MutualFormer: Multi-Modality Representation Learning via Mutual Transformer
Links
- PDF Attachments: 2021’MutualFormer_Wang et al.pdf
- Zotero Links: Local library
My Comments and Inspiration
为了能够让不同的模态之间的 token 进行高效的通信和交流,作者受到 Regularized Diffusion Process (RDP)[26] 的启发,提出了 MutualFormer,用来替换 Transformer Block 来完成多模态的融合,这个更加灵活 (Flexible) 和高效 (Efficiency)
然而,还是有一些摸不着头脑的问题:
- 为啥 Inspired by RDP?他有什么优点?文中说之前的两种 cross attention 采用 RDP 的方式就能弥补?
- 没解释为啥 RDP 就是在 metric space 操作,需要看 RDP 原文?
- 采用 RDP 的动机不明,RDP 优点解释的不够清晰
- 整个模块感觉有点冗余
Preface
- The task of this work is multi-modality fusion, i.e., obtaining reliable and representative feature of RGB and depth images.
- As the author says: The fundamental challenge of multi-modality fusion is how to exploit the useful cues of both intra-modality and cross- modality simultaneously for final representation.
- 目前,大部分给予 Transformer 的多模态融合工作都是采用两种方式进行融合的:simple concatenation [20], [22], [24] 和 intuitive cross-modality fusion [19], [21], [23], [25]。这两种方法存在下面的两种缺点
- 前者不能充分挖掘两个模态的关系
- 后者仅通过点乘来获取不同模态的联系,这种过于简单的方式可能导致 unreliable learning results caused by the modality gap.
为此,作者提出了 Cross-diffusion Attention (CDA) 来完成不同模态的通信交流。
Methods
实际上,MutualFormer 并不是一个网络,而是一个模块,类似 Transformer Block,作者通过改进原始的 Transformer Block ,使其可以完成多模态融合,即 MutualFormer,如下图
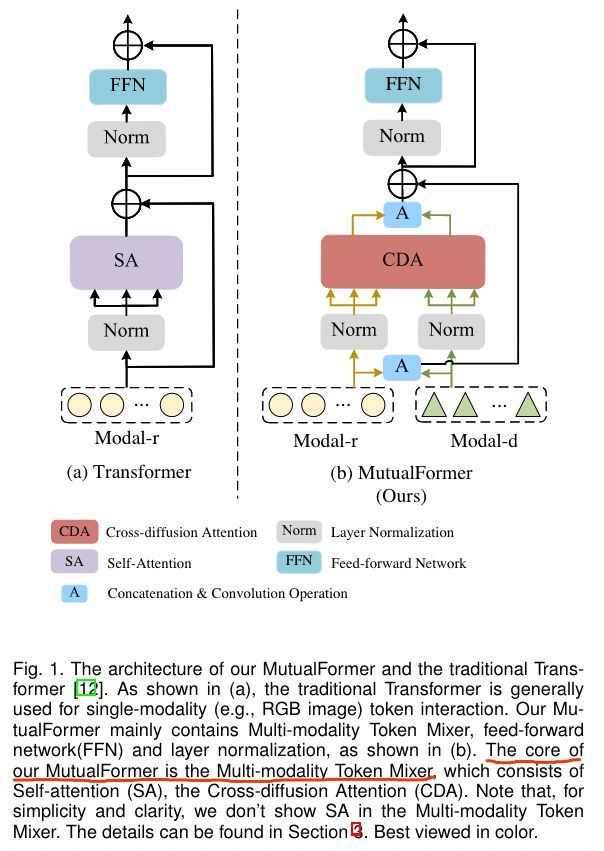
MutualFormer 含有三个模块: ① Self-attention (SA) for intra-modality token mixer ② Cross-diffusion Attention (CDA) for inter-modality token mixer ③ Aggregation block for final output。下面将逐一介绍
Self-attention (SA)
用于捕捉模态内的信息
即执行标准的 SA 模块。
给定两个模态的 Token Sequences , is the number of tokens and is feature dimension of tokens. SA is calculated as follows
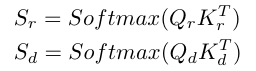
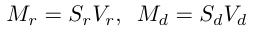 are all obtained by conducting linear transformations on , and are outputs
are all obtained by conducting linear transformations on , and are outputs
Corss-diffusion Attention (CDA)
Conducting the information communication among tokens belonging to different modalities.
[! Note]- 文中,作者给出了几种常见的 Cross Attention 的计算方法 Most of them are based on the cross-similarities , for example
And then, we can calculate the cross-attention output as . However, the author think that it is simple to interact with different modalities by . The intrinsic modality/domain gap make the results are unreliable.
Inspired by Regularized Diffusion Process (RDP) [26], the author is proposed CDA.
Instead of defining cross similarities on feature space, CDA is defined on metric space.
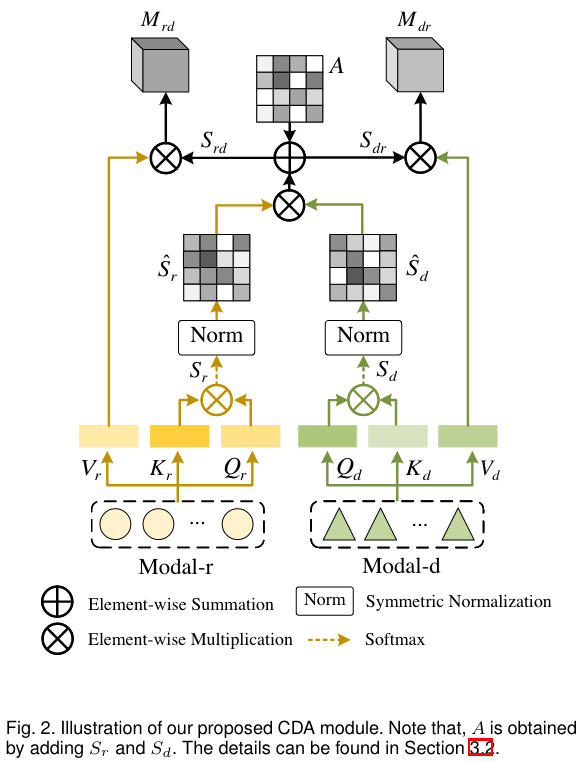
- Get normalized similarity matrices
\begin{aligned} \hat{S}{r}=D{r}^{-\frac{1}{2}} S_{r} D_{r}^{-\frac{1}{2}} \ \hat{S}{d}=D{d}^{-\frac{1}{2}} S_{d} D_{d}^{-\frac{1}{2}} \end{aligned}
其中 $D_r, D_d$ 是对角矩阵,每个元素的值是对应 $S_r, S_d$ 行的和 (原文是 where $D_r, D_d$ is a diagonal matrix with elements defined by the row-addition of $S_r, S_d$) - Calculate CDA as 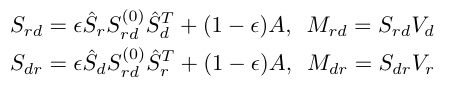 其中, $A=\frac{1}{2}(S_r+S_d)$, balancing hyper-parameter $\epsilon\in (0,1)$, $S_{rd}^{(0)}, S_{dr}^{(0)}$ can be initialed as the identity matrix $I$ or some other initial affinity matrices obtained by using other approaches, such as affinity matrix $A$. In this paper, set $S_{rd}^{(0)}=S_{dr}^{(0)}=I$ . We have 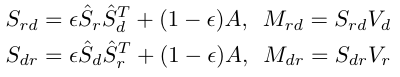 > [! Question] 意义是什么?需要参考 RDP[26]?为什么归一化时的对角矩阵要计算每个行的和? > [! Discussion]- >  Now, we have four components ( 2/each modality), i.e., $\{M_r, M_{rd}\}$ and $\{ M_d, M_{dr}\}$ (obtained by SA and CDA module). Then, get a more reliable representation $H$ for each modality 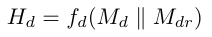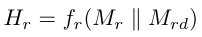 即 cat 起来之后通过两个卷积网络($f_{r/d}()$, 不同模态不同项权重) **Aggregation block** The final output of MutualFormer is the modality-invariant and context-aware representations $P$ for tokens. 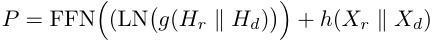 $\|$ 表示 cat,$g,h$ 分别表示两层卷积 (不共享权重),FFN 表示两个 FC 层(激活函数是 GELU),LN 表示 layerNorm 可以看到,这里有一个类似残差的东西。 ### 网络结构 由于 MutualFormer 是一个模块,作者将其应用在了 RGB 和 Depth 的两种模态的任务上,实例化的网络结构为 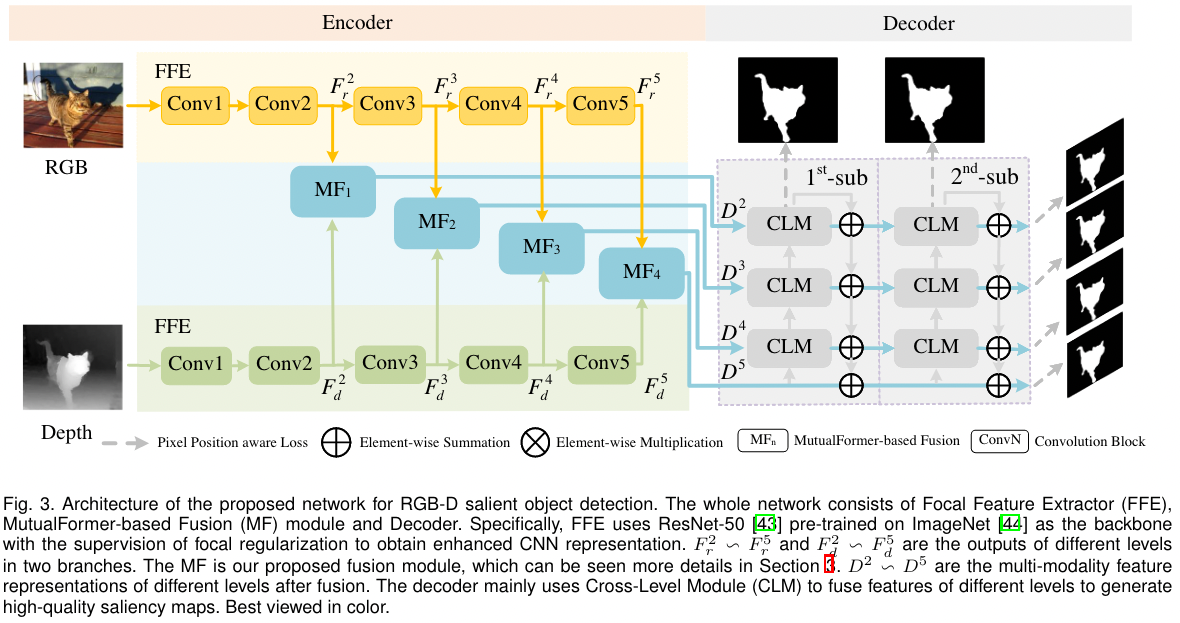 ## Experiments ## Some Descriptions