Transformer in Transformer
Links
- PDF Attachments: 2021’Transformer in Transformer_Han et al.pdf
- Zotero Links: Local library
- Codes: GitHub
My Comments and Inspiration
一句话:通过套娃的方式来捕捉局部和全局的关系。 在未来我们这种套娃的方式也是一种创新点,因为这种创新的动机是非常自然的。
思考
- 究竟能捕捉到”多局部”的信息,还是要取决于 sub-patch 切分的大小,假设输入的图像尺寸变大的话,或许 sub-patch 的尺寸也会变得比较大,此时所关注的信息或许并不够”局部”,难道也要通过套娃的方式实现?又没有更好的方法?
- TNT 的计算量随着输入图像的尺寸变化的速度本质没有变,依然是平方速度增长,我们能不能考虑在捕捉到局部信息的同时,使得整体的计算量增长慢下来?
- TNT 的超参太多了,本来一个 Transformer 的参数量就已经不少了,TNT 这里有两个 Transformer 的参数量,调参应该会非常麻烦。
Cores, Contributions and Conclusions
Cores 对 ViT 进行改进,将 ViT 中的每个图像 Patch 再次切分,引入一个新的 Transformer (Inner-Transformer,实际上是一个新的分支) 来捕捉 inner patch relationship。通过相加的形式加回到原 ViT 的分支上。这样,原始的 Transformer 用来捕捉 patch 之间的关系,inner transformer 用来捕捉 patch 内部的关系
Contributions 通过引入一个 sub-transformer 来捕捉局部的信息。与 ViT 结合后,TNT 具有了同时捕捉全局和局部信息的能力。
Conclusions ?
Motivation
对于 NLP 任务来说,word 是不可再分的最小单位。而在 ViT 的输入数据中,patch 仍然是一个可分的单位。考虑到自然界中的图像多种多样,可能一个 Patch 内部也存在着某些十分重要的相似性。这种相似性由于在 patch 内部,无法被 Transformer 捕捉到,所以作者希望通过该方法,使 TNT 不仅能够捕捉到 Patch 之间的关系 (全局信息),也能捕捉到 Patch 内部之间的关系 (局部信息)
Methods
一些定义: Visual sentence: 类似 ViT 中的每个 Patch Visual word: 上面的每个 Patch 再切分一次,得到的 sub-patch 称为 visual word
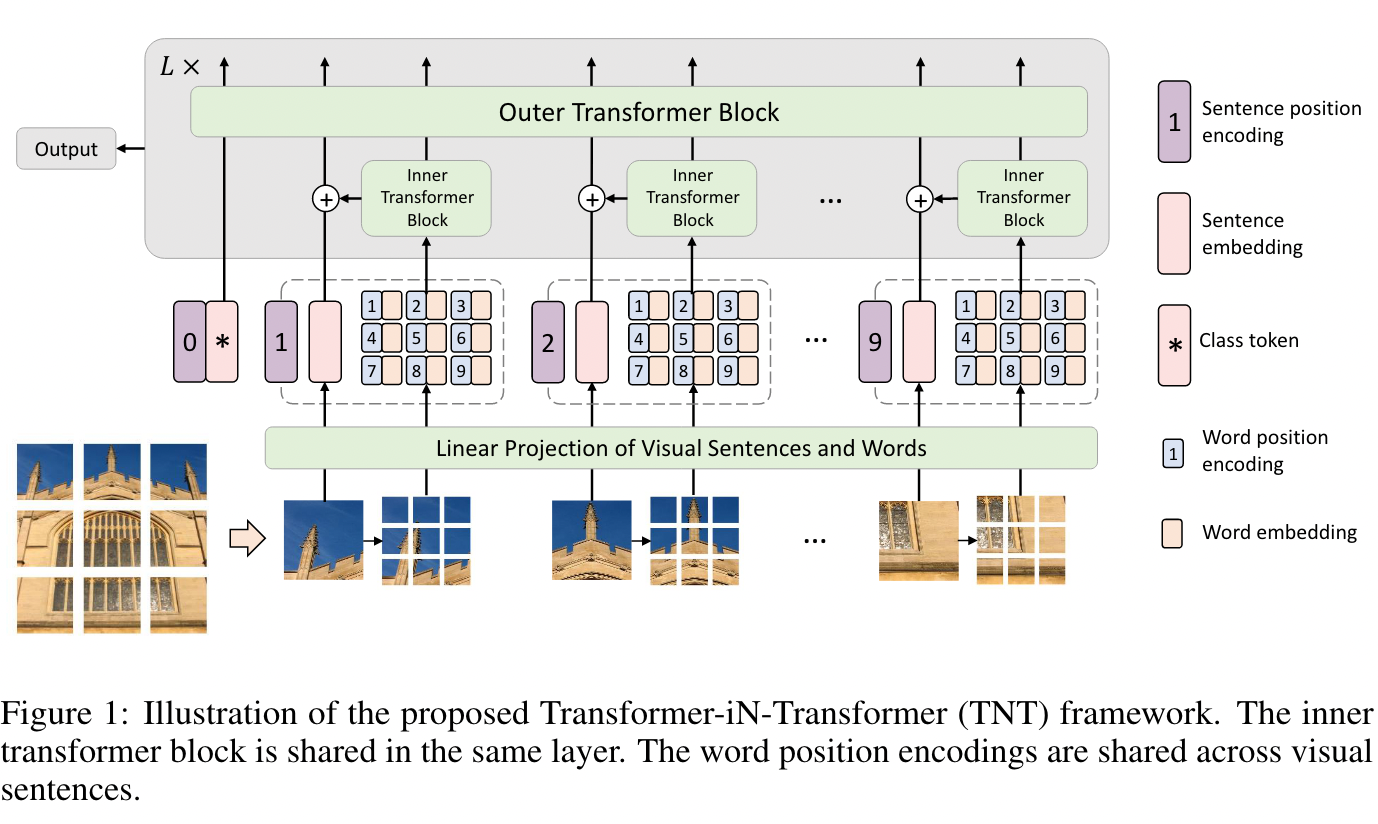
TNT 中一共有两个分支,一个分支用来捕捉 patch 之间的关系 (文中称为 Outer transformer,其实就是 ViT);另一个分支是用来捕捉 Patch 内部 sub-patch 之间的关系 (称为 inner transformer)
Outer transformer 对于 Outer transformer,可以认为就是 ViT 的结构,同样是每个 ViT 中的 Block 进行堆叠
Inner Transformer 分支 对于每个大 Patch (Visual Sentence) ,先切分成 的 sub-patch (visual word),共计 个。
为了方便表述,我们下面的叙述和原文可能不同
- 每个 sub-patch 同样需要经过 MLP 变成 sub-token
- Inner transformer 中没有 cls token,只在 outer-transformer 中的输入有
- Inner-transformer 和 outer-transformer 有相同的 block 数量,两条分支每经过同一层的 block 之后,Inner-transformer 的输出 () 会按照顺序拼接之后,经过一层 MLP 之后与 outer-transformer 的输出 () 相加,作为结合了 Global 和 Local 的 token,此后该特征沿着 outer-transformer 流动
Z_{l-1}^{i}=Z_{l-1}^{i}+F C\left(\operatorname{Vec}\left(Y_{l}^{i}\right)\right)
> 原文中,作者称一个 inner-transformer block 和一个 outer-transformer block 合并称为一个 TNT block。 #### Position embedding > The standard learnable 1D position encodings are utilized here. 注意,这里 visual sentence embedding 和 visual word embedding 都是添加了 position embedding 的。但是其中不同 visual sentence 同一个位置的 visual word 共享同一个 word embedding。 #### 复杂度分析 (FLOPs and \#Params) $r$ 表示 MLP ratio, **FLOPs of a standard transformer block**\mathrm{FLOPs}{T}=2 n d\left(d{k}+d_{v}\right)+n^{2}\left(d_{k}+d_{v}\right)+2 n d d r
当 $r=4$ 时,有\mathrm{FLOPs}_{T}=2 n d(6d+n)
\mathrm{Params}_{T}=12dd
**FLOPs of Inner-Transformer**: $2nmc(6c+m)$ **FLOPs of Outer-Transformer**: $2nd (6d+n)$ **FLPOs of add inner output and outer output**: $nmcd$ ***FLOPs of a TNT block***: $2nmc(6c+m)+nmcd+2nd (6d+n)$ 类似的, **\#Params of a TNT Block**: $12cc+mcd+12dd$ #### 网络结构 - Patch size = $16\times 16$ - Input image resolution = $224\times 224$  ## Experiments #### Implementation detail  #### Image Classification - 该实验设置大部分参考[38], 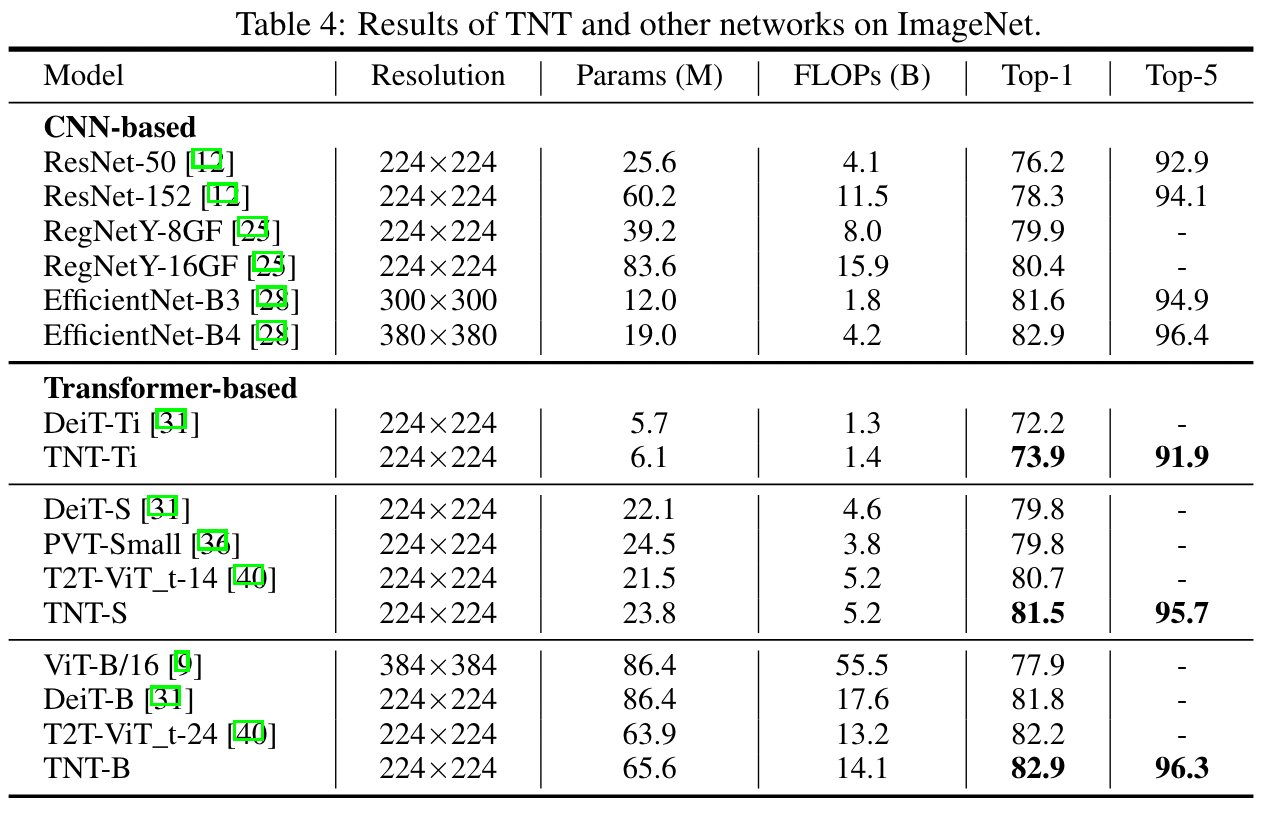 - 可以看到 TNT 并没有超过 Efficient Net 的结果,并且在参数量和计算量都比 Efficient Net 差的情况下,结果也差了一个点,这是为什么? **看一看结果和参数量与计算量的表现** 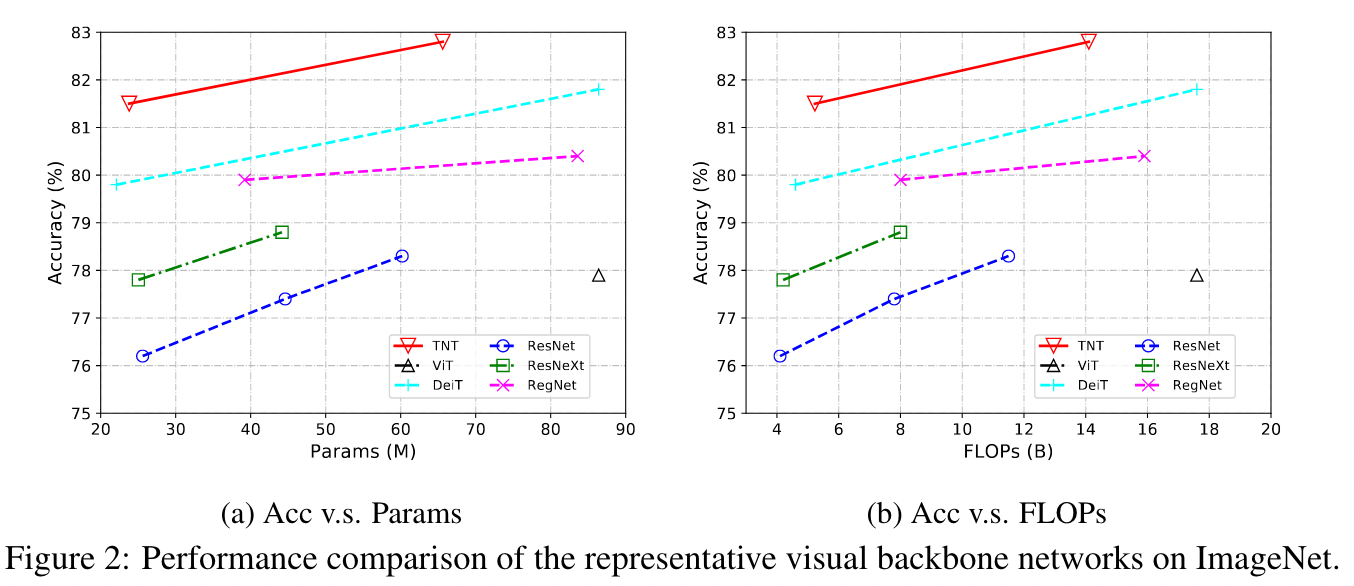 Ps:作者上图中没放 EfficientNet 的结果 作者文中也比较了在单张 V100 上的推理速度 ### 消融实验 **Efficient of position encoding** 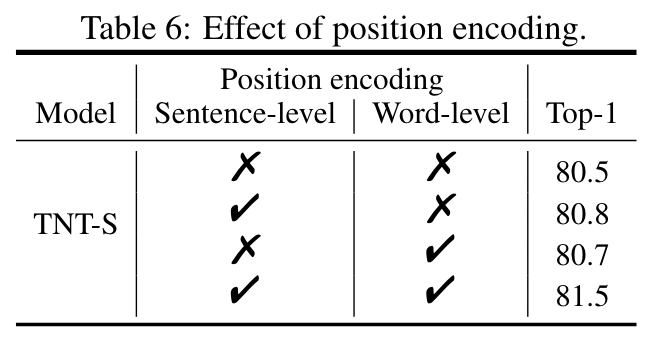 - Word position encoding 和 sentence position encoding 都是有效的 - 两者都用效果最好,不存在谁提升的效果更好,似乎差不多 **Number of heads for inner-transformer** > 作者文中提到,在视觉任务中\#head = 64 是一个比较推荐的设置 ([9, 31]) 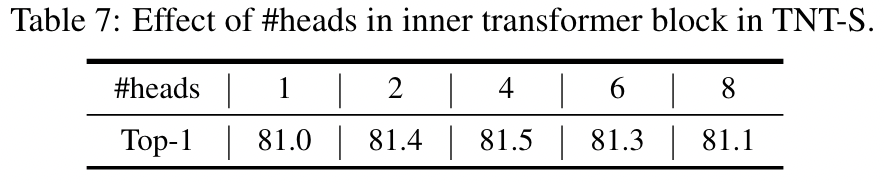 **Number of Visual words in a visual sentence** 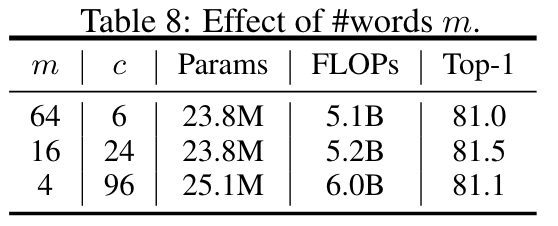 Visual words 的影响不是很大 > [! question]- 为什么 Visual words 的影响不明显? > 我感觉一个合理的情况是随着 words 的数量增加,其捕捉的局部信息越丰富,应该具有更好的结果。但是实际情况并不是这样。 > 可能的猜测 > 1. 基于 Transformer 捕捉到的局部信息提升的效果有限,遇到了瓶颈 > 2. 作者的设置故意限制了他们具有同等的 FLOPs ,这限制了局部信息的捕捉 ### 可视化实验(这部分还挺有趣的,但是我感觉我暂时品不出什么,先不记了) #### Feature map 可视化 #### Attention map 可视化 ## Some Descriptions