Selective Kernel Networks
 本文通过网络自适应的学习不同感受野分支的重要性,结合通道注意力对不同的感受野获取到的信息进行融合。
本文通过网络自适应的学习不同感受野分支的重要性,结合通道注意力对不同的感受野获取到的信息进行融合。
Links
- PDF Attachments: 2019’Selective Kernel Networks_Li et al_.pdf
- Zotero Links: Local library
My Comments and Inspiration
- 这是一个“受限”的选择过程,其考虑的感受野大小只能从预设的分支里选,通过赋予不同的权重获取不同尺度的感受野信息。
- 实验做得非常有意思,探讨了输入图像中感兴趣区域的大小与感受野大小的有效性关联。
- 属于 branch attention,勉强能看到channel attention的影子
Cores, Contributions and Conclusions
Cores: 自适应融合不同感受野的信息,关键是如何获取不同感受野的信息的重要性,这一步参考了SENet
Contribution: 提出了一种 InceptionBlock with channel attention 的模块,该模块能够自适应的融合不同尺度卷积核的信息
Conclusions
- 输入图像中的感兴趣物体越大,使用更大感受野的卷积核抽取的有效信息更多(但这并不意味着小感受野的核抽取的信息一点用没有)。
- 在网络的深层,图像中物体的尺度信息已经没有了,不同感受野的卷积核抽取的信息基本一样。这意味着这种物体的尺度信息可能已经丢失,或者已经融合在了特征里。
前言
一些文章揭示了大脑皮层的神经元对于视觉中同一区域的位置感受野是不同的,而 InceptionNet 就很好的模拟了这一情况。但是,也有另一些工作指出,神经元的感受野并不是固定的。其感受野的大小是受到的刺激而变化的,即动态的(自适应的),而这种现象目前并没有受到关注。
显然本文希望能够模拟"动态感受野"这一过程
Methods
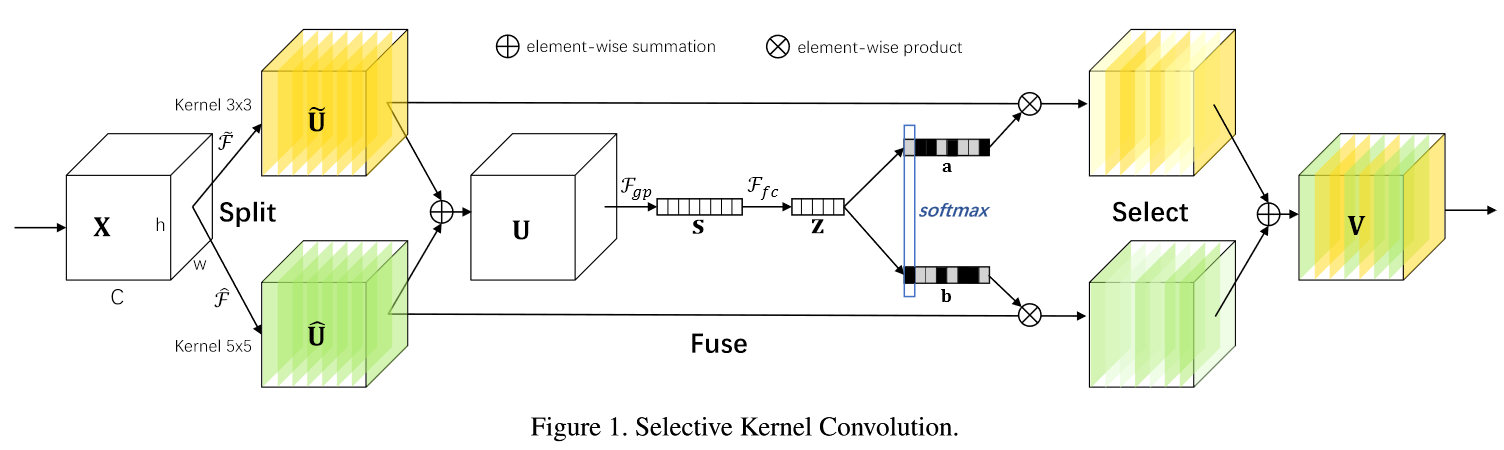
整个SK Conv. 分成三步:Split, Fuse, and Select.
下图展示了两种kernel size的自适应选择(branch_num=2)。

Split stage 将输入 分别经过 和 的卷积模块 (Grouped or Depthwise Conv.+BN+ReLU) 得到 和 (尺寸都不变)
- 这里用两个分支举例(如图示),实际上可以用更多不同尺寸的卷积核做为更多的分支
- 注意卷积不是普通的卷积
- 作者提到,若追求更高效,5x5卷积可以3x3的膨胀卷积,dilation size = 2
Fuse satge 将两个分支的特征图 和 相加得到 ,沿着 维度对 U 做 GAP (全局平均池化) 得到 channel-wise statistics
对 做全连接,获取其潜在的信息,用于获得注意力矩阵,并指导后续的select stage.
- 如何确定 : . 是预设的 的最小值,本文中为 32, 称为 reduction ratio (类似SENet)
Select stage 在这步中,我们需要用 获得软注意力向量,分别与输入的分支相乘(有点类似 SENet 最后那里)。 进一步,我们将 进行 reshape 成一个矩阵, 对于 att_matrix,沿着列做 softmax 操作(保证不同的 branch 的同一个 channel 对应的 attention score 相加为 1)
最后就是将att_matrix每一行与对应的branch做对应元素相乘,最后加到一起得到最终的输出
作者文中并未清晰的解释文中A,B矩阵怎么获得的。这里看了timm包的实现,直接按照timm的实现进行解释。同时,为了便于理解,笔记里的符号和文中完全不同。
感觉branch_num很多的时候,得到 t 的时候会增加很多的参数?
Network structure
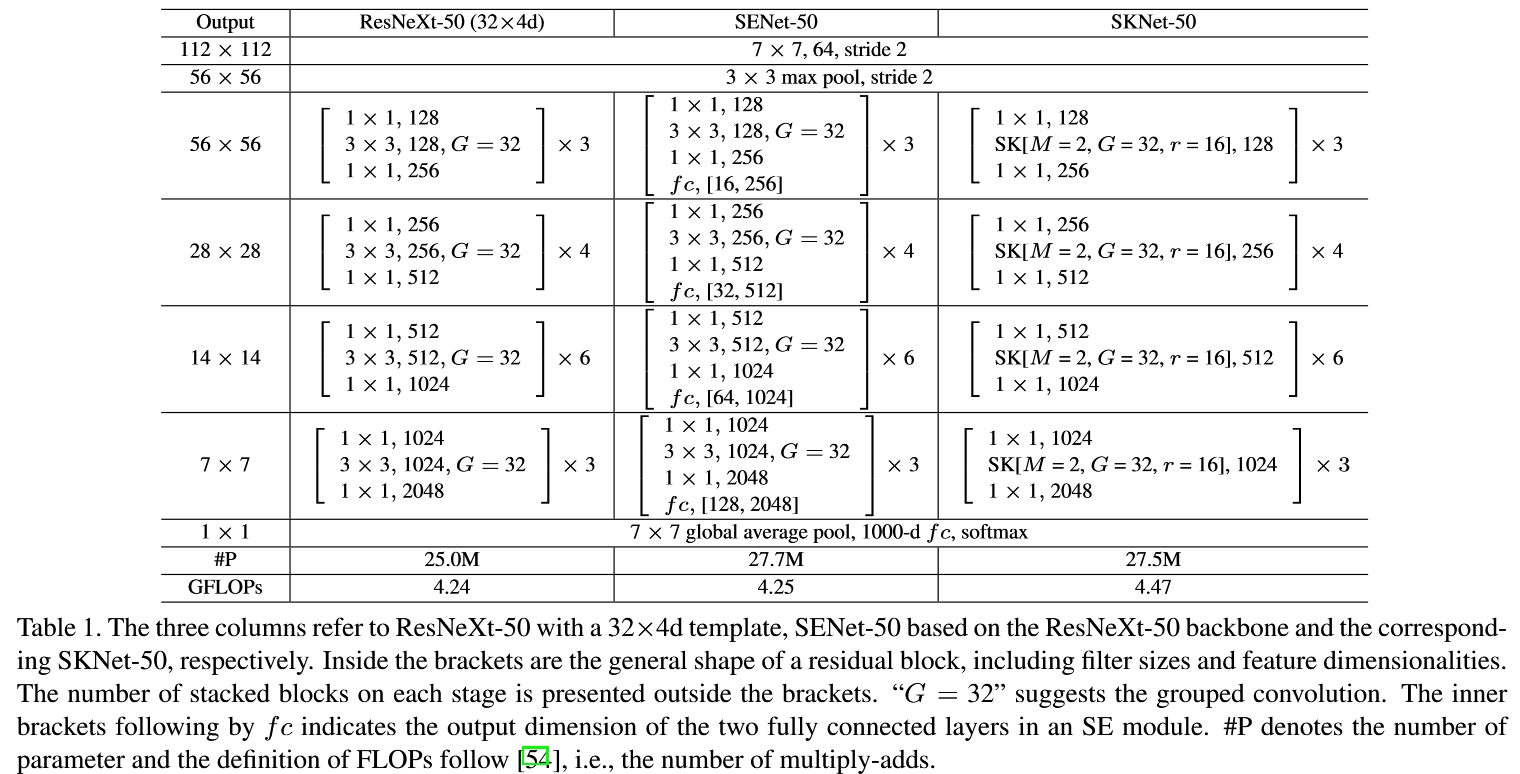
-
Backbone 是 ResNeXt.
- it has low computational cost with extensive use of grouped convolution
- it is one of the state-ofthe-art network architectures with high performance on object recognition.
-
参数量比SEblock少,计算量更多了
Experiments
这里,部分对比实验不再重复记录,只记录一些比较有意思的性质。
浅层的 SK Conv. 中,感受野越大的分支其权重越大。说明大的物体,用大的感受野去能够获更多有效的信息
位于深层的SK Conv. 中,其所有分支的权重趋于相等,这说明在深层网络中,尺度信息已经被丢失,不同的感受野获取的信息基本一致。
随着网络的加深,不同尺度的感受野之间的权重差逐渐变小,这同样印证了上一个结论
输入图像中的感兴趣物体越大,浅层中的大感受野分支的权重越大。
代码:timm-sknet