TransFusion: Multi-view Divergent Fusion for Medical Image Segmentation with Transformers
Links
- PDF Attachments: Liu 等 - 2022 - TransFusion Multi-view Divergent Fusion for Medic.pdf
- Zotero Links: Local library
My Comments and Inspiration
- 可以看一看参考文献 16,MCTrans
- 如果视角过多的话,本文对每个视角进行 DiFA 感觉会有很大的计算量和参数量,这里难道是共享参数的吗?没有提供源码,不清楚。如果不是共享参数的,能不能设计一个通用的模块,在保持低参数量和计算量的情况下,得到比较理想的结果?
- 为了降低参数量,本文中所有的 QKV 映射均采用了 Conv. 的方式
- 本文的两个融合方式相对比较简单,主要思考的是如何选择融合时 Attention 的 QKV 来源。
Preface
- 由于多视角图像往往是没有对齐的 (unaligned),因此对多视角图像进行建模和融合仍然是一个开放性的问题
- 本文提出的是多视角、多尺度融合的网络,用于医学图像的分割,其主体结构来自于 UFormer
- 作者认为,在卷积的工作中,直接对未对齐的多视角的图像进行 concat 缺乏精确捕捉不同视角间关系的能力
据此,本文利用强大的注意力机制来捕捉未对齐的多视角图像之间的关系。
Methods
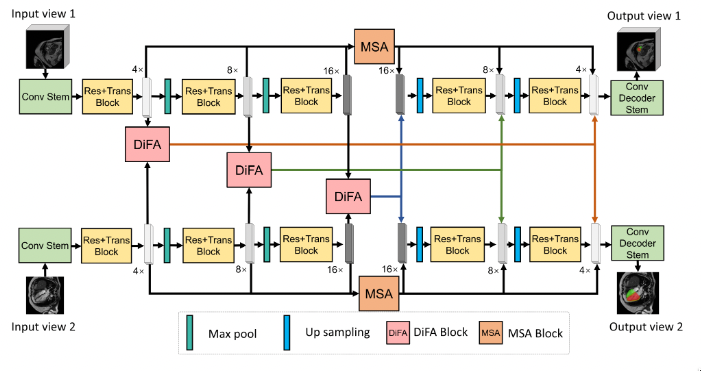 上图是本文的整体框架图,相对来说是比较易懂的。其中两个重要的模块:
上图是本文的整体框架图,相对来说是比较易懂的。其中两个重要的模块:
- Multi-Scale Attention (MSA),融合层级网络结构中不同尺度的输出
- Divergent Fusion Attention (DiFA),捕捉不同视角间的依赖关系。
Divergent Fusion Attention (DiFA)
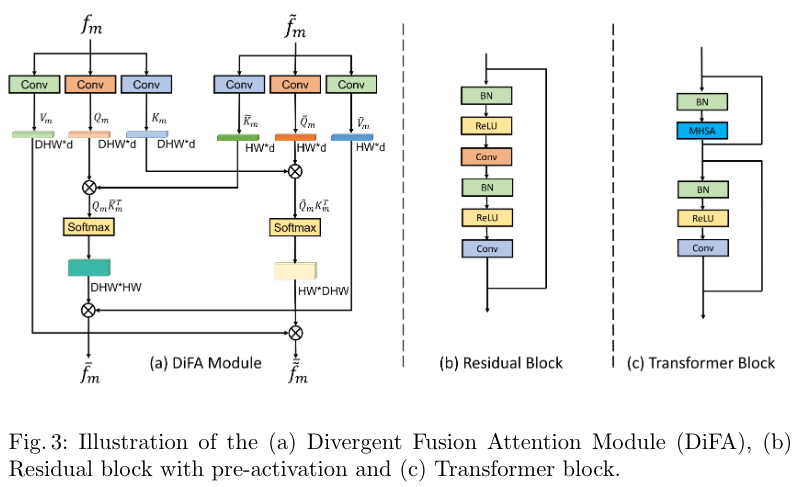
主旨是通过其他的视角来强化当前视角的特征表达能力 :当标视角 tokens , :其他所有视角的 tokens 进行 cat
- 注意 QKV 的映射是使用的 Conv.
- 由于输入的多视角图像是没有对齐的,因此 DiFA 中不使用任何位置编码。
- 对所有视角都进行 DiFA,即逐个认为每个视角为当前视角进行 DiFA
Multi-Scale Attention (MSA)
[! Attention] 不同 level 的 tokens 维度是相同的 (token embedding dimension),但是数量 是不同的,因为进行下采样后,空间的分辨率 (H,W) 都变小了,对应的导致 Token 的数量也变小了。
在本工作的层级结构中,可以分成上采样的层级和下采样的层级,先下采,再上采(类似 UNet),而 MSA 的操作是将同一个视角下的所有下采层级的输出 Token embeddings 进行 cat,然后进行 FFN 和 Attention 的操作,并将此输出切分、分配至对应的上采的层级中(没说是 cat 进去还是 add )
上角标表示下采的层级,下角标表示第 个视角
这里的 Attn 映射取得 QKV 的时候貌似也是采用 Conv. 的方式
which consists of a Multi-Head Self-Attention module and a Feed-forward Network. Following the feature extraction using CNN and Self-Attention, the MSA block is applied to fuse scale divergence.