving for simplicity.”
- “Surprisingly, we find this is not the case and standard data augmentation is sufficient.”