Study on Reflection-Based Imaging Finger Vein Recognition
Links
- PDF Attachments: Zhang 等。 - 2021 - Study on Reflection-Based Imaging Finger Vein Reco.pdf
- Zotero Links: Local library
Contributions and Important Conclusions
- We construct a mobile reflection-based finger vein recognition system, which contains both software and hardware platforms.
- Based on the transfer learning technique, the author proposed a Domain Adaptation Finger Vein Network (DAFVN) to deal with illumination variations. This network is capable of narrowing the domain shift between different illumination data domains and extract illumination-invariant features from finger vein images in different illumination conditions.
- The first large-scale relection-based finger vein database is collected, namely SCUT Reflective Imaging Finger Vein database (SCUT-RIFV).
Some Descriptions
- The facial recognition system is vulnerable to replay attacks because the human face images are publicly available and thus easy to counterfeit.
- Natural light contains abundant infrared light with variable wavelength, which ineluctably traverse through the filter and influence the image brightness and quality.
Motivation
- Most existing finger-vein imaging systems adopt transmission mode, leading to more redundant space and uncomfortable user experience.
- With reflection mode, the open structure of the imaging device inevitably introduces extra illumination variation into the image, leading to performance degradion.
- (why transfer learning?) As probability distributions of data domains with different illumination conditions have discrepancies, features of the same finger in different domains vary a lot, which decreases the matching accuracy. Considering these data domains as the source and target domains, we apply transfer learning to narrow the distribution discrepancy between data domains with different illumination conditions, which results in an illumination-invariant feature space.
Summary of existing public finger vein databases

Methods
Hardware system
The prototype of this hardware is shown below.

The size of the headware is a comparative size as a smartphone.
The front portion of the device is a touch-type screen, while the backside is equipped with an HM2142 sensor with an 850nm filter. Meanwhile, two 850 nm NIR light sources with 90◦ beam angle are located around the sensor.
How to use? The users only need to hold it naturally and put their index fingers under the sensor while capturing images, as illustrated in Fig. 3(b).
Data collection Principle
Two parts:
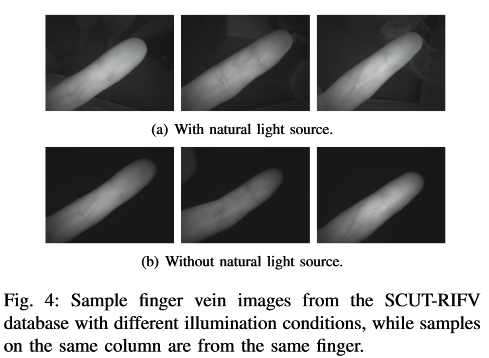
- (Natural) The first part is collected with natural light in 4 directions In this parts, collections contains 4 illumination directions with a natural light source on the front, right, left and back of the volunteer.
- (OnlyNIR) The second part is collecteted in a completely enclosed room environment without any natural light. In this part, the images are captured only under NIR light.
The auther think that part 1) simulate the indoor scene near a window and the outdoor scene in the daytime, the part 2) used to simulate night time scene realistically.
Can part 1) stimulate uneven natural ligth distribution?
As author paper says, there are only 4 directions evenly distributed around volunteers. But how to simulate uneven natural light distribution?
SCUT-RIFV Database
- 167 volunteers, with 57 females and 110 males.
- Only one session.
- Age range within .
- The index and middle fingers of both hands are provided, resulting in classes.
- The whole database is devided into two parts, namely Natural part and OnlyNIR part.
- In Nature part, there are 4 directions, each finger of each illumination direction captured 6 images. In OnlyNIR part, each finger is captured 24 images. Therefore, Nature part (4*6) = OnlyNIR part (24). In other words, a finger has 48 images.
In this case, the imblance data problem is alleviated by the authors.
- In totol, there are 32,064 images in the database.
- Gray-scale images in
.bmpformat with 640x480. - Volunteers slightly adjust the finger position before each image capturing, increasing the position variation in the SCUT-RIFV database. ( How silghtly? )

Image Per-processing
5 Steps
- Background clearance: An automatic threshold function is applied to calculate finger binary mask (Fig. 6(b))
- Location correction: The centroid of the connected domain of the finger in the mask is calculated to equal the finger centroid in the background clearance image. The finger would be moved until its centroid is at the center of the image, as demonstrated in Fig. 6(c).
- Angle correction: The finger center line is fitted according to the edge of the finger mask to calculate the angle between the finger center line and horizontal line.
- Knuckle detection: Calculating the average gray value of every column in the horizontal position of the upper portion of Fig. 6(d). Then a one-dimensional Gaussian filter is applied to smooth the average gray value. The local minimum of the average gray value line is retrieved by a sliding window to locate the knuckle.
- ROI extraction: Cropping the upper portion of Fig. 6(d) from fingertip to the second knuckle and leaving a little margin to retain more finger vein texture. The width of ROI is measured according to the width of the finger.
得到ROI的过程中没有填充或者拉伸的情况
Domain Adaptation Finger Vein Network (DAFVN)
Domain adaptation attempts to narrow the distribution discrepancy between a labeled source domain and an unlabeled target domain.
It’s essential to adopt a suitable metric method to measure the distribution similarity between the two domains.
Common metric-based approaches include Euclidean Distance, Kullback–Leibler (KL) Divergence, Jensen–Shannon (JS) Divergence, Maximum Mean Discrepancy (MMD) [33], Multi-kernel Maximum Mean Discrepancy (MK-MMD) [34], A-Distance, etc.
MobileNetV2 is chosen as backbone.
The author models the illumination variation problem as a domain adaptation problem and propose DAFVN that aims to reduce the domain shift between different illumination conditions. In other words, they want to narrow the distribution discrepancy and align the marginal distribution among them.
They setting the Natural part as the source domain and the OnlyNIR part as the target domain.
Details: Inspired by DAN [42], we modify a conventional MobileNetV2 and introduce two adaptation layers in the network to reduce the domain shift between different illumination conditions. We also calculate MK-MMD loss between these two layers as domain adaptation loss for model optimization, achieving the end-to-end training.

Training strategy
The author proposed a phase-wise training strategy.
As proved by Yosinski et al. [40], fine-tuning is the simplest and effective way of transfer learning.
Additionally, the features extracted from shallow layers are general and suitable to transfer, while the deeper layer features (high-level features) are more task-specific.
3 Steps:
- The conventional MobileNetV2 weights are randomly initialized, which is then first trained on the Natural part of SCUT-RIFV database until convergence. We denote this pre-trained mode .
- Use to initialize a new MobileNetV2, and freeze the first convolutional layer. Then fine-tune on the OnlyNIR part to obtain another per-trained model .
- is utilized to initialize DAFVN, then the first convolution layer and the first bottleneck of DAFVN is frozen. They fine-tune this DAFVN on the mixture of Natural and OnlyNIR parts images.
Besides, we set the feature space of the Natural part as the feature space on the source domain and the feature space of the OnlyNIR part as the feature space on the target domain. So we can calculate MKMMD between two domains with different illumination conditions, obtaining the illumination-invariant feature extractor.
Loss function
The loss function consists of two parts: the traditional classification loss and domain adaptation loss. We respectively utilize cross-entropy loss and center loss [47] as classification loss and MK-MMD loss as domain adaptation loss.
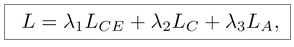 λ1 = 1, λ2 and λ3 are initialized as 0.0045 and 5, respectively.
λ1 = 1, λ2 and λ3 are initialized as 0.0045 and 5, respectively.
In the first and second step, only use classification loss
In the third step, use all losses.
The explanation of why to do so.
We design this training strategy with the following considerations:
- In the first step, the first convolution layer can learn the knowledge of multiple different illumination conditions from the Natural part. This layer is also highly transferable as it’s the shallowest layer of the model. Therefore, we freeze it in the rest of the steps to improve the robustness of the model to the illumination variations.
- In the third step, we further freeze the first bottleneck because it is transferred from the OnlyNIR part without illumination variation. Hence, it can avoid illumination influence and put more focus on finger vein texture information. In this way, the catastrophic forgetting problem while fine-tuning the model can be effectively alleviated by freezing the layers, which further improves the knowledge transfer efficiency.
- We utilize domain adaptation to narrow the distribution discrepancy between feature spaces of different illumination domains and extract the illuminationinvariant features.
- After training the final model on the mixed training set (Natural & OnlyNIR), we construct a multidomain distribution space, where the model can simultaneously learn discriminative features from both domains. We can also effectively excavate the complete label information from the target domain to regularize the discrepancy between different domains.
Experiments
- LR: 0.0005
- Bs: 64
- epoch: 300
- optimizer: Root Mean Square Prop (RMSprop) with a momentum of 0.9
Training Protocol
- Natural: All the training samples are picked from the Natural part to construct a distribution space with illumination variations.
- OnlyNIR: All the training samples are picked from the OnlyNIR part to construct a distribution space with stable illumination..
- Mixture: This training set contains samples from both Natural as well as OnlyNIR part to construct a multidomain distribution space.
Test Protocol
- Natural: Both samples of the testing pair are picked from the Natural part to simulate the situation of registration and identification with natural light.
- OnlyNIR: Both samples of the testing pair are picked from the OnlyNIR part to simulate the situation of registration and identification without natural light.
- Cross: Two samples of the testing pair are picked from different parts to simulate the situation of registration and identification with different illumination conditions.
The effectiveness of learned illumination-invariant features can be evaluated by computing the Equal Error Rate (EER) on the testing set.
- Mixture: This testing set contains all the three types of the aforementioned testing pairs to evaluate the comprehensive performance of the recognition system in different situations.
Independent Illumination Condition Experiments
这个实验为了证明光照差异确实会影响识别,亦即不同的光照条件属于不同的域。(证明文章模型的大前提,大假设存在)
实验一:根据光照方向(仅Natural Part)来划分训练与测试集
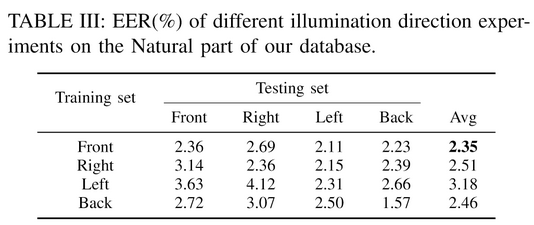
When the natural light source is in the front direction, the model achieves the lowest average EER on each testing set.
实验二:根据NIR光和自然光划分训练测试集
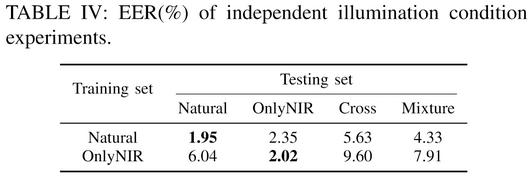
The model can only reach the lowest EER, when both training and testing sets are of the same type
Conclusion:
- The influence of natural illumination direction is trivial. (光照方向影响不大)
- The domain shift exists between data domains of Natural and OnlyNIR parts. As a result, illumination variation exactly influences the accuracy of the recognition system, indicating the necessity of our illumination-invariant feature extraction model.
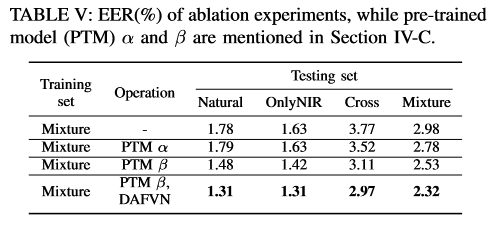
Ablation Experiments
see Table V
证明了backbone的有效性,证明了训练策略的有效性。
Comparsion with others
The traditional transmission-based methods, including RLT [13], Maximum Curvature [48] and DOCH [26], are directly applied on testing sets, as traditional methods are independent of the model trained on training sets while extracting features.
LBP and Gabor means using LBP and Gabor to process images, and the processed images are fed into MobileNetV2
We also compare our method with transfer learning-based methods, including DDC [41], Deep CORAL [50], DANN [51] and MME [52]. Similar to DAFVN, we utilize a conventional MobileNetV2 as a backbone network to modify other transfer learning-based methods.
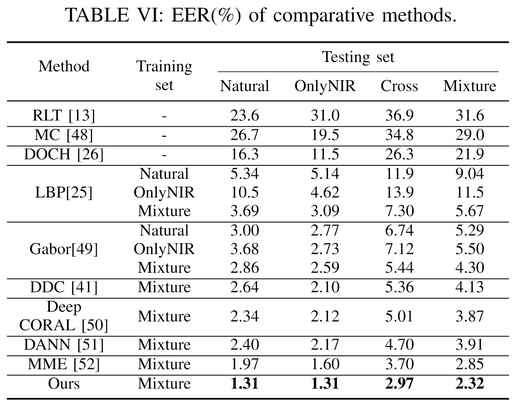
- Because of the low visibility of the vascular network in reflection-based finger vein images, these traditional methods provides high EERs on testing sets.
- LBP is unsuitable for illumination decoupling on reflectionbased finger vein images
- As for the Gabor filter, observing the fourth and fifth row of Table VI, EERs of models trained on Natural and OnlyNIR parts are similar, which implies that the Gabor filter can preliminarily decouple the illumination.
- All these transfer learning-based methods perform better than the traditional methods based on decoupling illumination techniques for eliminating domain shift.
In comparison to the results obtained on our reflection-based finger vein database, the methods based on transmission-based imaging principles have lower EERs on transmission-based finger vein databases. There are two major reasons for that. Firstly, the quality of a reflection-based finger vein image is worse vascular network of the finger is clear in the transmission-based image but nearly invisible in the reflectionbased image. Secondly, our proposed reflectionbased system is contactless with high degree of freedom
Visualization
