An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Links
- PDF Attachments: 2021’An Image is Worth 16x16 Words_Dosovitskiy et al_.pdf
- Zotero Links: Local library
My Comments and Inspiration
- Transformer 在小数据集上的表现不好,原因是 Transformer 并没有 CNN 中的 inductive bias,而为了弥补这个差距,需要在大数据集上进行训练。
- 本文采用的是 naive 的 Transformer,希望能够以最少的改动(with the fewest possible modifications)将 Transformer 应用于 CV 上。
Cores, Contributions and Conclusions
Cores:
- 以最少的改动将 Transformer 应用于 CV 上
- 图像切 patch 后直接暴力拉伸
- 引入 position embedding 保留空间信息,以及引入 class token 作为分类用的 vector(或许可以视为 feature?) Contribution:
- 第一次以最少的改动将 Transformer 成功地应用于 CV 上,并取得了很好的结果。
- 此外,指出未来Transformer的发展前景,实验中给出了大量有效并且可靠的Transformer的性质的实验探讨。
Conclusion: 这里只列出部分重要的实验结论,其他更多的实验结论参考原文。
- 差不多参数量的 ResNet 和 ViT,在中等的数据库上(i. e., ImageNet),ViT 的效果会差一点。原因是 ViT 中缺少 inductive bias。相反的,在大数据库上(ImageNet-21k dataset or the in-house JFT-300M dataset)的表现,ViT 要比 ResNet 好。
- 由于缺少Inductive bias,ViT需要大量的数据来学习弥补这个缺陷。(We find that large scale training trumps inductive bias.)
ViT 的特点,同样是 Transformer 的特点
- 可以接受任意长度的 sequence 输入,仅受限于显存
- ViT的输入序列长度受到patch的大小影响,patch越小则序列长度越长,这会导致更大的计算量
Motivation
- 纵观 NLP 领域,随着模型和数据量的增大,Transformer 的表现并没有趋于饱和的情况,这给了作者将其在 CV 上进行进一步探索的动力。
- 彼时,虽然CV中有了一些引入了self-attention的工作,但是大部分都是将部分模块替换成self-attention模块。这类模型虽然高效,但是由于混合结构和特殊的注意力模块的存在,并不能很好的在硬件上进行加速。
Intro & Review
Methods
本作的核心是:以最小的改动,将 Transformer 应用到 CV 上
关于 Transformer 的一些预备知识:
- Transformer 中所有的 latent vector 的长度都是
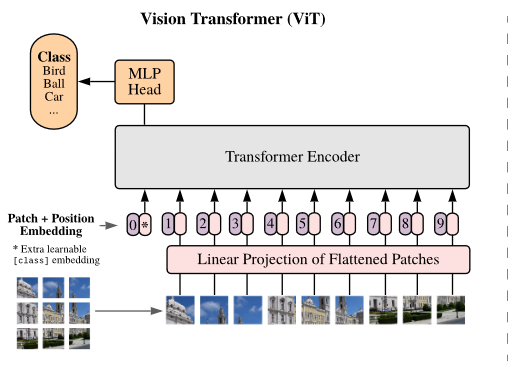
在尽量少改动 Transformer 的前提下,主要就是对图像数据进行处理,主要的流程为
- 对图像 切 patch,并将每个 patch 拉伸 (flatten) 成一维的向量, 。其中, 表示 patch 的边长, 表示 patch 的个数
- 对每个 , 首先经过一个 MLP 使其变成长度为 D 的 embedding,即
- 引入 class token ()以及表示 patch 空间位置的 posing embedding (),构建 Transformer 的第一层输入 ,有 其中,, , 我们上面提到了,是图像中 patch 的个数。
如何构建 class token? class token 初始化为一个可学习的嵌入向量。翻译成人话,在代码中只要初始化成一个可以学习的向量参数即可
self.cls_token = nn.Parameter(torch.randn(1, 1, D))如何构建 pos embedding?
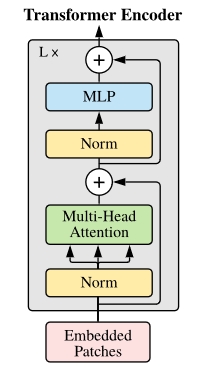
对于 Transformer 中的任意一层,我们有如下 forward function
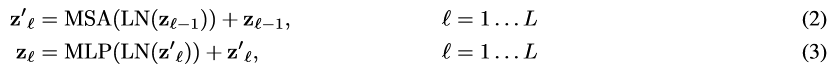 其中 MSA 表示多头注意力模块 (multi head attention), LN 表示 layer norm, MLP 就是全连接层,激活参数使用 GELU
其中 MSA 表示多头注意力模块 (multi head attention), LN 表示 layer norm, MLP 就是全连接层,激活参数使用 GELU
对于最后一层 L 的输出,直接通过一个 LN 得到预测结果
How to pre-train ViT and fine-tune to smaller downstram tasks?
- Remove the pre-trained prediction head
- Attach a zero-initializaed feedforward layer, where K is the number of downstream classes.
How to fine-tune ViT to higher-resolution tasks?
- Keep the patch size the same, resulting in a larger sequence length (in this case, N becomes large).
- Since the pre-trained position embedding fails, 2D interpolation is performed to the pre-trained position embeddings.
Experiments
Setup
Dataset
Model
- ViT 的模型设置

- 其中 ViT-Base 和 ViT-Large 直接从 BERT 里拿的
- 后面跟着数字 /16 表示 ViT 的输入 Patch 大小
-
ResNet 的模型设置
- 将所有的 BN 层换成 GN 层
- 使用 standardized convolutions → 参考, 不是标准卷积
- 标记为 ResNet (BiT)
-
混合模型 (hybrid model)
Traning & Fine-tune
Training
- Adam with
- bs = 4096
- a high weight decay of 0.1, use a linear learning rate warmup and decay
Fine-tuning
- SGD with momentum
- bs = 512
- fine-tune at higher resolution: 512 for ViT-L/16 and 518 for ViT-H/14, and also used averaging with a factor of 0.9999
多大的数据量能够弥补 Transformer 缺少 Inductive bias 的缺点?
- 在 3 个递增的数据库上进行 Pretrain:ImageNet, ImageNet-21K, JFT-300M,然后在下游任务上进行 Finetune
- 采用三个正则化方法:weight decay, dropout, label smoothing
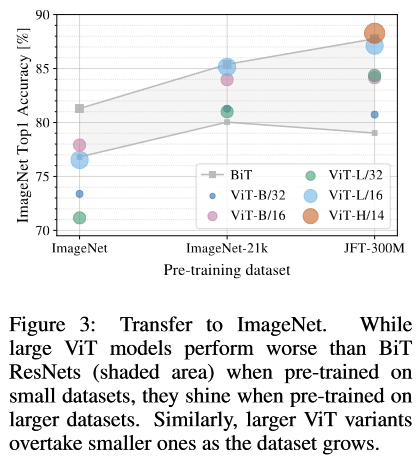
- 利用 JFT-300M 的数据库构建 4 个递增的子数据库:9M, 30M, 90M, Full JFT-300.
- 没有正则化措施,但是超参都是一样的
This way, we assess the intrinsic model properties, and not the effect of regularization.
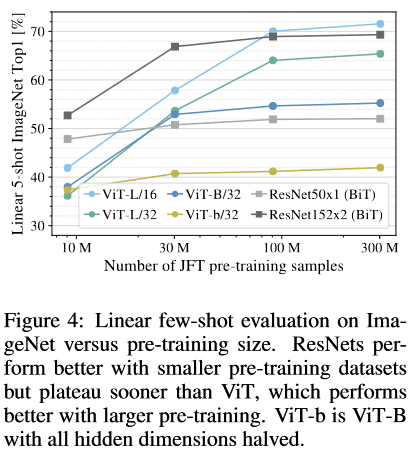
结论:
- 在差不多的计算代价下(comparable computational cost),ViT 相比于 ResNets 更容易在小数据库上过拟合
- 在小的数据库上,CNN 提供的 inductive bias 是十分有效的,此时 ViT 效果会差一些;但是对于大的数据库,ViT 是可以直接从数据中学习到相应的 pattern 的,甚至此时效果会比带有 inductive bias 的 CNN 效果更好。
ViT, CNN 和 Hybrid 模型计算量和表现的关系
- Pretrain on JFT-300M,此时,数据量不是限制模型表现的瓶颈
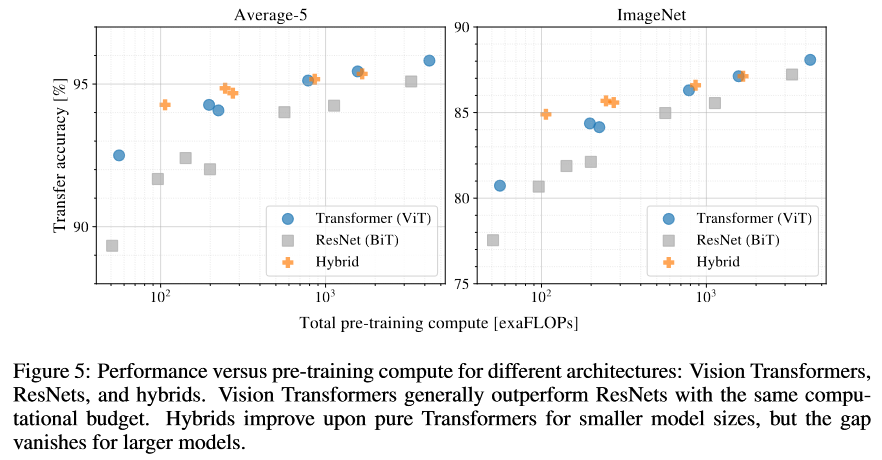
结论
- FLOPs 差不多的时候,ViT 表现比 ResNet 好(注意前提是数据量是足够的)
ViT uses approximately 2 − 4× less compute to attain the same performance (average over 5 datasets).
- 当计算量较小的时候,Hybrid 结构的表现要比 CNN 和 ViT 的好;但是当计算量大到一定程度时,这种差异就会变小甚至消失
This means that convolutional local feature processing to assist ViT at any size.
- ViT 似乎没有在图示的计算量范围内饱和,这也许意味着 ViT 有更多的潜力没有被挖掘出来。(但是似乎从曲线上看,ResNet 也是如此…)
探究 ViT 是如何理解/学习图像的

-
将第一层线性映射层 (即 ) 滤波器的主成分进行可视化(上图左)
[! 结论]- 这些组件有点类似每个 patch 中用于精细化结构低维表示的
The components resemble plausible basis functions for a low-dimensional representation of the fine structure within each patch.)
-
计算不同 patch 的 position embedding 的余弦相似性,并将其可可视化(上图中)
[! 结论]-
- 空间上越近的 patch ,它们的 position embedding 越相似
- 具有明显的 “行-列” 结构:同一行或者同一列的 patch 有相似的 position embedding
-
根据注意力权重计算图像空间中整合的信息的平均距离,并将其根据所在网络深度进行可视化(上图右)
[! 结论]-
- 这里的 attention distance 类似于 CNN 中的感受野
- 在 ViT 的浅层里, attention distance 有小有大,这说明已经有一些 head 在浅层时已经可以关注到全局信息,同时有一些 head 关注局部信息
- 在 ResNet + Transformer 的混合结构的浅层中,那些高度关注局部信息的 head 并不是很重要,这说明它与 CNN 结构中浅层卷积层有着类似的功能(关注局部信息)
- 随着网络的加深,attention distance 也变大,这说明在 ViT 的深层,更多的 head 关注于全局信息的整合。
ViT 在自监督任务上的表现
暂略。