Squeeze-and-Excitation Networks
“we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels”
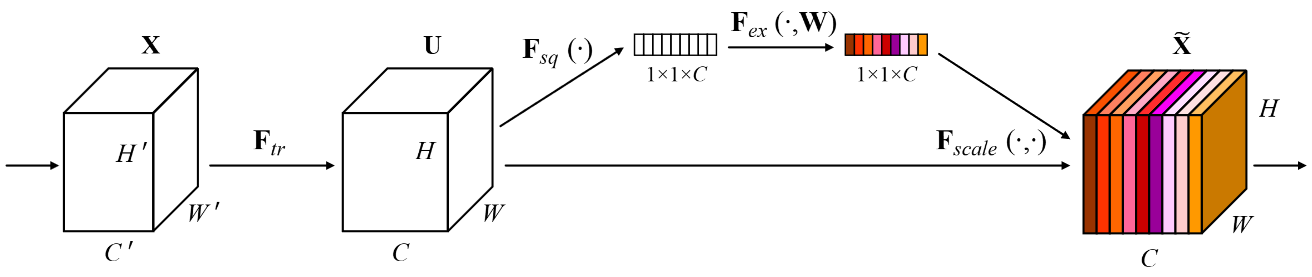 CNN 中卷积核对不同通道信息的关注是隐式的和局部的 (所有权中默认为 1)。SENet 通过提出可学习的 SE Block 来使得网络自适应的关注不同的 channel,通过 Squeeze 获取 Global information embedding,再通过 Excitation 显式的对齐(Recalibration)不同通道的信息。
PS: SENet 获得了最后一次 ImageNet 分类比赛的冠军。
PPS: SENet属于通道注意力
CNN 中卷积核对不同通道信息的关注是隐式的和局部的 (所有权中默认为 1)。SENet 通过提出可学习的 SE Block 来使得网络自适应的关注不同的 channel,通过 Squeeze 获取 Global information embedding,再通过 Excitation 显式的对齐(Recalibration)不同通道的信息。
PS: SENet 获得了最后一次 ImageNet 分类比赛的冠军。
PPS: SENet属于通道注意力
Links
- PDF Attachments: 2018’Squeeze-and-Excitation Networks_Hu et al_.pdf
- Zotero Links: Local library
My Comments and Inspiration
- 计算每个通道的重要性时,实际上是通过考虑通道内的全局信息,也就是说在CNN的前期就已经提前考虑了全局信息。这或许告诉我们,如果能在一直都是局部的操作中提前引入对全局信息的考量,或许能够带来更好的性能提升。那么反过来,在全是全局的考量中(Transformer),若能够重点的关注某个有效的局部,是否能够带来有效的提升呢?
Cores, Contributions and Conclusions
Cores 通过通道内的全局信息对每个通道的重要性进行建模
Contribution
- 第一个 channel attention 的工作,启发了接下来关于通道注意力的其他工作。
- SE Block 是一个即插即用的轻量模块,基本上用了必定涨点
Conclusion 见实验
Preface
在 CNN 中,卷积核只能在局部区域内融合通道和空间的信息。
为了增强 CNN 的表达能力,各种各样的设计都被提了出来。通过捕捉空间上的相关性(空间注意力),证明可以增强 CNN 的表达能力
因此在本文中,作者从另一个角度对网络进行了设计——捕捉通道之间的相关性。通过考虑每个通道内的全局信息来显式建模不同通道特征的重要性(相关性),对不同通道的特征进行重对齐 (reweight, recalibration)
Methods
SE Block 中包含 Squeeze 和 Excitation 两个步骤
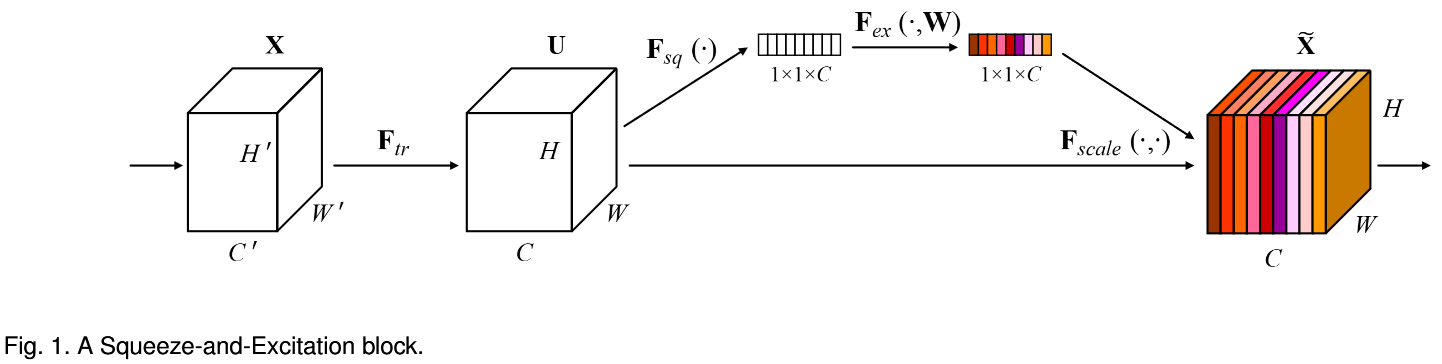
Squeeze step: Gloabl Information Embedding
Use global average pooling to generate channel-wise statistics
直接对输入的 Feature map 沿着 维度做 average pooling
z_{c}=\mathbf{F}_{s q}\left(\mathbf{u}_{c}\right)=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} u_{c}(i, j)$$ **Excitation step**: Adaptive Recalibration > To fully capture channel-wise dependencies\begin{aligned} \mathbf{s}=\mathbf{F}{e x}(\mathbf{z}, \mathbf{W})=&;\text{Sigmoid}(g(\mathbf{z}, \mathbf{W}))\ =&;\text{Sigmoid}\left(\mathbf{W}{2} \delta\left(\mathbf{W}_{1} \mathbf{z}\right)\right) \end{aligned}$$ : ReLU 函数 : 第一个全连接层 : 第二个全连接层 : reduction ration
设置两个全连接层的目的是限制模型的复杂度,同时增强表达能力。这两个全连接层形成了一个 bottleneck。
最后,将和输入进行 channel-wise multiplication (通道和通道对应相乘),得到SE Block的最终输出。
模型计算复杂度、训练、推理时间比较
对于单独的一个 SE Block 来说,其参数量就是两个全连接层的参数量总和:
在一个有 S 个 stage 的模型中,每个 Stage 中添加 个 SE Block,其总的参数量为
- ResNet-50 requires ∼3.86 GFLOPs in a single forward pass for a 224 × 224 pixel input image.
- With , SE-ResNet-50 requires ∼3.87 GFLOPs (a 0.26% relative increase)
In practical appliactions
- GPU Training time: A single pass forwards and backwards through ResNet-50 takes 190 ms, compared to 209 ms for SE-ResNet-50 with a training minibatch of 256 images (both timings are performed on a server with 8 NVIDIA Titan X GPUs)
- CPU inference time: For a 224 × 224 pixel input image, ResNet-50 takes 164 ms in comparison to 167 ms for SE-ResNet-50.
Experiments
消融实验(对 SE Block 的性质研究)
Reduction ratio 影响不大
同时,作者指出了一个情况: 全部使用同一个可能并不是最优的,如果能找到合适的每层对应的参数r,则有可能获得更好的结果。
In practice, using an identical ratio throughout a network may not be optimal (due to the distinct roles performed by different layers), so further improvements may be achievable by tuning the ratios to meet the needs of a given base architecture.
初步获取每个通道信息时,Average pooling 效果比 Max polling 效果好
同时,作者认为,无论采用什么方式,SE Block都会有效。
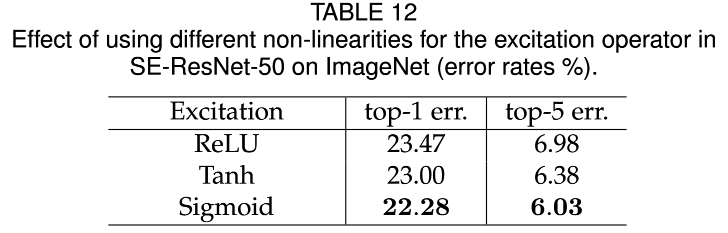
Excitation 中最后一个非线性函数选择Sigmoid效果比ReLU和Tanh要好。其实可以想想作为一个门函数来用的,但是又不想用Softmax这种结果独占或者求和为1,那就最好使用Sigmoid了。
This suggests that for the SE block to be effective, careful construction of the excitation operator is important.
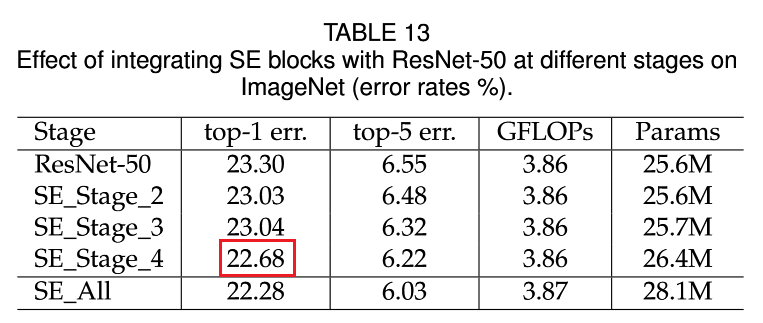
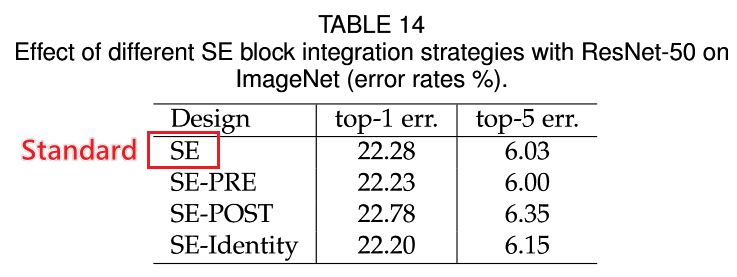
ResNet 不同的 Stage 单独插入 SE Block,无明显的规律,似乎越往后效果越好,但是插入 SE Block 一定会有效果的提升
SE Block 在 Res Block 中的位置对结果影响很大
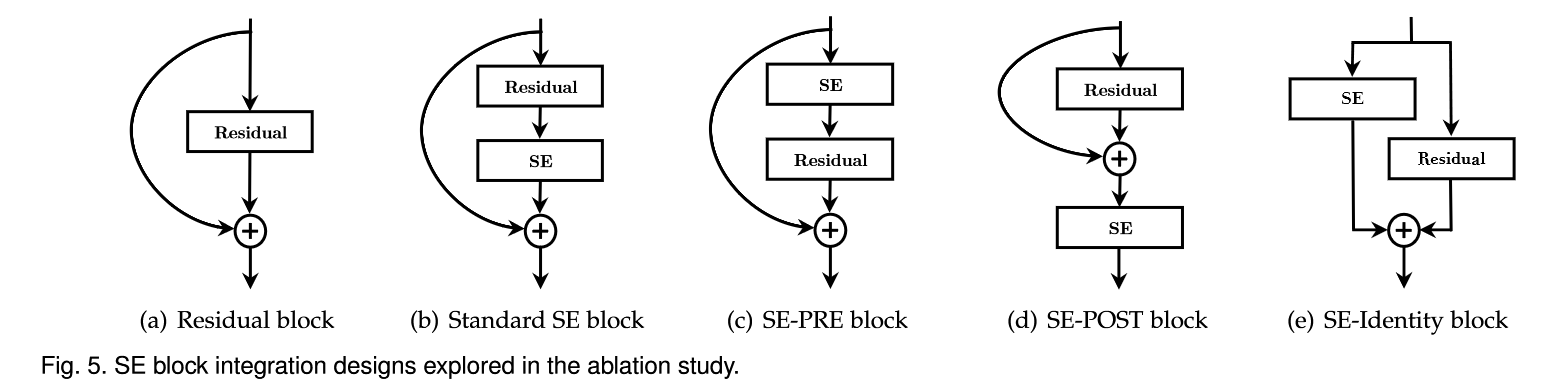
- SE-PRE, SE-Identity and proposed SE block each perform similarly well
- SE-POST block leads to a drop in performance
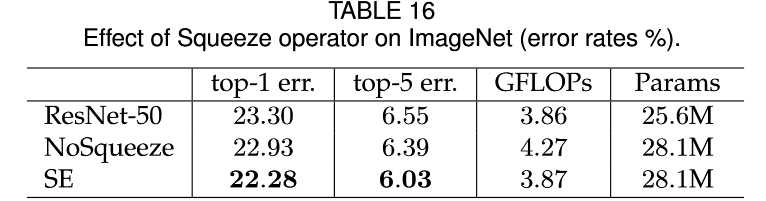
Squeeze Operation 是有用的
作为对比,作者去掉了Squeeze操作,同时将Excitiation 操作变成了对应的1x1卷积,其输出同样尺寸的特征图。这种情况下,就没有global information embedding了。
Role of Excitation (非常重要和有趣,具有借鉴意义)
本部分实验探究了不同深度的网络层,其不同通道的重要性的分布。这有助于我们进一步了解神经网络的一些性质。
作者选了外观和语义差距比较大的四类 (goldfish, pug, plane, ciff),选取了位于深层和浅层的 SE Block 中的 Excitation 后得到的不同通道的重要性分布 (或者说得分),平均选取了其中的 50 个 channels 进行展示,如下图(以所有类别的在对应通道上的平均得分最为对照)。
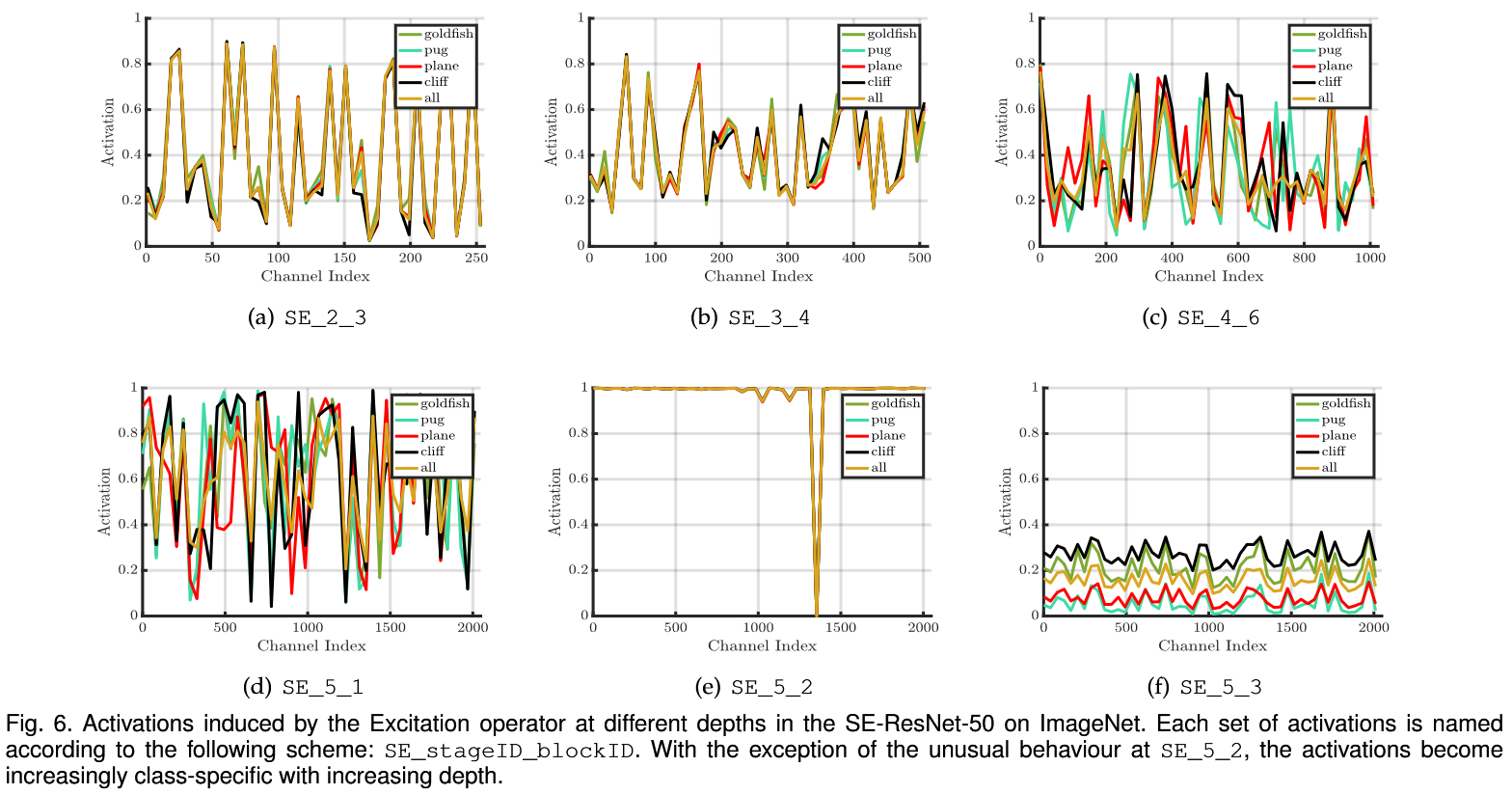 我们可以得到如下观察
我们可以得到如下观察
- 在网络的浅层(stage2 和 stage3),不同类别 excitation 得到的重要性(值)基本都是相等的
- 网络的深层, excitation 得到的重要性分布已经是 class-specific 的了
- 惊讶的发现,SE_5_2中的分布基本全部都是1,并且SE_5_3中不同类别的分布基本是相似的,只是有尺度上的分别。这说明这两个SE Block在recalibration上相比于前面的SE Block不是很重要
观察的1、2点说明如下事实,并且符合之前的一些研究
- 浅层的网络得到的特征是更 general 的
- 深层的网络得到的特征是更加class-specific的,具有不同类别的特有的语义特征
Earlier layer features are typically more general (e.g. class agnostic in the context of the classification task) while later layer features exhibit greater levels of specificity [83].” (Hu 等。, 2018, p. 11)
接下来,作者又选取了goldfish和plane两类,计算并可视化了他们的均值和方差。
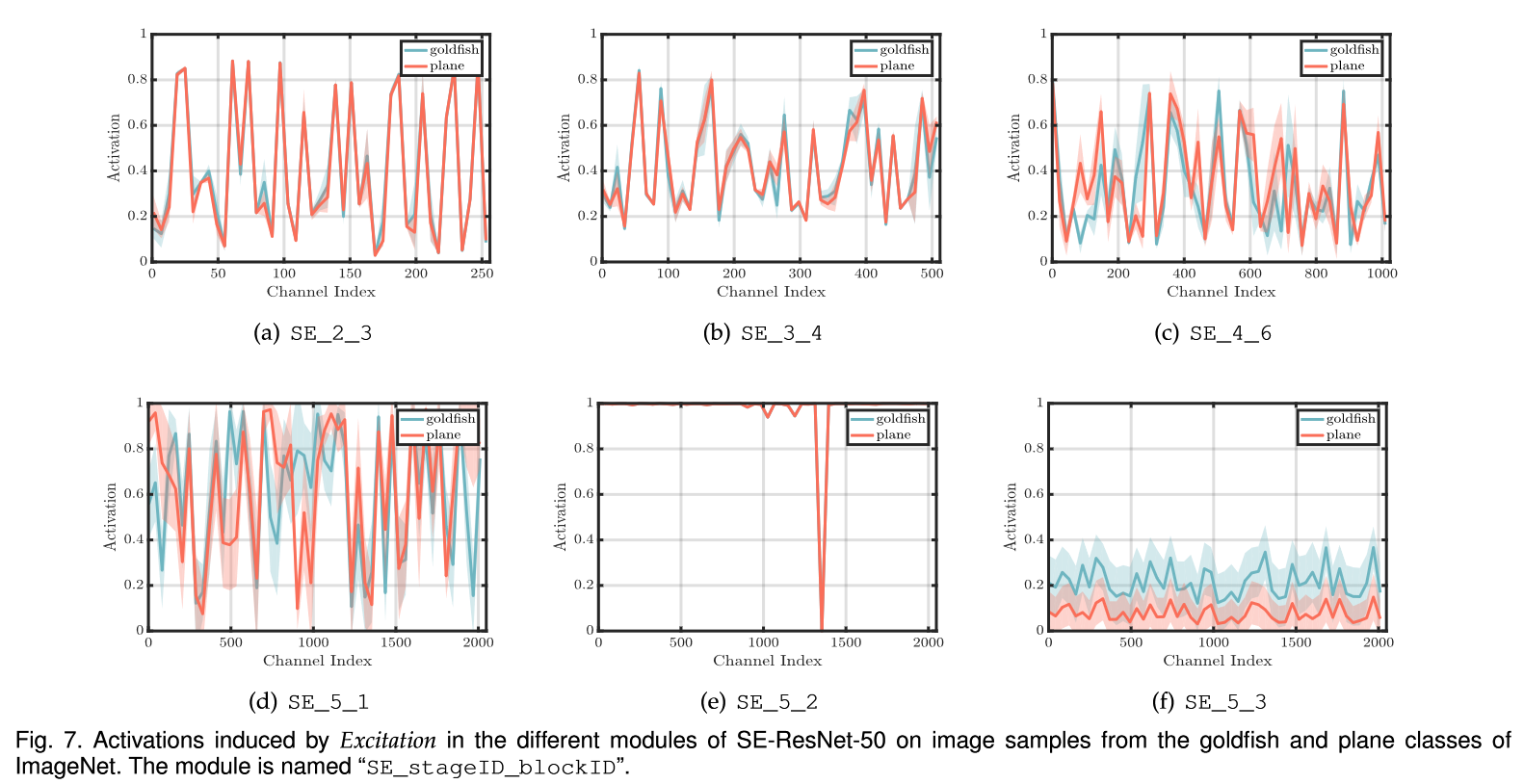
We observe a trend consistent with the inter-class visualisation, indicating that the dynamic behaviour of SE blocks varies over both classes and instances within a class. Particularly in the later layers of the network where there is considerable diversity of representation within a single class, the network learns to take advantage of feature recalibration to improve its discriminative performance [84]. In summary, SE blocks produce instance-specific responses which nevertheless function to support the increasingly class-specific needs of the model at different layers in the architecture.