Joint Attention Network for Finger Vein Authentication
Links
- PDF Attachments: Huang 等。 - 2021 - Joint Attention Network for Finger Vein Authentica.pdf
- Zotero Links: Local library
My Comments and Inspiration
注意力模块的动机确实比较合理,SENet 直接使用 Max pooling 仔细想想可能确实不是最优的途径,本文是通过感知两个 axis 上的信息进行空间信息感知的,除此之外还有没有其他的思路?
- 进行空间位置感知,可以感知两个方向的信息。
- 想感知两个方向的信息,可以通过特定尺寸的卷积。
Cores, Contributions and Conclusions
Core 本文中的核心模块是 Joint attention module (JA Module),本质上一种通道注意力模块。与 SE 的区别在于生成通道注意力时考虑了通道内的空间信息 (可学习的),而 SE 是直接使用 max pooling,对通道内空间信息的感知能力不强。
Contributions
- 提出了 JA Module 和 JAFVNet
- 第一次在 FVR 中使用 GeM?
Conclusions NA
Motivation
希望在做通道注意力的时候多关注一些通道内的空间信息。之前的工作(对标SENet)用的max pooling有点简单,并且不可学习。
Methods
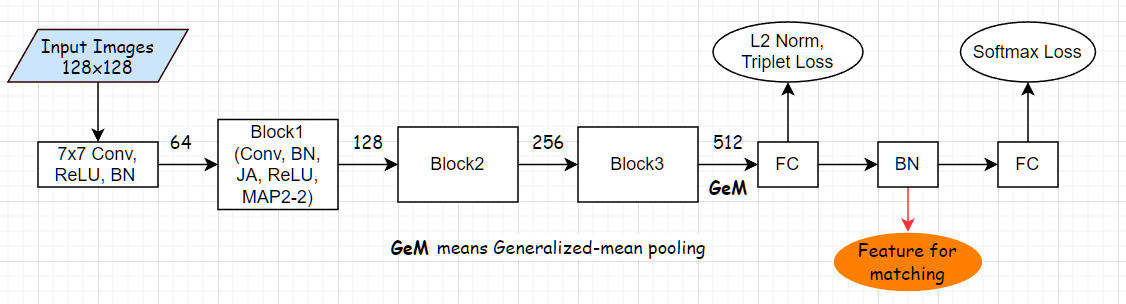
Backbones
本文的 Backbone 是作者自己设计的,在设计的时候考虑了一些假设和原则
- 静脉识别主要看的是图像中纹理特征,相比于经典的物体识别,属于 low-level semantic information. 因此作者认为应该加宽浅层网络,同时不需要把网络做的很深。
- 加入了用于分类的辅助分支,用于扩大类间间距同时缩小类内间距,可以有效的提升特征表达能力。在实际中,分支并不是并行的,而是串行的,特征流首先走用于 metric learning 的 loss,然后过分类的损失。
网络结构如上图。
Trick Summary
- label smoothing
- temperature scaling
- BN Neck (helps two loss functions to converge better during training)
值得注意的是,作者在最后一个 block 后面,Flatten 特征图的时候使用 Generalized-mean pooling(GeM Pooling),并声称发现 GeM 在静脉识别中很好用,而自己是第一个吃螃蟹的人。
这里不知道是替换了最后的MAP还是在MAP后面做的GeM,也不知道尺寸和步长,同样的,最后一层的MAP尺寸步长也不确定
另外,作者在test的时候采用了BN层后的输出,个人认为可能希望直接利用好BN的归一化作用
Joint Attention Module (JA Module)
Motivation :
However, conventional channel attention which uses global pooling only considers reweighting the importance of each channel by modeling channel relationships without positional information.
Feature grouping 给定输入的 Feature map ,沿着 channel 维度均为成 G 份,, 其中
Positional attention embedding 在每个子特征图上进行() 使用 kernel size 分别为 (H, 1) 和 (W, 1) 的卷积核进行卷积,来感知两个 axis 上的空间信息
得到的结果称为 direction-aware feature maps,两个一维的向量
Positional attention generation 将上面得到的两个direction-aware feature maps转换为attention map (都是在上做的)
- Concate起来后经过1x1卷积(with a reduction parameter )+ReLU,得到输出
- 按照原始的维度把拆开得到
- 分别将和送入两个1x1卷积中,并经过sigmoid函数,维持通道数不变,得到两个PA map -
- 计算
Aggregation We finally aggregate all output from subgroups. The Channel Shuffle operation, proposed in ShuffleNet V2 [7], is adopted to enable cross-group information along the channel axis.
The whole JA does not change the shape of the input tensor so that making it a plug-and-play module that is quite easy to be integrated with most CNN architectures.
Loss function
- Triplet Loss with hard mining
- Softmax Loss, intrgrating with temperature scaling and label smoothing.

Experiments
Details
- 没有使用 ROI,而是直接利用 Crop 出含有手指的矩形,并 Resize 为
- Batch size = 128, 每个 batch 有 32 类,每类 4 个样本(因为有 Triplet loss)
- Adam optimizer,
- LR = 1e-3, with the cosine annealing scheduler.
- 200 epoches
- Implement on a 1080Ti.
Ablations
- JA 有效, Channel Shuffle 有效
- JA 比 SENet, CBAM 有效
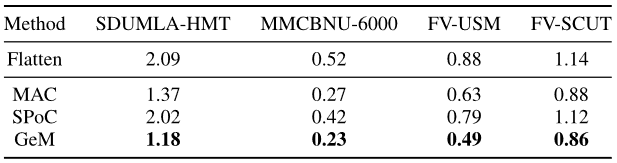
- Flatten 使用 GeM 更有效,比较的是不同的 Flatten 的方式
Visualization
使用Grad-CAM可视化,第一行是SCUT-FV,第二行是MMCBNU6000
 这个图看上去可能并不能说什么,感觉为了放而放
比如第二行 CBAM 和 JA 比,CBAM 对于背景的压制明显更好。只是对于静脉的关注可能确实不如 JA,但是 JA 关注了不少背景
这个图看上去可能并不能说什么,感觉为了放而放
比如第二行 CBAM 和 JA 比,CBAM 对于背景的压制明显更好。只是对于静脉的关注可能确实不如 JA,但是 JA 关注了不少背景
Comparison
好像都是都从其他文章中拿过来用的。
SDUMLA

MMCBNU

USM
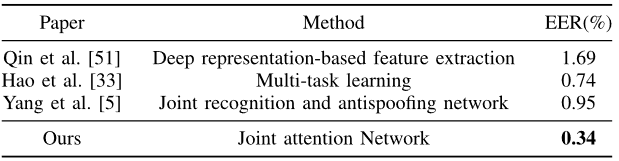
没做但是比较关注的部分
Trick 提升多大?实际上比较不是公平的,因为别的可能没用trick Open Protocol的效果
Some Descriptions
- The deoxyhemoglobin in the vein absorbs NIR light energy, causing the vein areas in the finger vein images to be darker than the nonvein areas.
- In particular, ambient illumination and contactless mode introduce more interference factors that result in poorer quality of vein images, thus making the performance of existing commonly used finger vein authentication algorithms still far from the expectations of the community.
- From these results, we can see that both CS and PA help in improving the finger vein verification performance, among which PA plays a stronger role.