Finger Vein Verification using Intrinsic and Extrinsic Features
Links
- PDF Attachments: 2021’Finger Vein Verification using Intrinsic and Extrinsic Features_Lin et al_.pdf
- Zotero Links: Local library
Contributions
- A new deep model named EI-Verf is proposed to effectivelly extract intrinsic and extrinsic features of finger vein images. EI-Verf adopted autoencoder to extract intrinsic feature and a Siamese network to extract extrinsic feature.
- The author designs a new operation to fuse two features and give the matching score learning by the network, which is a novel idea for furthur digging.
- A new multi-view finger vein database is proposed. This database is a new challenging benchmark with no alignments and rotation-specific operations.
Some descriptions
- During the process of capturing finger veins, slight offsets and rotations are ubiquitous, resulting in a large intraclass distance.
- Therefore, without alignment and rotation-specific operations, MultiView-FV provides a challenging benchmark to test the performance of verification in practice
- In DB-3, since the images with various rotation and offsets are considered, the competing methods can be test effectively in a more challenging case.
Motivation
“Based on the idea of that a good classifier should try to make the intra-class gap be small and the inter-class gap be large, we proposed an EI-Verf model to extract intraand inter-class features for vein verification”
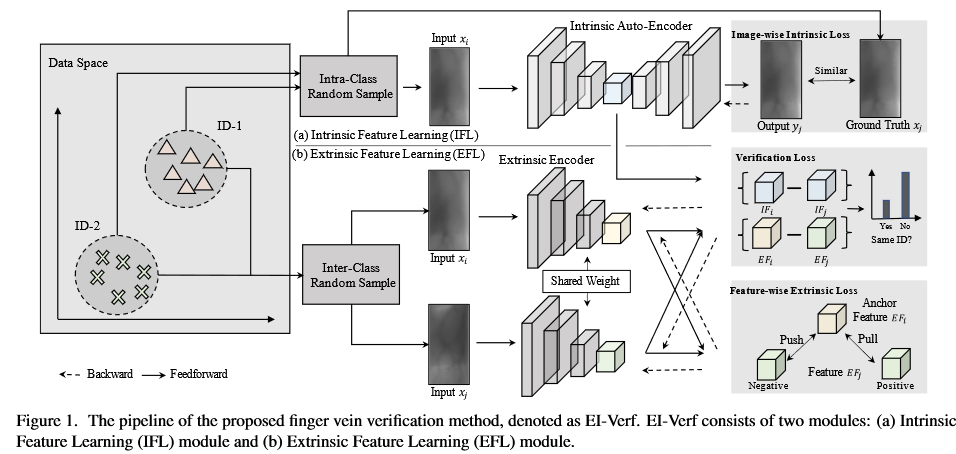
Method (EI-Verf)
Two components: a) Intrinsic Feature Learning (IFL) module, aimming to learn the finger vein features from the same ID based on the autoencoder network. b) Extrinsic Feature Learning (EFL) module, aimming to learn the finger vein features from the random IDs based on the Siamese network.
The core operations of two modules are the constructions of input image sets with same ID (for IFL) and random ID (for EFL)
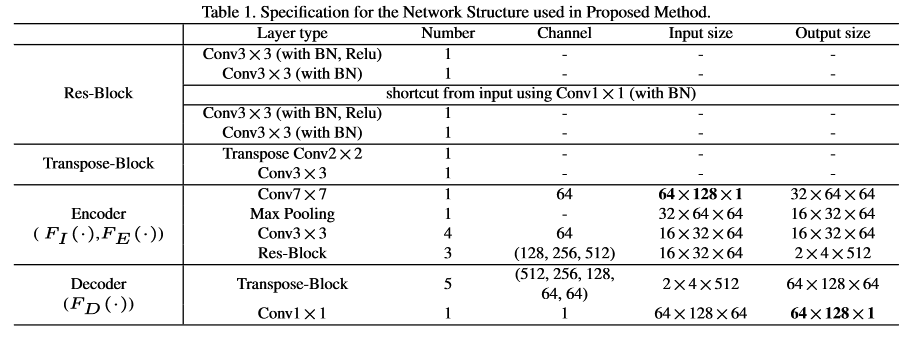
Input size is 64*128 (1 channel)
Intrinsic Feature Learning Module (IFL)
architecture: The main structure is autoencoder.
Inputs: Construct the image set with same ID . Then an image-pair is randomly sampled from the image set as input.
Loss function: One image in the image-pair is fed into the autoencoder to get a reconstruction output . Then the image-wise intrinsic loss is minimized as
where represents decoder and represents encoder, respectively.
The output of the encoder is taken as the instrinsic feature of input , denoting as .
Others: The author think the convergence speed of FAE(·) may be decreased since the same input corresponds to different . Hence he adopted a U-shape architecture to facilitate training.
Extrinsic Feature Learning Module (EFL)
Architecture: Same as , denote as , a Siamese network.
Input: The pair-wise images with random IDs ( and ) are taken as input.
Loss function:
where means the output of (same to ), and are the predefined threshold for dynamic adaption.
This is a pull-push game. Genuine pairs are pulled as the similar representation, while imposter pairs are pushed for learning discriminative features.
Verification using Intrinsic and Extrinsic Features
This is a logistic regression model.
The author defined the matching score as based on the distance between and , as shown below:
( is shown in EFL. The author do not mention the meaning of , I think maybe concate) is a learnable parameter, which can be updated by verification loss
Notion from author:

Algorithm: 注意第八步更新的时候是利用哪些损失函数求导的。

Experiments
Databases
SDU (DB-1), MMCBNU (DB-2), MultiView-FV (DB-3, the proposed database in this work)
Introduction to MultiView-FV
- Num of volunteers: 135
- Num finger per volunteer: 4 (index and middle for both hands)
- Capture times per finger: 4 for each view, resulting in 12 images per finger in total
- Num of finger vein images: 6480
Characteristic: “Therefore, without alignment and rotation-specific operations, MultiView-FV provides a challenging benchmark to test the performance of verification in practice”
Hardware:
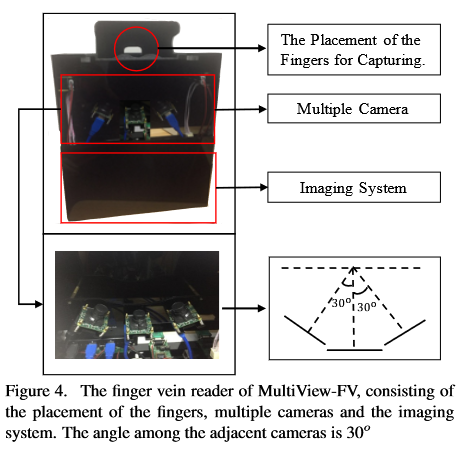
Protocal
For SDU (DB-1) and MMCBNU (DB-2), the first 5 samples are used as training samples, and the others are adopted as test samples [14]. For MultiView-FV (DB-3), 6 images from the same finger are randomly selected for training, and the remaining 6 images are used for test in this dataset.
Detail
PyTorch.
We initialized the weights in each layer from the model pretrained in ImageNet.
The Adam optimizer is used for our method, the learning rate is set to 0.001. Momentum and gamma of scheduler stepLR are set to 0.9 and 0.1, respectively.
Data preprocessing techniques, including normalization and Gabor filter are employed to enhance the texture of finger vein images. (How to use Gabor as prepercessing?)
Ablation studies

Comparsion with others
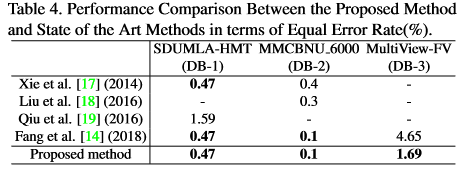 “This indicates the proposed EI-Verf is more robust agianst offsets and rotations, and is more suitable in practical applications.” 由于本文中的新数据库平移旋转更多,而自己的方法更好,作者得出这个结论
“This indicates the proposed EI-Verf is more robust agianst offsets and rotations, and is more suitable in practical applications.” 由于本文中的新数据库平移旋转更多,而自己的方法更好,作者得出这个结论
Note
[14] Yuxun Fang, Qiuxia Wu, and Wenxiong Kang. A novel finger vein verification system based on two-stream convolutional network learning. Neurocomputing, 290:100–107, 2018 [17] Shan Juan Xie, Sook Yoon, Jucheng Yang, Yu Lu, Dong Sun Park, and Bin Zhou. Feature component-based extreme learning machines for finger vein recognition. Cognitive Computation, 6(3):446–461, 2014. [18] Chenguang Liu and Yeong-Hwa Kim. An efficient fingervein extraction algorithm based on random forest regression with efficient local binary patterns. In 2016 IEEE International Conference on Image Processing, pages 3141–3145. IEEE, 2016. [19] Shirong Qiu, Yaqin Liu, Yujia Zhou, Jing Huang, and Yixiao Nie. Finger-vein recognition based on dual-sliding window localization and pseudo-elliptical transformer. Expert Systems with Applications, 64:618–632, 2016.