YOLOv3: An Incremental Improvement
Links
- PDF Attachments: 2018’YOLOv3_Redmon,Farhadi_.pdf
- Zotero Links: Local library
My Comments and Inspiration
Cores, Contributions and Conclusions
对 yolo v2 继续添加一些小的改进,这些改进进一步提升了 yolo 的表现,但是并无很大的创新点
- performance drops significantly as the IOU threshold increases indicating YOLOv3 struggles to get the boxes perfectly aligned with the object.
- With new multi-scale predictions we see YOLOv3 has relatively better performance on small obejcts.
- Yolo v3, faster and better.
Something the author tried but didn’t work
- Focal loss.
- Anchor box x, y offset predictions.
- Linear x, y predictions instead of logistic.
- Dual IOU thresholds and truth assignment (a similar strategy with Faster RCNN).
Motivation
Just want make yolo better.
Methods
- YOLOv3 predicts an objectness score for each bounding
box using logistic regression, and each predicted bbox has an objectness score.
Differernt yolo v1 that each cell has an objectness score.
- 只有和GT的IOU是最大的那个anchor的Objectiveness score为1,其余的都为0
- 注意每个anchor都会有对应的预测框,但是如果一个cell中的某个anchor不是最佳的,但是IOU with GT超过了某一个阈值(0.5 in this work),这个对应的预测框会被忽略,不会用于计算损失
- 每个 GT 只会最终选择一个 anchor 的预测框来计算 loss,其他同 cell 的 anchor 不会用于回归 bbox 坐标和分类损失,只会计算 objection score(为 0).
-
Class Prediction
- 每个 bbox 用 logistic classifiers 来预测类别,并用 sigmoid 来压到 0-1 之间,即预测出来的结果不一定和为 1。作者假设的是每个物体是 multilabel 的
这是因为在开放的数据库中,可能有的物体属于两类,如人和女人,并且作者也发现用 softmax 会导致表现不佳。
- 每个 bbox 用 logistic classifiers 来预测类别,并用 sigmoid 来压到 0-1 之间,即预测出来的结果不一定和为 1。作者假设的是每个物体是 multilabel 的
-
多尺度预测 类似 FPN,yolo v3 在三个尺度上进行特征提取和预测。 实际上除了最后一个Feature map 上正常预测,其他两个尺度都是在之前的两个Feature map做2x上采样后在预测。
“In our experiments with COCO [10] we predict 3 boxes at each scale so the tensor is N × N × [3 ∗ (4 + 1 + 80)] for the 4 bounding box offsets, 1 objectness prediction, and 80 class predictions.”
-
更深的 backbone-Darknet 53 去掉所有的 maxpooling,使用步长为 2 的 Conv 完成下采样 添加跨层链接
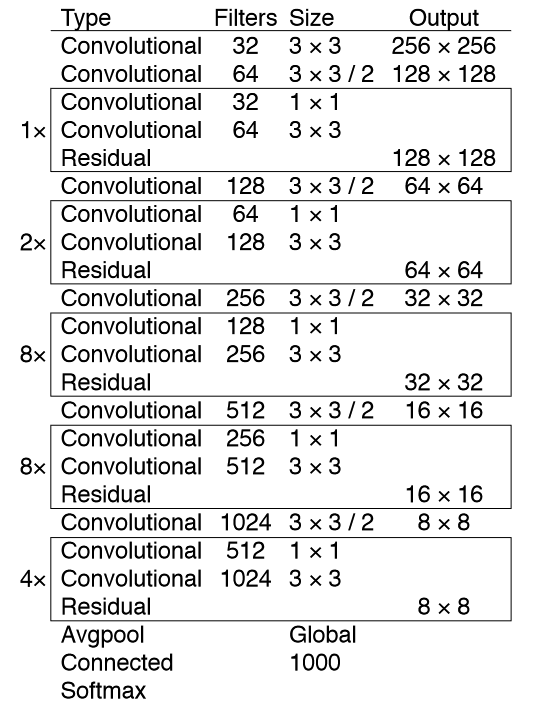
比 ResNet 152 快 2 倍,但是效果差不多 每秒的浮点运算数多,意味着对GPU的利用更好。
Experiments
Training
- No hard negative mining
- Multi-scale training
- 其他同[14]