Training data-efficient image transformers & distillation through attention
Links
- PDF Attachments: Touvron 等。 - 2021 - Training data-efficient image transformers & disti.pdf
- Zotero Links: Local library
- Official code: GitHub
My Comments and Inspiration
Preface
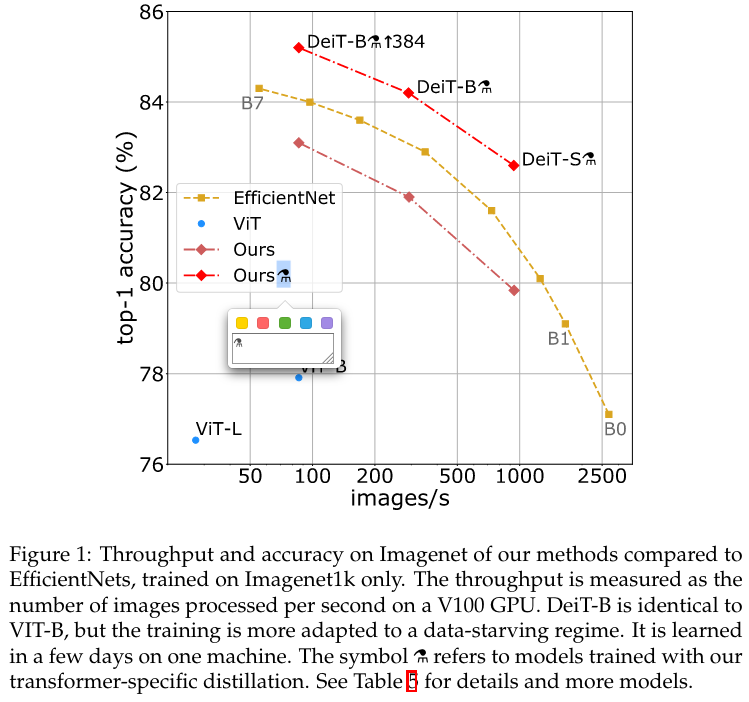
ViT 开启了 Transformer 应用于视觉的新篇章,但是在原始论文中,为了学到 Inductive bias,需要海量的训练数据 (ImageNet24K 和 JFT300M) 和计算资源,作者在本文中思考如何降低其对数据的需求量,同时加快训练速度。
进一步,作者提出了使用教师-学生蒸馏的方法学习 inductive bias 的策略。
从结果来看,作者训练 ViT 在 8 张 GPU 上,训练了 53 小时就得到了和 convnet 有竞争力的结果,作者称模型为 Data-efficient image Transformers (DeiT),并且给出了其以蒸馏方式得到的模型,为了区分,在缩写后面加上了一个新的符号:DeiT⚗
Methods
DeiT (非蒸馏)
DeiT 继承于 ViT 无卷积版本,与 ViT 的唯一区别就是训练策略的不同,这也是本文需要学习的部分。
DeiT(蒸馏)
作者给出了三种蒸馏模式,其中第三种蒸馏方法是本文新提出的
[! Note] Soft distillation Soft distillation [24, 54] minimizes the Kullback-Leibler divergence between the softmax of the teacher and the softmax of the student model.
[! Note] Hard-label distillation We introduce a variant of distillation where we take the hard decision of the teacher as a true label.
[! Note] Distillation token We add a new token, the distillation token, to the initial embeddings (patches and class token), as shown in Fig. 2
Distillation Token 和 CLS Token 的 loss 不同。可以认为,Distillation Token 也在某种程度上含有全局信息,同时作者发现,两个 Token 向着不同的方向收敛,它们在所有层的平均相似度是 0.06;如果按照单层考虑,随着层数的加深,它们会越来越相似,最后一层的输出为 0.93,作者认为”This is expected since as they aim at producing targets that are similar but not identical.”。而如果添加两个 CLS token 的话,他们最后一层的相似度为 0.999,说明两者基本完全一样,没有任何有效信息引入。
这里我感觉通过添加其他的token似乎可以比较自然的做解耦,两者都能够抽象出全局信息,在做 MSA 的时候会互相从对方中取得信息,利用 MSA 取信息能够保持信息的连续性,而不像 add 或者点乘一样破坏原始信息的连续性。
Experiments
DeiT 继承于 ViT 无卷积版本,与 ViT 的唯一区别就是训练策略的不同,这也是本文需要学习的部分。
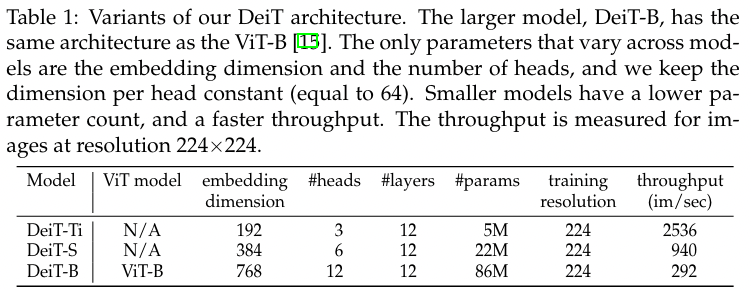
网络结构的超参数回顾(非蒸馏版本)
Token dimension () = 768
#heads = 12, leading to dim of each head input is = 64
引入两个模型 DeiT- S 和 DeiT-Ti,它们都只是改变了 num of heads
实验设置
初始化和超参数
Transformer 对于初始化十分敏感,对于优化器的超参设置也很敏感
- Initializing the weights with a truncated normal distribution[20].
[! Note] 优化器选择和优化器参数
- 预训练的时候必须选择 AdamW,当有一个好的预训练模型的时候,finetune 时两者使用 SGD 或者 AdamW 都行
- 学习率设置同 ViT 就行
- weight decay = 0.05 (ViT 中为 0.3),如果按照 ViT 中设置会影响结果
那我们是不是可以在一个数据集上训练的时候,先 AdamW 再 SGD?
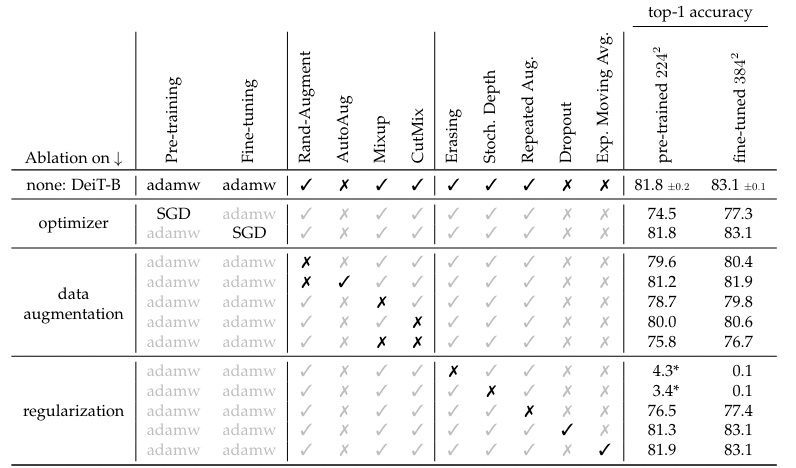
[! Note] 数据增强
- 数据增强可以使用 timm 提供的接口
- 作者最终使用的是 Rand-Augment 而不是 AutoAugment
- 实验显示数据增强太 tm 重要了,基本任何一个数据增强都是有用的
[! Note] 正则化
- 直接看上图第一行打对号的就行
- regulation 中感觉 Dropout 要不要都行,最后一个也是。实际上作者是没用 Dropout 的
- stochastic depth 有效,对于大的网络效果会更明显
- 作者说 Repeated augmentation 是一个显著提升结果的增强方法
蒸馏版消融实验
蒸馏版本 - 教师网络的选择
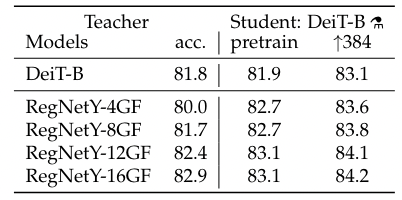
- convnet 能够提供 inductive bias,作为教师网络时能够显著提升结果
蒸馏版本 - 蒸馏方法的选择
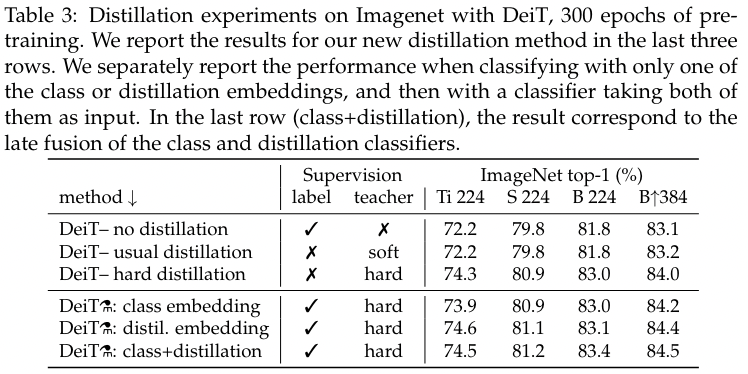 (上图中的最后三行的 embedding 表示使用对应的 token 进行分类预测)
(上图中的最后三行的 embedding 表示使用对应的 token 进行分类预测)
- Hard distillation significantly outperforms soft distillation for transformers, even when using only a class token
- Our distillation strategy from Section 4 further improves the performance, showing that the two tokens provide complementary information useful for classification
蒸馏版本 - Conv. 教师网络是不是让 ViT 学到了更多的 inductive bias?
虽然不能给出严谨正式的回答,但是作者比较了教师网络、学生 ViT 和普通 ViT 输出的不相似性来定性说明
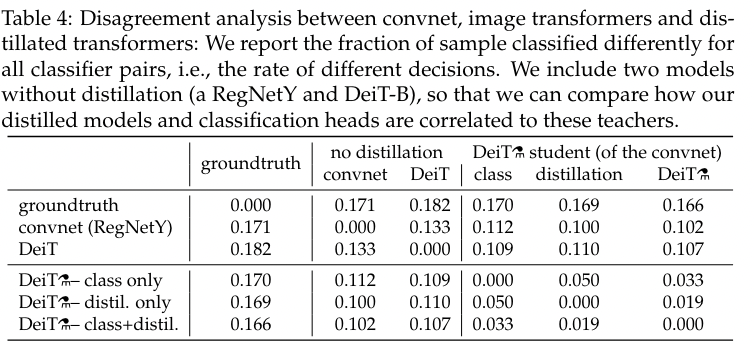
Some Descriptions
- “Convolutional neural networks have been the main design paradigm for image understanding tasks,” (Touvron 等, 2021, p. 1)
- “Recently Vision transformers (ViT) [15] closed the gap with the state of the art on ImageNet” (Touvron 等, 2021, p. 4)
- “KD can transfer inductive biases [1] in a soft way in a student model using a teacher model where they would be incorporated in a hard way.” (Touvron 等, 2021, p. 4)
- “In this section, we briefly recall preliminaries associated with the vision transformer [15, 52]” (Touvron 等, 2021, p. 4)
- “this a simple and elegant architecture that processes input images as if they were a sequence of input tokens.” (Touvron 等, 2021, p. 5)
- “This class token is inherited from NLP [14],” (Touvron 等, 2021, p. 5)
- “This architecture forces the self-attention to spread information between the patch tokens and the class token: at training time the supervision signal comes only from the class embedding, while the patch tokens are the model’s only variable input.” (Touvron 等, 2021, p. 5) 关于 cls token 的好描述
- “If not specified” (Touvron 等, 2021, p. 8)
- “The distillation token has an undeniable advantage for the initial training.” (Touvron 等, 2021, p. 10)
- “One exception is dropout, which we exclude from our training procedure.” (Touvron 等, 2021, p. 15)