CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
Links
- PDF Attachments: 2021’CrossViT_Chen et al_.pdf
- Zotero Links: Local library
- Offical code: GitHub
My Comments and Inspiration
采用双分支的想法相对比较自然,但是如何融合才是本文的关键点。个人感觉本文的融合法相可能相对有点负责,并且实际上增加的参数量和计算量也不能说是“可以忽略的”
- CLS Token 可以认为是提取当前序列的全局抽象信息的特征
- CLS Token 十分重要
- 如何使用一个当查询,另外两个当做 key 和 value 的来源,其计算的方式需要理解和掌握,最好尝试解释其物理意义
- 这种分支融合,实际上可以作为未来多视角指静脉识别中的融合,不过为了减少参数量,我只能使用一个 Tramsformer 进行特征的提取啥的。
Preface
- ViT 需要非常巨大的数据进行训练:ImageNet24K 和 JFT300M
- DeiT 证明了合适的数据增强和正则化能够让 Transformer 在更少的数据上训练得到很好的表现。
Goal
- 如何在基于 Transformer 的网络中学习多尺度信息
Motivation
- 有很多文献[5, 4, 22, 21, 25, 24, 7]已经证明,有 CNN 应用的视觉任务中,多尺度信息是十分重要的。但是多尺度信息对于视觉 Transformer 的作用却尚未证实
- 受到多尺度 CNN 的一些工作启发,如 Big-Little Net 和 Octave convolutions,作者也设计了一个有多分支的视觉Transformer
Contributions
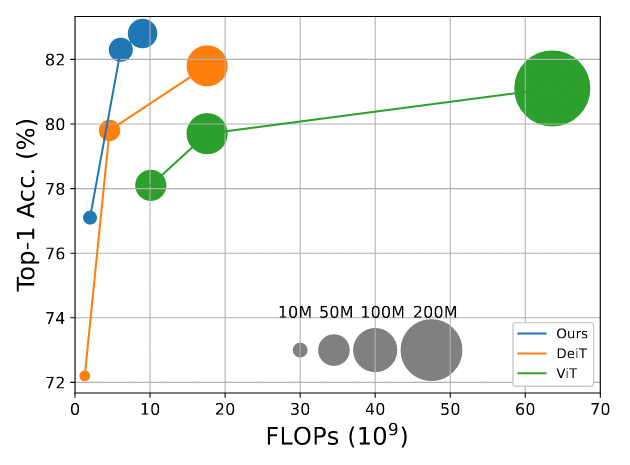
- 设计了一个双分支的基于 Transformer 的网络
- 设计 Cross Attention 机制,用来将两个分支上的特征进行融合,该机制有着线性的计算复杂度
- 相比于 DeiT,模型参数和计算量略有增加,但是结果远超其 2%
Methods
CrossViT 是基于 ViT 改进的。
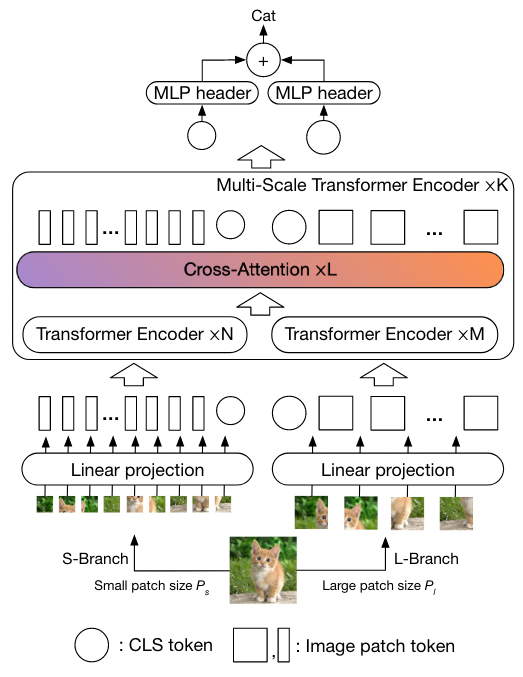
- 整个网络是由前面的预处理 (patch embedding) + K 个 Multi- Scale Transformer Encoder 堆叠而成
- 每个 Multi-Scale Transformer Encoder 含有两个分支,分别用来处理不同 patch size 的 token,并通过 Cross-attention 机制将两个分支的信息进行融合
- 注意一个 MSTE 内的处理不同 patch size 分支的 transformer encoder 的数量是不同的(上图 N 和 M),这是为了平衡计算量。
多分支结构
-
L-Branch:a large (primary) branch that utilizes coarse-grained patch size () with more transformer encoders and wider embedding dimensions.
-
S-Branch: a small (complementary) branch that operates at fine-grained patch size () with fewer encoders and smaller embedding dimensions.
-
times fusion: Both branches are fused together times.
-
The CLS tokens of the two branches at the end are used for prediction.
Multi-Scale Feature Fusion
作者认为,有效的特征融合是学习多尺度信息的关键因素。
接下来,作者给出了三个启发式的方法和一个新提出的 Cross-attention 方法(不知道为啥说是启发式的方法)
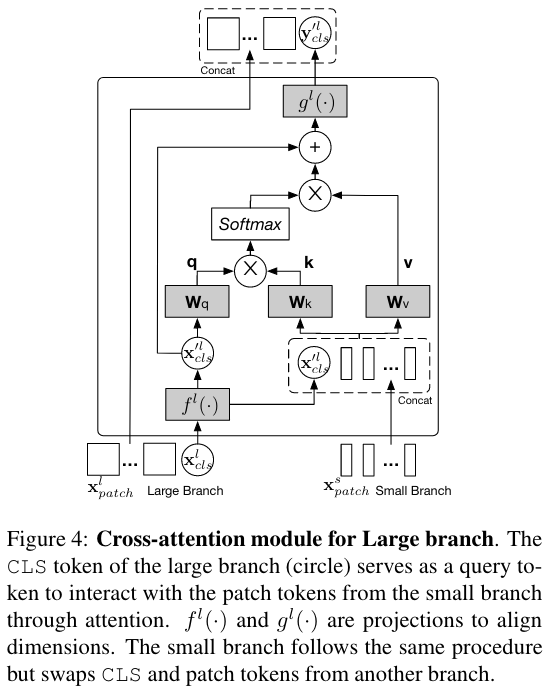
[! Note] Cross-Attention Fusion 作者认为,每个分支的 CLS Token 能够表示该分支的抽象全局信息,所以就是用每个分支的 CLS Token 先和另一个分支里的 Patch tokens 发生交互,然后回来再跟自己分支的 Patch tokens 发生交互,这样就完成了融合。
我们拿 Large 分支来举例并概述流程,如下图
- 把 L 分支的 CLS Token 单独拿出来,经过一次维度对齐后,和 S 分支的 Patch tokens 进行拼接,记为
- 在 和 之间做 Cross Attention (CA),具体操作为:以 做 Query 信息,以 做 Key 和 Value 信息进行自注意力运算 (特点:引入多头,称为 MCA;在 MCA 之后不引入 FFN)
上面提到的 CA 操作可以写成
- 最后,我们将新的 CLS Token 的维度映射回原来的维度,再和自己 L 分支的 Patch tokens 进行拼接即可
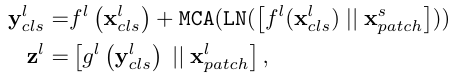
PS:上面只是举了 L 分支的例子,S 分支是同理的。
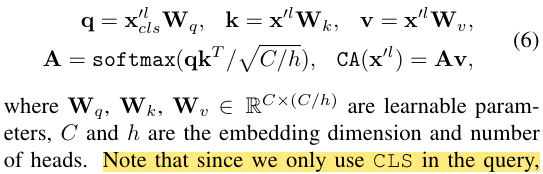
[! Note]- All-Attention Fusion 将两个分支的输出的 Tokens 进行拼接,然后经过一个 MSA 进行融合。
此方法的计算量最大
❓为啥 有两种计算方式?
[! Note]- Class Token Fusion 由于 CLS Token 可以视为每个 branch 的全局抽象特征表示,并且也会用于最后的预测。因此直接将两个 Branch 的 CLS Token 相加。
此方法计算量最小
[! Note]- Pairwise Fusion 由于每个分支的 patch tokens 都可以 reshape 回到一个空间排列,即每个 token 都对应一个空间位置,通过这种对应关系完成融合
- 由于两者具有不同的数量的 tokens(空间尺寸不同),首先通过差值对齐两个分支 tokens 的空间尺寸
- 按照对应位置 (pair-wise fusion) 进行融合
- CLS 独立融合
❓为啥还是 cat 的数学符号?
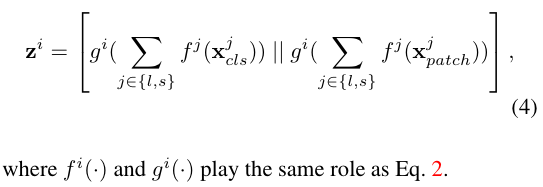
网络结构
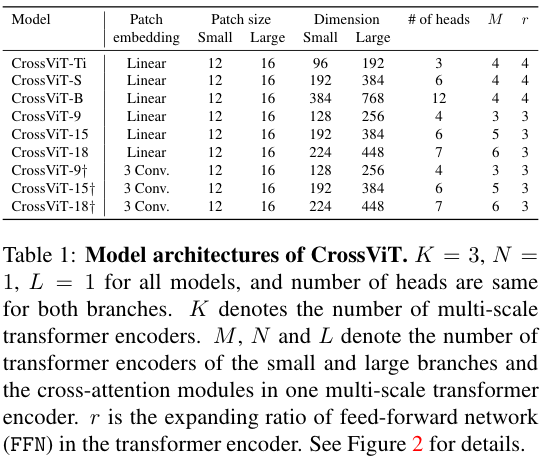 上标十字表示引入了混合结构,将 linear patch embedding 换成了 3 层卷积层
上标十字表示引入了混合结构,将 linear patch embedding 换成了 3 层卷积层
Experiments
实验设置
- ImageNet 1K,transfer on CIFAR10 and 100
- 实验设置基于 DeiT,默认参数设置同 DeiT
- Data augmentation: rand augmentation[8], mixup, cutmix[46], random erasing[49]
- Drop path
- Epochs = 300
- Bs = 4096
- Lr = 0.004
- Cosine linear-rate scheduler with linear warm-up, 30 warm -up epochs
- Weight decay = 0.05
与 Baseline (DeiT) 和主流的 Transformer 工作比较
DeiT [35] is a better trained version of ViT
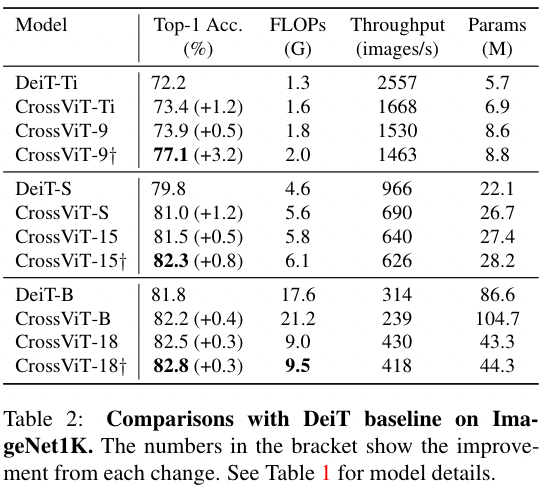
- 卷积做 tokenization 能够带来显著的性能提升
- 在增加了部分计算量的情况下,CrossViT 比 DeiT 结果更好(计算量也增加了一些)。同时我们也能看到,当参数量增加时,引入卷积所带来增益会减少,但是依然会带来提升。
参数量较小的 Transformer,或许从 patch embedding 就引入卷积有就会有可观的性能增益
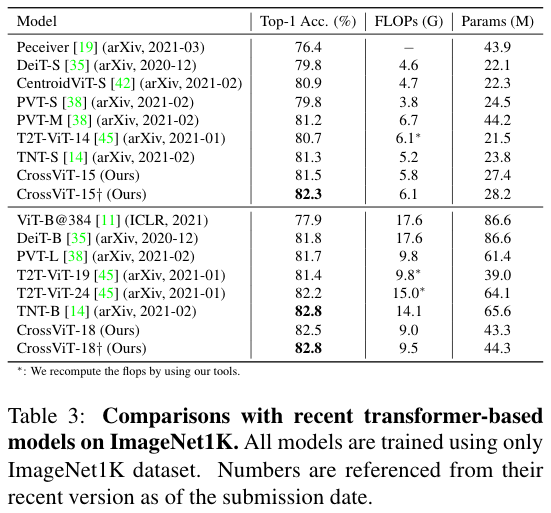
- CrossViT 效果最好,这里应该是直接 cite 他们的结果。
和 CNN 比较
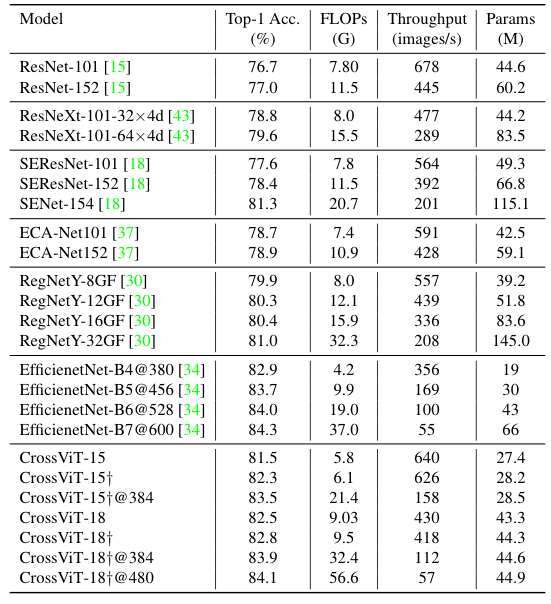
- 依然没比过 EfficientNet (EfficientNet 这么牛逼吗),同尺寸输入下比过了或者差不多。
消融实验
比较不同的双分支融合策略
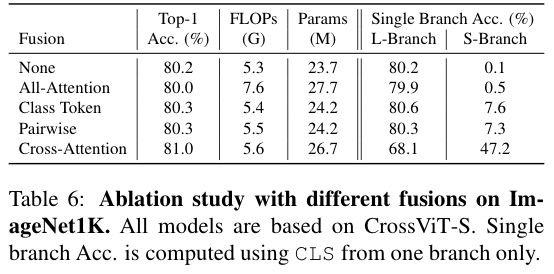
- 除了 CA,所有的方法(即使不含 fusion 的 naive )在单独使用 S 分支时结果稀烂。
- 使用了 CA 后单独 S 分支的表现大幅提升,但是 L 分支的下降
这是为啥?
Patch size 的影响 & S 分支的通道宽度和深度 & CA 的深度和 MSTE 的数量
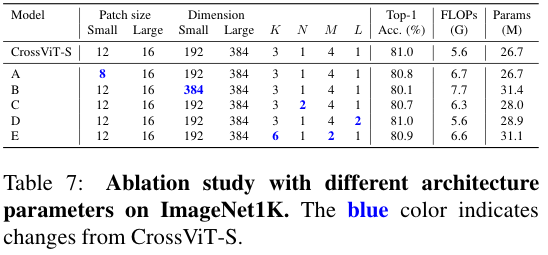 比较 Patch size 的影响:看 A 和 baseline
比较 S 分支的通道宽度和深度:看 B 和 C 和 baseline
比较 Patch size 的影响:看 A 和 baseline
比较 S 分支的通道宽度和深度:看 B 和 C 和 baseline
Both models increase FLOPs and parameters without any improvement in accuracy, which we think is due to the fact that L-branch has the main role to extract features while S-branch only provides additional information; thus, a light-weight branch is enough.
比较 CA 的深度和 MSTE 的数量:看 D 和 E 和 baseline
- 频繁的进行 CA 不会有效果的提升,会引入更多的计算量和参数。这是因为 CA 是线性操作(未引入非线性函数),堆叠 CA 太多意义不大。
- 类似的,使用更多的 MSTE 也不会提升整体的表现,这可能是由于 S 分支限制了整体的表现。
CLS 的重要性 去掉 CLS,直接掉 1 个点,说明 CLS 确实是很重要的,作者认为它保留了全局的抽象整体信息。
CA 的有效性 作者将 CA 与 T2T 进行了融合,并且替换其中对应的部件,有 0.5 的效果提升,说明 CA 模块是有效的。
更多实验分析在文章的补充材料中
Some Descriptions
- The novel transformer architecture has led to a big leap forward in capabilities for sequence-to-sequence modeling in NLP tasks.
- The great success of transformers in NLP has sparked particular interest from the vision community in understanding whether transformers can be a strong competitoragainst the dominant Convolutional Neural Network based architectures (CNNs) in vision tasks
- Along the same line of research on building stronger vision transformers, in this work, we…
- Our proposed approach outperforms DeiT [35] by a large margin of 2% with a small to moderate increase in FLOPs and model parameters
- a simple yet effective token fusion scheme
- Our approach performs better than or on par with several concurrent works based on ViT, and demonstrates comparable results with EfficientNet with regards to accuracy, throughput and model parameters
- Here, we focus on some representative methods closely related to our work.
- It is worth noting that. 值得一提的是
- The granularity of the patch size affects the accuracy and complexity of ViT; with fine-grained patch size, ViT can perform better but results in higher FLOPs and memory consumption. 如何变着法的描述一个 patch size 对于结果的影响
- coarse-grained patch size 粗粒度的 patch size
- fine-grained patch size 精细粒度的 patch size
- Here we experiment with a similar idea by substituting the linear patch embedding in ViT by three convolutional layers as the patch tokenizer.
- We further compare our proposed approach with some very recent concurrent works on vision transformers.
- They all improve the original ViT with respect to efficiency, accuracy or both.