A Dataset and Benchmark for Multimodal Biometric Recognition Based on Fingerprint and Finger Vein
Links
- PDF Attachments: Ren 等。 - 2022 - A Dataset and Benchmark for Multimodal Biometric R.pdf
- Zotero Links: Local library
My Comments and Inspiration
- 本文是多模态的工作,可以学习本工作中如何提取全局和局部的特征
- 本文提出了第一个手指多模态的数据库,可以学习本文的撰写结构
Contributions and Important Conclusions
Contribution
- The first true multimodal finger-based datasete.
- The FPV-Net is not novel.
Experiments Conlcusions
- When the number of training samples was between 1 and 4, the recognition performance of the system was obviously improved. When 5 or more images were used for training, the performance of the system was not much different, and the training of the network was close to saturation.
- The image collected by the fingerprint and finger vein collection module integrated in the same space was quite different from the image collected by the fingerprint and finger vein collection module separately, and is more difficult for identity.
- It is clear that the time span affects the repeated exe- cution of finger feature collection, making it difficult to recognize finger-based multimodality.
Methods
Dataset (NUPT-FPV)
Motivation
当前的手指多模态数据库存在如下问题
- 样本数量少,无法满足深度学习的要求
- 现有的数据库标准和尺度不统一,不能作为一种标准的 benchmark.
Hardware
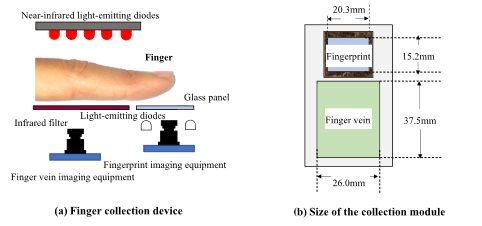
Dataset information
- Two-session collection with at last 1 week.
- 10 images for one modality in one session
- 140 volunteer in total, including 108 males and 32 females
- the average age is 19.3 years old (minimum 16, maximum 29)
- Index, middle, ring fingers for both hands
- Totally, 16800 (140*10*2*6) + 16800 = 33600 images.
- No ROI provided.
Evaluation Protocol
- Single session evaluation
- Cross-session evaluation (用一部分session1的训练,剩下的session1和所有的2作为测试,或反过来)
- Open-Set evaluation
- Metrics: Acc (CIR), mean, std. (Every experiments repreats 5 times.)
The Proposed method (FPV-Net)
The author proposed a deep learning-based method for motimodality recognition.
Motivation
Deep features lost the detailed information of the image. Although the shallow features were small in perception and weak in representing semantic information, they had high resolution and a strong ability to express detailed information. This part of the information was also an important part of recognition.
As a result, the author proposed to fused deep and shadow feature in the model.
Model
The backbone of the model is MobileNet V3 [34].
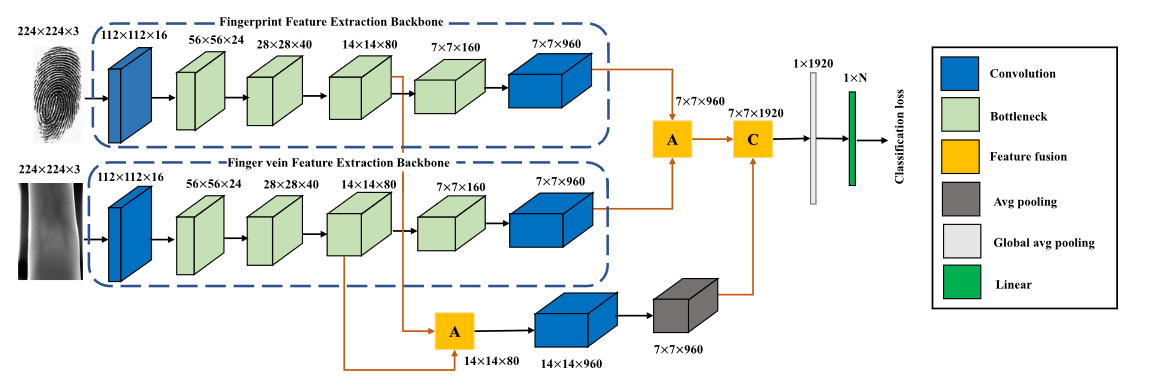 Each branch for each modality, and the parameter is independent.
Each branch for each modality, and the parameter is independent.
How to fuse two modality features?
- Extract Global and Local features of two modality.
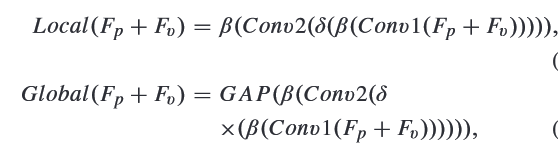 where and are both pointwise convolution; is ReLU, is global average pooling; is batch nomalization.
where and are both pointwise convolution; is ReLU, is global average pooling; is batch nomalization. - Use addition to connect local and global features, and used sigmoid to get the weight (may be like attention?)
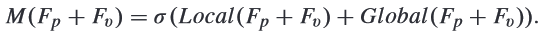
- Point-wise multiply.
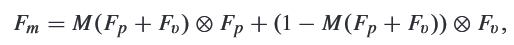
How to fuse deep and shadow features?
- Deep and shaodow features can obtained as:
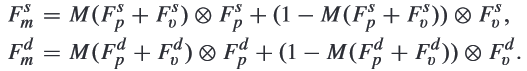
- Use convolution and average pooling to adjust the dimensions of the shallow features, making their dimension are same. Then concatenation them.
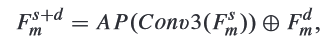 where is both pointwise convolution.
where is both pointwise convolution.
Experiments
Training details
- Training on a NVDIA 1080Ti
- 200 epochs
- lr = 0.1, reduced by 10 times for every 50 epochs.
- barch size = 8
- NO data augmentation and pretrain.
Please note that to test the real situation of NUPT-FPV as much as possible, the experiments in this paper did not use translation, rotation or other methods to expand the training data and did not use other datasets to pretrain the network model.
Comparision
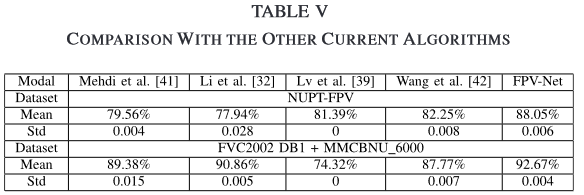
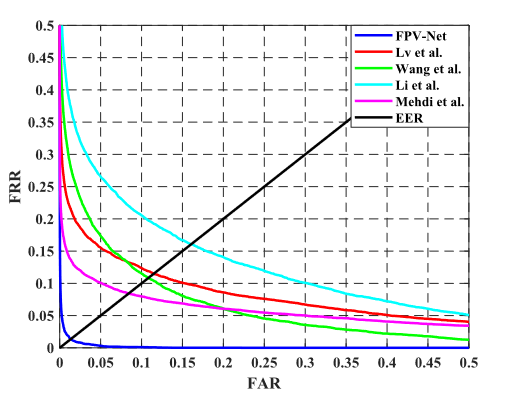
没作数据增强很亏,mmcbnu数据不可能这么低,EER表现很差
Some Descriptions
- Multimodal biometric technology using fingerprint and finger vein have prompted attention because of …
- Notable progress has been made in single fingerprint and finger vein recognition.
- Multiple publicly available datasets can free researchers from dependence on hardware manufacturing and large-scale collection.
- dislocations
- is a considerable scale in finger-related datasets.
- Finger-based multimodal feature fusion research is mostly feature-level fusion, which entails first using their respective modal feature extraction methods to extract feature vectors …
- At present, there are many benchmark datasets based on single finger biometrics, fingerprint and finger vein.
- Due to the external environment (such as temperature, light, weather, etc.), the state of the user’s finger placement, whether the finger was stained, etc., the session span was likely to bring changes to a person’s finger collection information.
- The time span of the first collection session was at least 1 week.
- The use of fingerprint datasets and finger vein datasets from two different sources to conduct multimodal recognition research was obviously not in line with the needs of practical applications.
- It is clear that the time span affects the repeated execution of finger feature collection, making it difficult to recognize finger-based multimodality.
- We believe that this dataset will promote the development of finger-based multimodal recognition.