Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Links
- PDF Attachments: 2014’Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition_He et al_.pdf
- Zotero Links: Local library
My Comments and Inspiration
-
作者认为图像的 scale 是重要的性质,改变这个 scale 会导致里面特征的畸变(non scale-invariant)。为了证明这个论点,作者举了 SIFT 特征的例子
The scales play important roles in traditional methods, e. g., the SIFT vectors are often extracted at multiple scales [29], [27] (determined by the sizes of the patches and Gaussian filters). (He 等。, 2014, p. 4)
-
SPP layer 本质上是一个池化层,常常放在FC层前面一层
Cores, Contributions and Conclusions
本文借鉴 SPP1 (Spatial pyramid pooling, popularly known as spatial pyramid matching or SPM) 的思想,提出了 SPP layer,使得网络接受任意大小的图像输入(实际上有最小尺寸,不能不够 conv 的),经过 SPP layer 后出输出固定尺寸的输出。
- 网络接受固定尺寸的图像,原因在于 FC 的输入尺寸固定。实际上,卷积层是可以接受任意大小的输入的。
- 本文 SPP 的三大优点
- SPP可以对不同维度输入得到固定长度输出.
- SPP使用了多维的spatial bins(可能就是多个不同大小的窗),而滑动窗池化只用了一个窗
- 由于可以输入任意尺寸的图像,SPP能够提取基于不同尺度图像提取的特征
Motivation
目前的 CNN 都只能接受固定尺寸的输入图像,因此很多不同尺寸的图片会通过 crop 或者 warp 的方式来得到对应尺寸的图像,这一行为有如下的缺点
- The cropped region may not contain the entire object, while the warped content may result in unwanted geometric distortion.
- Recognition accuracy can be compromised due to the content loss or distortion.
- A pre-defined scale may not be suitable when object scales vary.
Methods
SPP layer 介绍图
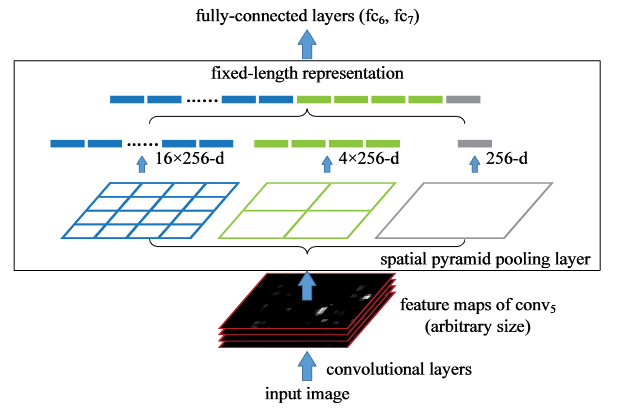
上图中的 256 是 filters 的个数,即输入特征图的 channel 数
流程
- 输入一个 C*H*W 特征图
- 将特征图均匀的分成份(对应文中的bins),在每个bin中(实际上理解成patch更好)做max pooling
- 多取几个 , 上图中取了 3 个 (n=1, 2, 4),即不同的尺度(pyramid)
- 将不同尺度的输出拼成一维向量(实际上是每个patch变成了一维向量,把所有的patch输出拼起来而已,听不懂看图)
SSP for Objection Detection
流程2
- 把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps;
- 然后在feature maps中找到各个候选框对应的区域;
- 再对各个候选框对应的 feature maps 区域采用金字塔空间池化(SSP),提取出固定长度的特征向量。
- 和RCNN一样,训练过程仍然是隔离的,提取候选框 | 计算CNN特征| SVM分类 | Bounding Box回归独立训练,大量的中间结果需要转存,无法整体训练参数
- SPP-Net 在无法同时 Tuning 在 SPP-Layer 两边的卷积层和全连接层,很大程度上限制了深度 CNN 的效果
物体检测中 SPP-Net 很难做反向传播,至少说很难对 SPPooling 层之前的进行传播。 原因在于 SPPNet 的 batch 采样是在所有图像的所有 ROI 中均匀采样的,也就是一个 batch 里会有很多张图像的 ROI(注意 SPPNet 依然采用的是 SS 来找 Proposals)。为了能够进行反传,需要保存每个图像的 feature map,这是一个损耗很大的操作。因此说很难进行反传(但并不是不可以) 和Fast RCNN相比,Fast RCNN是在两张图像上采ROI构成batch,反传的代价会很小,因此可以正常进行反传。
如何在 feature maps 中找到原始图片中候选框的对应区域
其实就是计算感受野大小的计算。
: 图上的像素点坐标
: Feature map 上对应的坐标
转换关系: , , S 表示至此为止前面的 CNN 中所有的步长(strides)的乘积
Experiments
Some Descriptions
- “Fixing input sizes overlooks the issues involving scales.”
- “XX has better or comparable accuracy.”
- “The advantages of SPP are orthogonal to the specific CNN designs.”
- “The last two layers are fully connected, with an N-way softmax as the output, where N is the number of categories.”
Footnotes
-
SPP 是一个早就有的技术,并且和 BoW 一起使用,原文中介绍说“Such vectors can be generated by the Bag-of-Words (BoW) approach [16] that pools the features together. Spatial pyramid pooling [14], [15] improves BoW in that it can maintain spatial information by pooling in local spatial bins.” (He 等。, 2014, p. 3) ↩
-
[论文笔记]Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition_weixin_41065383的博客-CSDN博客 ↩