CvT: Introducing Convolutions to Vision Transformers
Links
- PDF Attachments: 2021’CvT_Wu et al_.pdf
- Zotero Links: Local library
- Official codes: GitHub - leoxiaobin/CvT
My Comments and Inspiration
本文的动机比较直观,就是想把卷积搞进去,分别通过向 MSA 中引入卷积(一个比较容易想到的策略)和对每个 block 的 reshaped tokens 进行卷积来赋予网络获取层次信息的能力。后一个想法比较有借鉴和思考的能力
下面是我的Inspiration
- 本文在 MSA 中引入了卷积,改变了 QKV 的获取方式,这是一个比较 naïve 的操作,能偶能复杂一点?
- 通过卷积在 reshaped token 上进行操作,赋予网络获取层次信息的能力,相比于 CeiT,作者可能比较深刻的意识到了 token 的维度和长度和 reshape 之后的特征图的对应关系 ( →token length, →token dimension),这种对应关系通过卷积进行操作后,那么基于这种关系,有没有其他的方法有同样的效果呢?
[! Note]- 文中可以学习的观点和表达
- 为什么在同等尺寸下 ViT 的表现不如 CNN 的表现? → “One possible reason may be that ViT lacks certain desirable properties inherently built into the CNN architecture that make CNNs uniquely suited to solve vision tasks.” (Wu 等, 2021, p. 1)
- How CNN capture the local structural? → By using local receptive fields, shared weights, and spatial subsampling [20]
- What is meaning of the hierarchal structure of CNN? → The hierarchical structure of convolutional kernels learns visual patterns that take into account local spatial context at varying levels of complexity, from simple low-level edges and textures to higher order semantic patterns.
Cores, Contributions and Conclusions
Cores
- 通过对每一个原始的 Transformer Block 的引入卷积操作,引入 CNN 的层次结构,利用卷积改变每一层输出的 token 的长度和维度。
- 利用卷积完成 MSA 中 QKV 的转换
Contributions
- 一个新的基于 Transformer 网络结构,引入了 CNN
- CvT 可以不适用 Position embedding 了
- 通过引入卷积来使得 CvT 获取到层次结构的功能
Conclusions
- 当就业 Transformer 的网络有一个可靠的能够获取空间位置信息的方法时候,Position embedding 是可以被忽略的
- 层次结构对于图像任务来说是重要的,主要是为了获取到 High-order semantic information.
Motivation
希望通过引入卷积,使得基于 Transformer 的网络有捕捉局部上下文信息的能力和获取层次信息的能力。
作者原文的引出有点奇怪
In this paper, we hypothesize that convolutions can be strategically introduced to the ViT structure to improve performance and robustness, while concurrently maintaining a high degree of computational and memory efficiency. To verify our hypothesizes, we present a new architecture
Methods
本文中,作者将 Conv. 引入到了 Tokenization 和 MSA 中的 Projection 里面
- 提出 Convolutional Token Embedding 替换原始的 Tokenization 过程
- 提出 Convolutional Projection 替换 MSA 中 Linear Projection 过程
Convolutional Token Embedding (CTE) 给定输入的 2D 图像或者第 i-1 个 stage 的输入(将这个 sequence token 按照实际空间位置进行 reshape 后):
- 这个 上直接进行卷积(kernel size = , stride = , padding = ),有
x_{i} = f(x_{i-1}) \in \mathbb{R}^{H_i\times W_i \times C_i}
其中 $H_i, W_i$ 都是正常卷积后计算得到的长度, $C_i$ 是可以预定义的 - 对得到的 $x_i$ 进行展平操作($[H_iW_i\times C_i]$,变回了 sequence token),并利用 LN 进行归一化作为本 stage 的输出送到下一个 stage > [! Note]- > 这里我们可以操作 $C_i$ 和 $H_iW_i$,实际上 $C_i$ 就是 token dimension,$H_iW_i$ 就是 sequence elength。 > 显然,通过 CTE 我们就可以不断增加 token dimension 同时减少 sequence length,这样类似 CNN 的层次结构就出来了 > > This gives the tokens the ability to represent increasingly complex visual patterns over increasingly larger spatial footprints, similar to feature layers of CNNs > 这里我们可以这么想:随着网络的加深,我们用更短的 sequence 能够表示浅层时的长 sequence,说明特征所包含的信息更多了,自然就需要我们增加每个 token 的维度。 **Convolutional Projection for Attention (CPA)** 该模块可以视为原始 Transformer block 在卷积上的扩展,可以用于捕捉 local spatial context 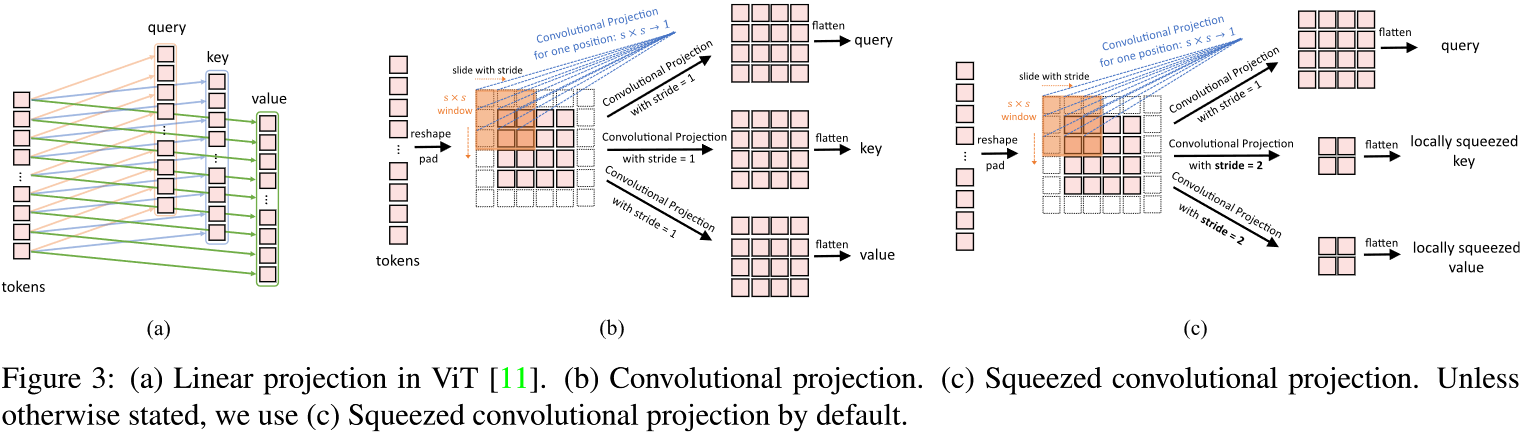 上图中后两个子图中的每个 Convolutional Projection 都是下面的前向过程\text{Depth-wise Conv2D → BN → Point-wise conv2D}
undefined