Finger Vein Recognition Based on Multi-Receptive Field Bilinear Convolutional Neural Network
Links
- PDF Attachments: 2021’Finger Vein Recognition Based on Multi-Receptive Field Bilinear Convolutional_Wang et al_.pdf
- Zotero Links: Local library
My Comments and Inspiration
Comments: The paper is in a bad organziation. The author post his idea step by step. He first proposed usage of dilation convolution to achieve “mulit scale receptive”, and then he thinks that the bilinear network is expensive on computation. Thus he then propose a light-weight CNN module by introducing depthwise separable convolution. Finally, a very complexity attention machenism is proposed to strengthen the relationship between space and channel.
提出的轻量模型,一点也不轻量。主要减少了Conv的参数,实际上很大的参数量都是来源于双线性池化后的全连接层,根据文章所示,光是最后一层FC的参数量就应该为 128*128*nClass
No loss function mentioned.
No inspiration.
Contributions and Important Conclusions
N/A
Motivation
- The author thinks the vein images are similar, and the second-order feature is a good choice to make feature more dicriminative.
- Computational cost is expensive
- Most
Methods
Step by step, the latter one aims to improve the former one.
-
Backbone, Multi-Receptive Field Bilinear Convolutional Neural Network (MRFBCNN)
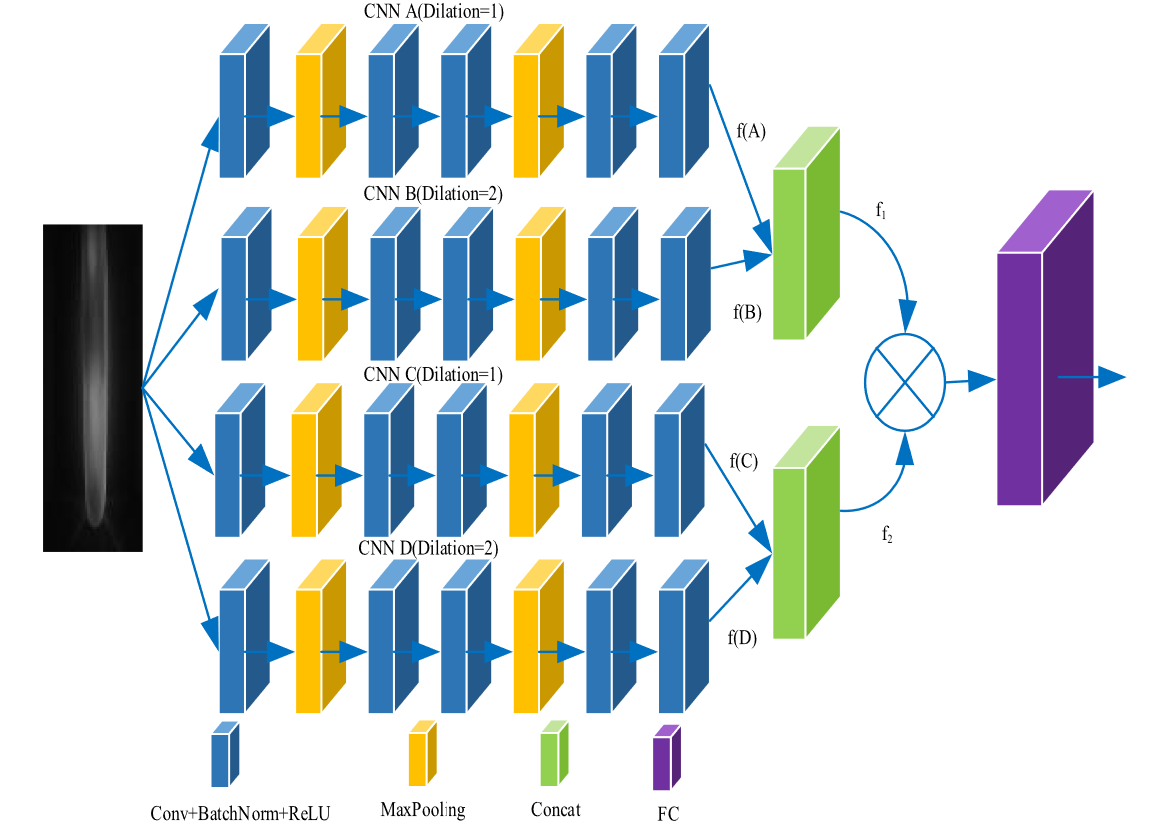
where 蓝色的圆× means Bilinear Pooling Operation, the details can be found here
In author’s description, the branch A and C, B and D are the same. Thus, in practical opreation, the author only used A and B branch to obtain two features and . The output of bilinear pooling are sent to FC to get final feature.
Does it work when ?
-
Make MRFBCNN be lightweight.
The author construct the lightweight module,consisting of depthwise sparable convolutional layer (DSConv1), like this

In addition, he also replace the last convolutional layer with kernel.
The architecture of L-MRFBCNN is
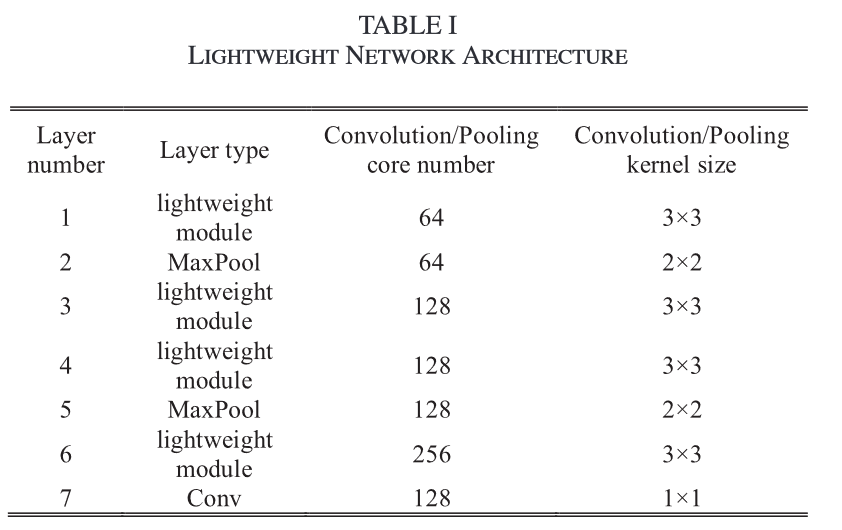 To understand above figure, you should read it with the figure in step 1.
To understand above figure, you should read it with the figure in step 1. -
Attention Mechanism: Dimensional Interactive Attention Mechanism (DIAM)
In order to strengthen the relationship between space and channel, the author propose DIAM.
However, the author do not tell us where to insert DIAM.
Easy to follow the picture below.
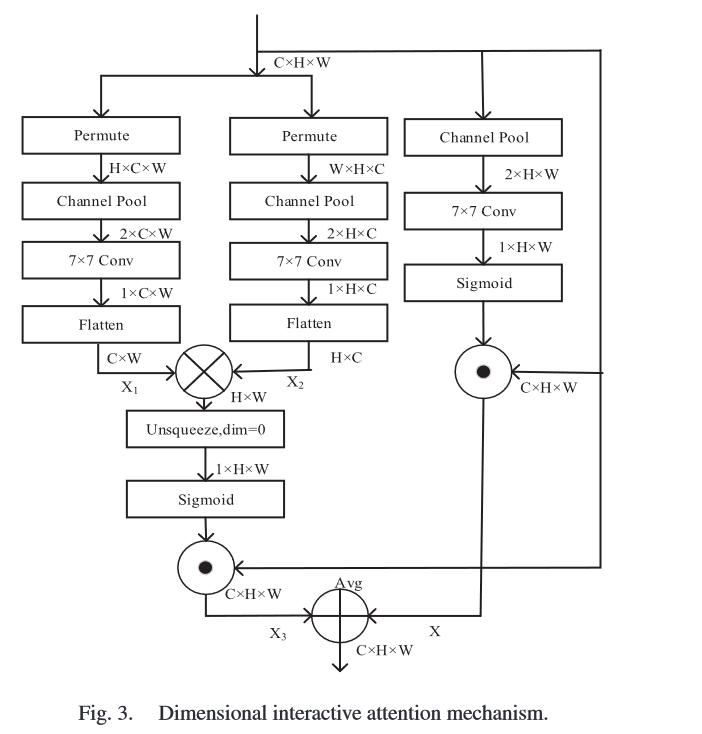
The output is
means element-wise multiplication means matrix multiplication means matrix add.
Experiments
Database
SDU and USM, 1:9 = test:training
So ridiculous and make no sense....
Details
- GTX 1660
This work maybe run on his own laptop.
- LR: 0.0001
- epoch: 200
- bs: 24 (It should be limited by its memory.)
- Optimizer: Adam, no more information about Adam configuration.
Some Descriptions
Footnotes
-
F. Mamalet and C. Garcia. “Simplifying convnets for fast learning,” in Proc. Int. Conf. Artif. Neural Netw., 2020, pp. 58–65. ↩