HAT: Hierarchical Aggregation Transformers for Person Re-identification
Links
- PDF Attachments: 2021’HAT_Zhang et al.pdf
- Zotero Links: Local library
- Official codes: GitHub
My Comments and Inspiration
都是见过的东西,拼拼凑凑,取点名字,感觉就比较玄乎。
Preface
- Person Re-identification (Re-ID) aims to retrieve the same person under different cameras, places and times.
- 在 ReID 领域,多粒度或者说多尺度信息是十分重要的
- 动机:作者认为,纯 Transformer 的结构缺少了 CNN 中一些诸如平移、尺度 (scale) 和失真 (distrotion) 的不变性(这里有问题吧,哪里有尺度不变性?);而 CNN 又缺少 Transformer 的全局信息捕捉能力。
因此作者希望将两者结合起来,结合的点就是通过 Transformer 进行不同尺度信息的融合,同时捕捉全局信息。
Methods
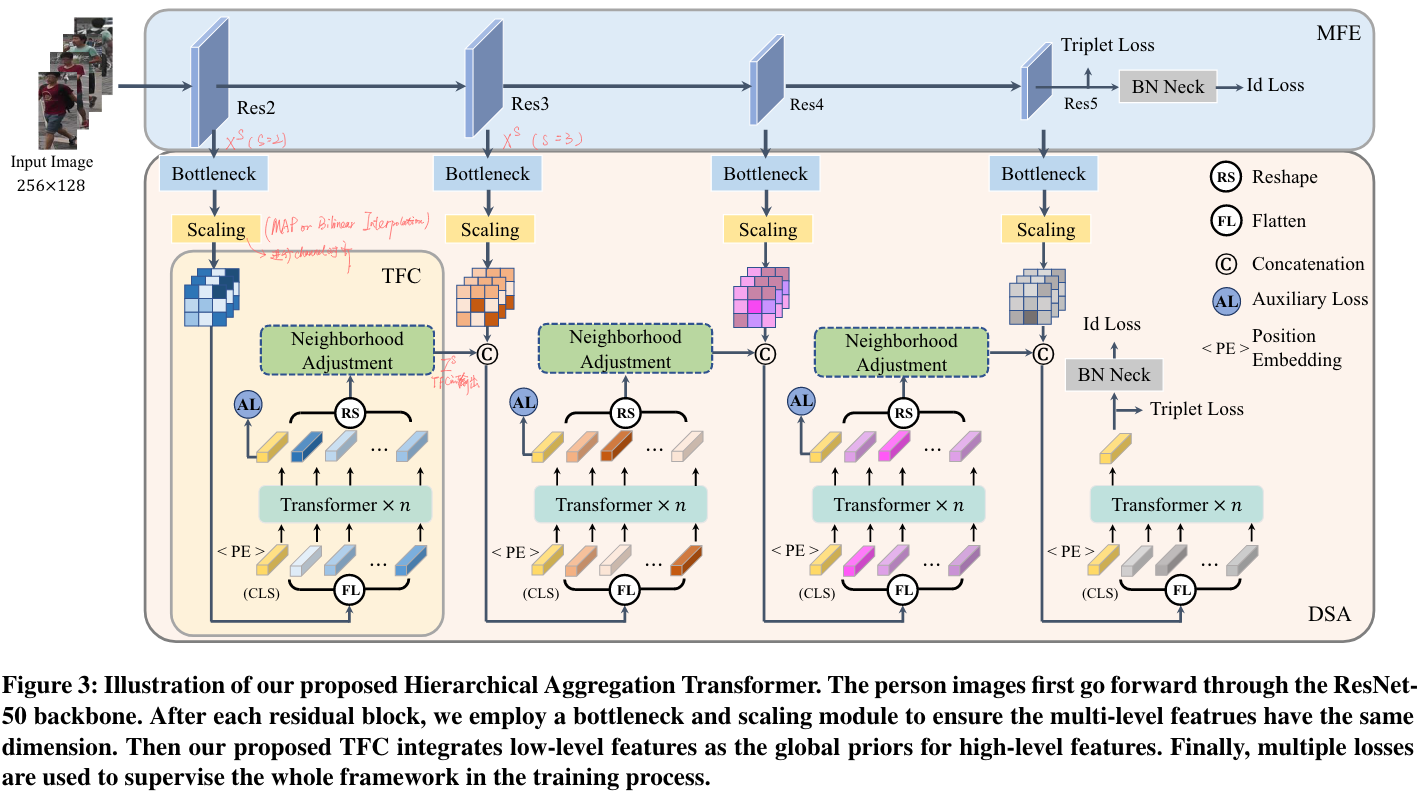
本文中,作者使用 ResNet50 作为主干网络,利用其 Stage 的特点提取多尺度特征 (每个 stage 的输出都是一个 scale),提出 Transformer-based Feature Calibration (TFC) 模块用于多尺度融合。
下面我们重点记录 TFC 模块
我们看整体图中的第二个 TFC,可以看出其是接受上一个 TFC 的输出 和当前 Scale 的特征图 作为输入的。
- 对于当前 Scale 的特征图 ,经过一个 Bottleneck, which applies a stack of residual blocks [12] to transform 𝑋𝑠 into compact embeddings.
- 之后将这个 compact embeddings 经过一个 Scaling 模块用于实现 spatial resolution 对齐 (这个 Scaling 模块可以是 max pooling 或者 bilinear interpolation),此时,我们有 , S 表示当前的 scale level,其实就是 CNN 的第 S 个stage
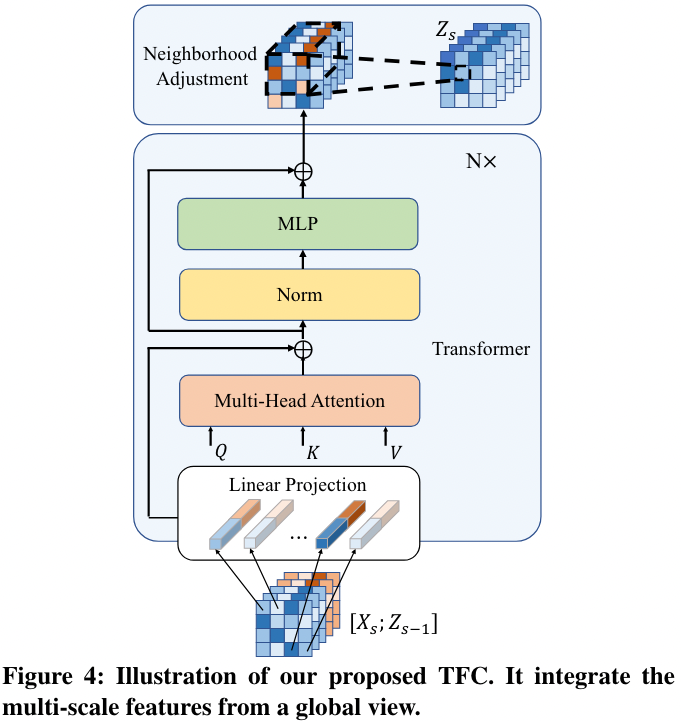
- 继上面得到了 之后,将其沿着通道维度拼接起来,得到当前层 TFC 的输入
- 将这个 按照 ViT 的前处理一样,切 patch 后 Flatten,变成 token sequence (作者的 patch size=1,所以等价于直接展平了)
- 添加 CLS Token 和 learnable pos. Embed. 送到标准的 Trans Block 中进行处理
- 最终输出 reshape 回原始的特征图(扔掉 CLS),经过几个 Conv. +BN+ReLU (作者称为 Neighborhood Adjustment, NA) 再捕捉一下局部特征即可作为当前 TFC 的输出了
我们不关心损失函数,只关心融合,所以本文到此为止。
Experiments
作者的实验中做了注意力的可视化实验,比较有意思,可以学习一下。