Image Fusion Transformer
Links
- PDF Attachments: 2022’Image Fusion Transformer_Vs et al.pdf
- Zotero Links: Local library
- Official codes: GitHub
My Comments and Inspiration
本文是 encoder-decoder 架构,通过提出 ST Fusion 模块实现局部和全局信息融合的能力,引入 Self-attention 用于捕捉不同源图像的全局特征的能力(长距离依赖),并且另一个分支 CNN 用于捕捉两者的局部特征 (也就是说 ST Fusion 是一个双分支的结构)
实际上本文不能是 Transformer,顶多就是个 Self-attention 模块的设计,还不纯粹。
融合的动机设计也比较常见,没有针对性。
Preface
- Image Fusion Task: It refers to combining different images of the same scene to integrate complementary information and generate a single fused image.
- Drawbacks of traditional image fusion methods: images captured from different sources require different fusion strategies. As a result, traditional fusion strategies are designed in a source-specific manner.
- Drawbacks of CNN-based image fusion methods: They do not consider long-range dependencies that are present in the image
缺少长距离依赖可以说是一个十分通用的缺点了!
Methods
- 能够接收任意数量的输入图像并将其融合成一张图像
- 整体上是基于 CNN 的架构,嵌入 Self-Attention 完成远距离依赖的特征提取。
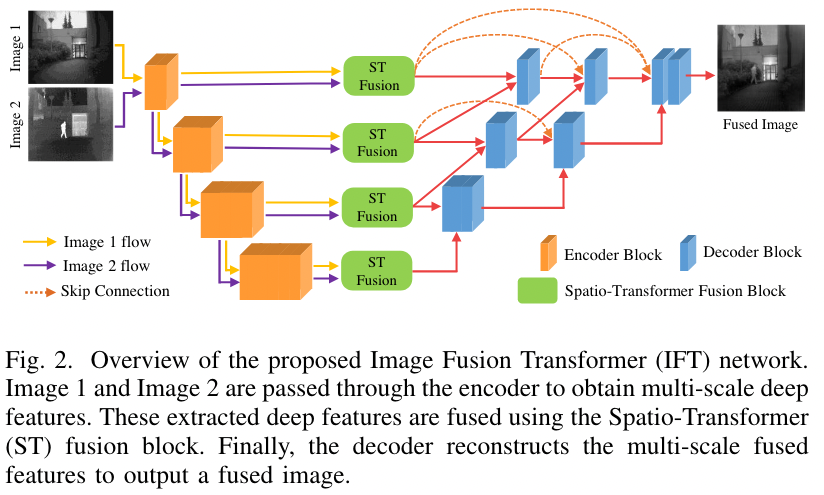
- 橘黄色的 Encoder Block 是 [3x3 Conv. + ReLU + Max pooling ]
- 对于不同的输入图像,是用共享的 encode (图中好像是共享的) 进行特征提取和下采样
- 所有输入流在每级的输出都会通过 ST Fusion 模块进行融合,融合后的输出用于后处理 (后处理斜着的线不是重点,下面也同样忽略)
显然,本文的重点在于 ST Fusion block,即绿色的部分,如何融合不容流的 feature map
ST Fusion block
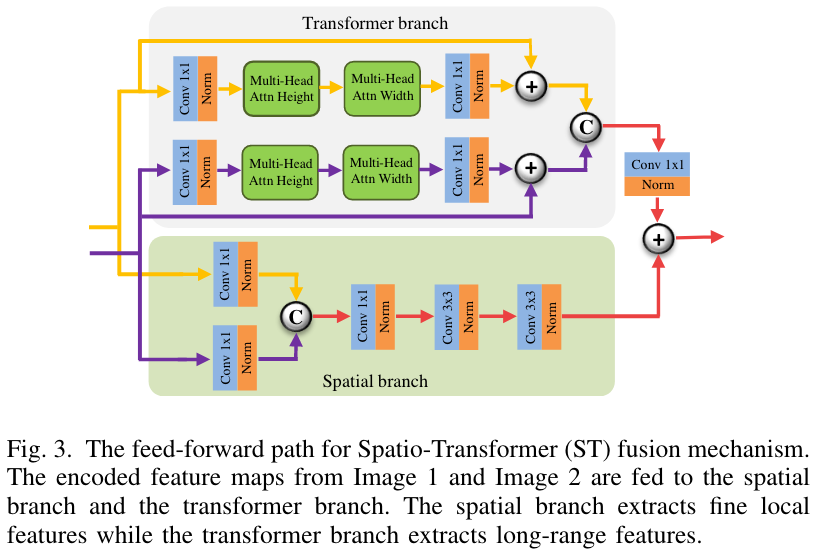
Transformer Branch - 捕捉全局信息
- 采用 axial attention mechanism [31],相比标准的 self attention 更高效,计算量更小
Specifically, in axial attention, self-attention is first performed over the feature map height axis and then over the width axis thus reducing computational complexity.
- 采用[32]中的 learnable positional embedding (for axial attention) 的方案,使得 axial attention 能够获取位置信息。
Spatial Branch - 捕捉局部信息 The spatial branch consists of conv layers and a bottleneck layer to capture local features.
Fusion Strategy
- 按照图片就行,注意 Transformer branch 中最后经过了一个 Conv. 1x1 进行通道对齐
- 图中 + 表示 add; © 表示 cat
[! Note] 未提到的信息参考官方代码
Some Descriptions
“self-attention mechanism is computationally expensive due to their quadratic complexity.” (Vs 等, 2022, p. 3) Self attention 的特点