SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images
Links
- PDF Attachments: 2022’SwinFuse_Wang et al.pdf
- Zotero Links: Local library
My Comments and Inspiration
本文是第一个纯 Transformer 的架构用于近红外和可见光图像融合的工作,但是融合部分设计的动机不清晰,没有太大的参考价值。不知道为什么使用 1 范数
Preface
- 本文的任务是将近红外图像和可见光图像进行融合
- 融合的关键是如何提取和融合他们的互补信息
动机:卷积捕捉不到全集信息,作者认为只使用卷积进行融合,由于卷积的局部性,导致它们是 content-independent 的,融合时并不高效
Methods
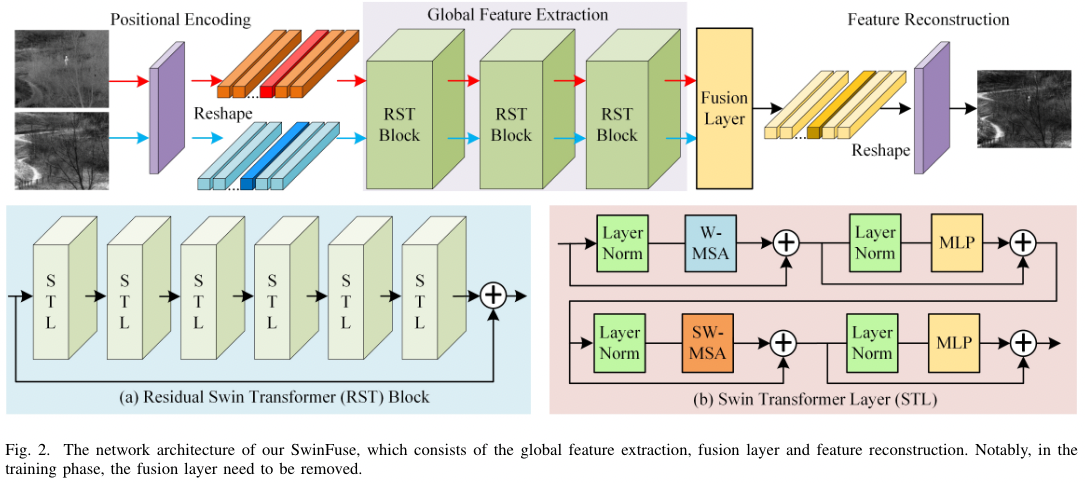
有点类似双流
- 每个模态首先经过一个 1x1 的卷积层来实施 positional encoding,此时输出的通道数为 96 (就是过一层 1x1 的卷积而已,只不过作者说“the convolution layer is an effective way for positional encoding, and transform an image space into a high-dimensional feature space”)
- 将特征图 flatten 之后送入若干个 residual Swin Transformer blocks (RSTBs) 中提取全局特征。这里可以直接看上图,就是直接应用了 SwinTrans 中的 Block,但是值得注意的是,它的 Residualy 有点多,STL 中有,RST 中也有,可以认为是内部和外部各有自己的 Residual,它是在 Attention 的过程中添加的 pos embed (下图).
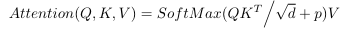
- 基于 L1-Norm 进行行、列向量的融合。
- Reshape 回空间特征图后,经过一个卷积层进行融合即可(也可能是几个卷积层,不重要) 如何融合
[! Note] 这里作者没啥动机,直接莽的,感觉参考性不是很大。
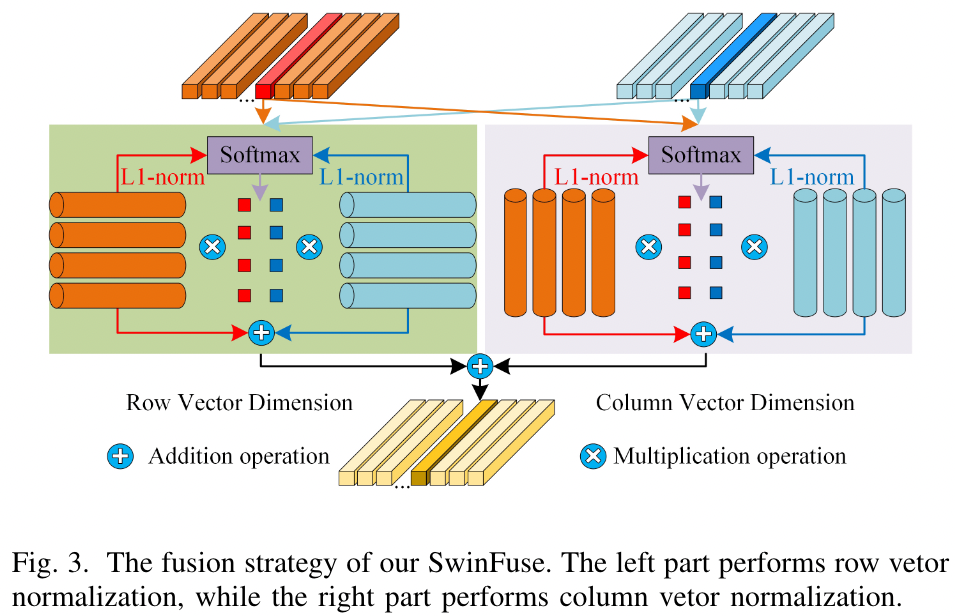
首先,这里的融合分成 Row fusion 和 Column Fusion 对于从 RSTBs 输出的两个模态 (总体图中的红线和蓝线) 的 Token sequence,记为 和
-
先按照行计算不同模态每行的权重

 i 表示第 i 行
i 表示第 i 行 -
再按照列计算不同模态没列的权重,计算方法类似
 j 表示 Token sequence 中的第 j 列
j 表示 Token sequence 中的第 j 列 -
分别按照行和列的权重对自己原来的特征的行和列进行加权

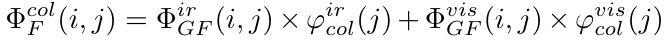
-
最后将两个分别按照行列进行加权的特征图想加
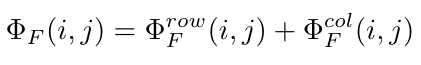
[! Question] 可能存在的问题和我的疑问
- 为啥使用 1 范数?
- 对一个 Token Sequence 进行行列的权重求解,有什么意义?他的每行认为是一个 token embedding,每列表示什么?有这么按列操作的工作吗?
- 能认为是注意力吗?对行列又施加了一次注意力,但是合理吗?