OH-Former: Omni-Relational High-Order Transformer for Person Re-Identification
Links
- PDF Attachments: 2021’OH-Former_Chen et al.pdf
- Zotero Links: Local library
My Comments and Inspiration
本文提出了 OH-Former,通过共享 Attention map 降低捕捉高阶统计信息的计算量,引入 Deformable + depthwise conv. 够捕捉同一关注区域的局部关系。实验证明,引入高阶统计信息能够提升模型表现。
问题:
- 为什么串联 SA 就是高阶统计信息的抽取?
- 默认问题 1 成立,那本文的贡献在于在可控参数量下提升了注意力的阶数,使其的高阶统计信息更丰富。
启发:
- JS 散度用于描述两个 attention map 的相似度值得借鉴,通过引入 JS 散度+一个权重矩阵 ,这样不仅能够避免共享 attention map 所带来的多样性降低,还能尽可能保证 attention map 之间是相似的。
Preface
在 ReID 的任务中,引入注意力机制能够让网络自主地捕捉不同身体部分的关联,这种身体的部分是粗糙的。同时作者认为,Transformer 并没有深入挖掘高阶的信息,而只能基于 Q 和单独的 K 来捕捉一阶的远距离信息。
- High-order statistics can improve the model classification performance (Li et al. 2018; Lin, RoyChowdhury, and Maji 2015), but they lead to high-dimensional representation and expensive computation cost simultaneously.
Methods
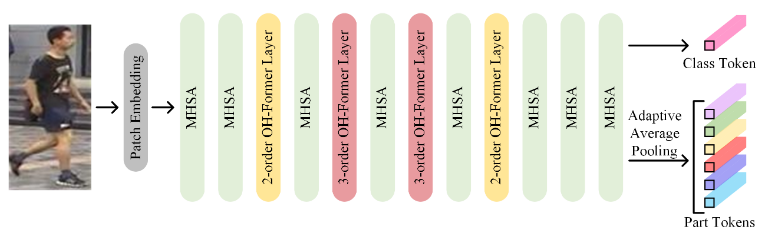
- ViT 前处理 + pos. Embed.
- 经过 MHSA 和 OH-Former (中间层)
- 最后一层的输出丢掉 CLS Token 后剩下的经过 Adaptive Average Pooling 后得到 Part Tokens (ReID 中用于表示身体部位的 tokens)
- 使用 CLS Token () 和 Part Tokens () 训练分类器或者做推理
ViT 前处理
- Patch embedding layer: 5x5 conv. (stride=5) →3x3 conv. (stride=2) for better local information extraction →
- Flatten: → , where
- cat with CLS token and add a learnable position embedding.
Loss Cross-Entropy and Triplet losses with BNNeck (Luo et al. 2019) over the class and part tokens.
Inference Concatenate the class and part tokens to form the final feature representation and compute the Euclidean distances between them to determine the identities of different people
Omni-Relational High-Order Transformer (OH-Former)
[! Note]- 结构图
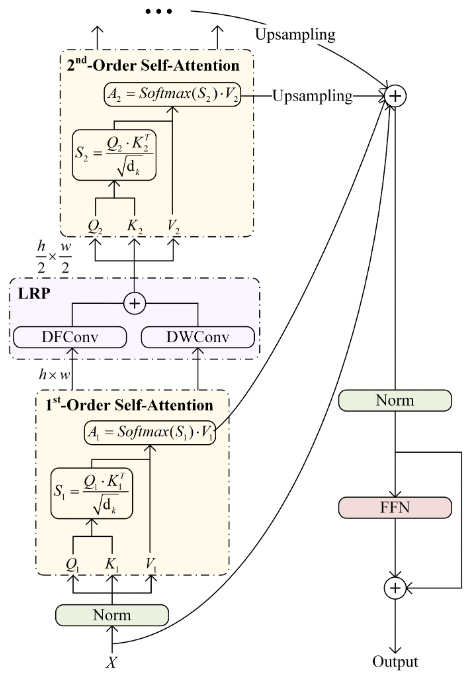
由 First-Order Self-Attention,Local Relation Perception Module,Omni-Relational High-Order Self-Attention,Omni-Relational Feature Fusion Feed-Forward Network.
-
First-Order Self-Attention,即标准的 SA 操作
- 获取 Attention map
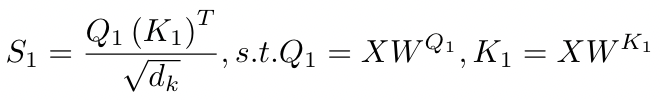 表示位置 和位置 的相似性。
表示位置 和位置 的相似性。 - 获取SA输出
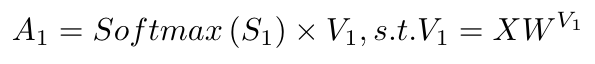
- 获取 Attention map
-
Local Relation Perception Module.
[! Note]- 本小模块动机 Transformer 只能关注全局,忽略了局部;而 CNN 的却可以关注到局部。之前的工作都采用了 grid depthwise convolution,忽略了局部的关系,所以这里采用了 deformable + depthwise conv.
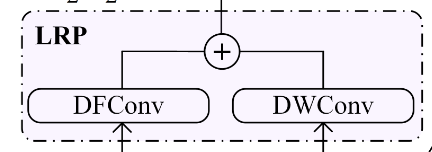 同一输入分两条路走而已,分别经过 deformable 和 depthwise conv.,操作为
同一输入分两条路走而已,分别经过 deformable 和 depthwise conv.,操作为
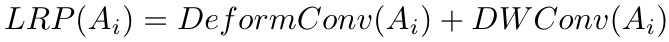 其中, 表示第 阶特征。本文中,作者输入 LRP 的是一阶特征 (不含 CLS Token,需要 reshape 回空间的特征图表示 )
其中, 表示第 阶特征。本文中,作者输入 LRP 的是一阶特征 (不含 CLS Token,需要 reshape 回空间的特征图表示 ) -
Omni-Relational High-Order Self-Attention 其实很简单,经过一次 SA+LRP 后,我们仍然会拿到一个 Token sequence,把这个再送进一个 SA 中,就是+1 阶的 token。而这个 SA 就是 Omni-Relational High-Order Self-Attention
但是这样做有一个缺点,计算量太大,每次相当于都要重新计算一次 SA,计算量+ 。
为了解决这个问题,作者针对同一个 OH-Former 的不同阶 SA 提出了 Prior Mixing Attention Sharing Mechanism,核心思想是同一层 OH-Former 的高阶 SA 共享一阶 SA 的 attention map
[! Note]- 动机和示意图 “Intuitively, we want the high-order self-attention to ex- tract high-order information for each location, so the spatial correspondence relationship should be guaranteed for each order within an OH-Former layer.” (Chen 等, 2021, p. 4)
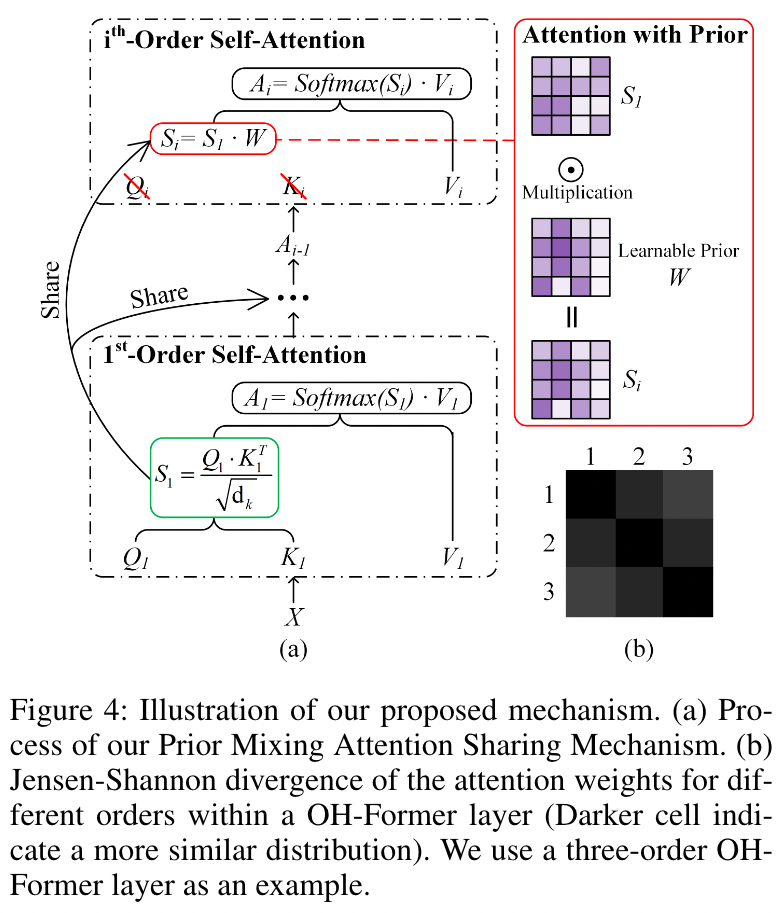
作者在文中提到,含人的图像可能包含一些方便识别的固定的模式,它们可以作为先验 (prior)。因此作者提出利用一种可学习的先验 (下式 , 其实就是一个可学习的权重而已) 来增强 attention map,即
为了保证一阶和高阶 attention map 是相似的,作者在文中使用了 JS 散度来描述它们之间的相似性并最小化它。
-
Omni-Relational Feature Fusion Feed-Forward Network.
对应 OH-Former 结构图右侧的那部分
- 对于高阶的 Token sequence,reshape 称空间特征图的样子 ,然后通过最近邻差值上采样到和一阶 token sequence 的空间特征图大小一样
- 然后再把这些空间特征图再 flatten 回去,与一阶的 token sequence 相加 (不含 cls token),再拼上原来一阶的 cls token
- 经过一个 LayerNorm 和 FFN+skip connection
- 此输出即为一个 OH-Former 的最终输出。
Experiments
Some Descriptions
In addition, the performance of Transformers still lags behind CNNs in the low data regime.