ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
Links
- PDF Attachments: 2021’ConViT_d’Ascoli et al.pdf
- Zotero Links: Local library
- Official codes: GitHub
My Comments and Inspiration
Preface
- ViT 依赖于更灵活的 SA 层,但是为了得到理想的表现,需要在巨大的外部数据库上进行预训练,或者从预训练的 CNN 中进行蒸馏。
- Inductive bias 是 CNN 结构的内在固有特点,来自于对权重的两个强约束:locality and weight sharing。
[! Note]- CNN 的平移等变性和平移不变性1
- 平移等变性:对于卷积操作来说,指的是图像中物体移动对应的距离,在输出中也会移动同样的距离(此时必须 without pooling layers)
- 平移不变性:对于 CNN 来说,pooling layers 的引入,能够让 CNN 面对输入作出少量平移时,池化能帮助输入的表示近似不变
- 卷积并不具有旋转和放缩的不变性
- The practitioner is therefore confronted with a dilemma between using a convolutional model, which has a high performance floor but a potentially lower performance ceiling due to the hard inductive biases, or a self-attention based model, which has a lower floor but a higher ceiling.
Goal 将 Conv. 和 SA 两种结构进行结合,扬两者长,避两者短。
Contributions
- 本文提出了一个新的 SA layer 的形式,称为 gated positional self-attention (GPSA)。GPSA 能够在训练的过程中逐渐学习是模仿 Conv. 还是 Self-attention operation.
Background
Refer to @cordonnier2020relationship
最重要的一个来自于 @cordonnier2020relationship 的结论:带有 positional attention 的 SA 层严格模仿一个卷积层
并且我们需要明确,标准的 SA layer 是位置模糊的,他们并不能知道每个 Patch (Token) 的空间位置。为了让 SA layer 能够获取到位置信息,有两种路径: ① 在最开始输入时 patch embedding 时,添加某些位置编码信息 ② 将标准的 SA layer 替换成 positional self-attention (PSA) layer。
PSA Layer 在 PSA 中,通过引入 q 和 k 的相对位置编码 用来表示该 query q 和某个 key k 的相对位置关系。
其中 表示 head 的 Attention probabilities 上 位置的值,即第 i 个 query 和第 j 个 key 之间的关系,必然是个标量。同时,每个 head 都会使用一个可学习的 position embedding 和一个相对位置编码 ,它仅和 pixel 与 pixel 的相对距离有关,记为一个二维的向量 (对于同样的 ij,它是固定的)
PSA Layer performs like CNN @cordonnier2020relationship 中提到,上述 PSA layer 中当 时,并满足如下的设置,是可以严格模仿任何一个卷积核尺寸为 的卷积层的:
其中,
- 注意力中心(Center of attention) 是 head 所关注到的相对于 query 的位置(是相对位置)。 如下图 c 中,4 个 head 的注意力中心分别是
- 局部强度 (locality strength) 表示 head 所关注的区域有集中于它的中心 。当 越大,说明关注的范围约集中于它的中心;反之,head 关注的范围就越大
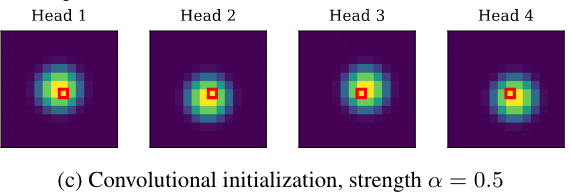
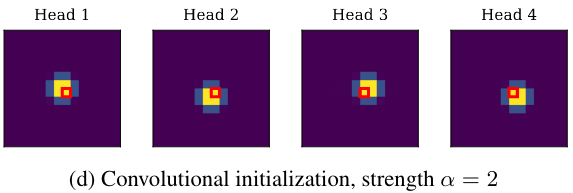
基于上述工作,如果能够设置注意力中心 (center of attention) 为一个 卷积核的每一个位置偏移,并设置一个较大的局部强度 ,即可严格模拟卷积层。
Methods
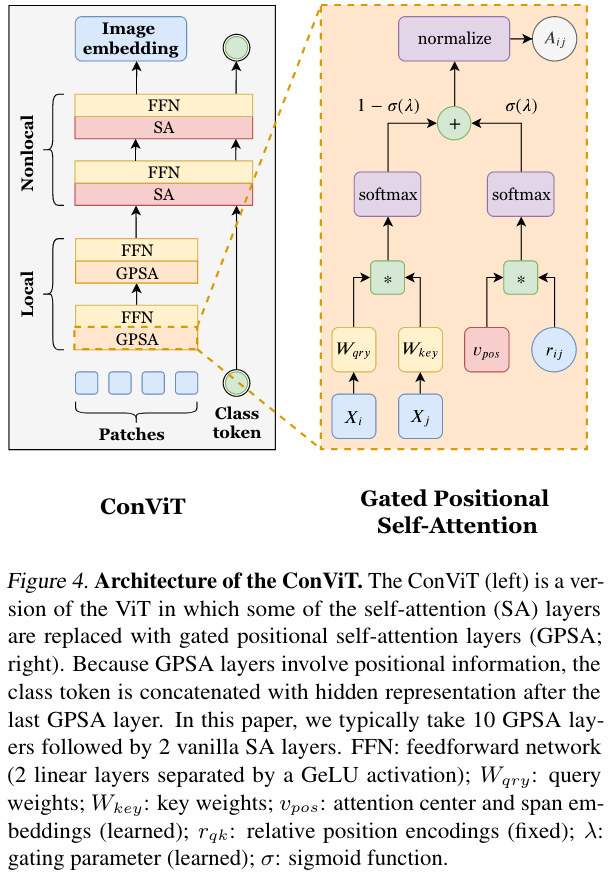
有了上述的背景之后,作者提出了 Gated positional self-attention (GPSA) layers,通过按照卷积的设置(即上面的公式)对其进行参数初始化,然后在学习的过程中,由 GPSA 自己决定是否保留卷积(就是按照卷积进行初始化后,就不管了,学成什么样是什么样)
然而原始的 PSA 的初始化有两个局限,作者对此进行了改进
1. Adaptive attention span
由于 relative positional encoding 的数量是和 patch 数成平方关系的,因此 PSA 中搞进来了很多训练参数。
本文中,作者固定 relative positional encoding ,只训练一个 embedding ,用来决定每个 head 的 center 和 span2 。它的初始化值有前面的公式决定,并设置 来避免使用 0 值。而由于 ,整体参数量增加的可以忽略。
[! question] (span 是什么?是范围吗,alpha 决定的那个?)
2. Positional gating
PSA 的公式 ,其 Softmax 内的两项可能潜在的具有不同的幅度 (强度,或者说值可能不在一个数量级),这将会导致 softmax 可能会忽略其中的最小的值。
事实上,作者通过对标准 PSA 按照卷积的设置进行初始化实施了实验:训练的早期能够提升表现,但是到了后期,注意力机制会偷懒而忽略内容信息(),说明内容的值会变得很小。
为了避免这种情况,作者将 content 和 positional 项先分别经过 softmax 后再进行想加,并引入门控参数(gating parameters) 来对控制不同项的重要性(即加权)。最后再对加权求和得到的矩阵进行归一化,来保证输出的 attention score 表示的是概率分布(同行和为 1),GPSA 定义如下
其中 (按行归一化), 是 sigmoid 函数。
[! Note] 当初始化 GPSA 的时候,设置 为一个非常大的数字,此时有 : 即 GPSA 此时只关注对应位置的像素,而不需像卷积设置一样显式地设置 和 为 。同时,作者为了避免 ConViT staying stuck at ,将所有 head 的 都设置为
3. 其他细节
CLS Token
ViT 里采用标准 SA,所以在最早开始将 positional embedding 直接加到了每个 patch embedding 上,过程中不在涉及到 positional embedding。
而在每一层的 PSA 中,由于每个 token 都会涉及到 positional attention,它们就不再提前添加 CLS Token 了,所以作者通过 CLS token 添加到最后一个 GPSA layer 的输出中来解决这个问题(网络最后跟着俩 SA 层,看最上网络图)
fine-tune on higher resolution
因为文中学习了一个关于位置的 embedding (shared across heads),然后通过一个相对位置编码 相乘得到的。因此对于其他的分辨率,只要根据公式 ^4fe6ca 对相对位置编码 进行重采样即可(因为 已经学习好了)
网络结构
The ConViT is simply a ViT where the first 10 blocks replace the SA layers by GPSA layers with a convolutional initialization.
Experiments
训练细节
-
Based on DeiT, a hyperparameter-optimized version of ViT.
-
To mimic 2 × 2, 3 × 3 and 4 × 4 convolutional filters, we consider three different ConViT models with 4, 9 and 16 attention heads
-
为了让和比较的模型有差不多的参数量(model size,作者主要从这个层面设置比较模型的,没有过多关注 FLOPs),作者进行了 i 下面 2 个设置:
- Lower the embedding dimension of the ConViTs to instead of used for the DeiTs (applied for ConViT-Ti, ConViT-S and ConViT-B.).
- 为了确定 ConViT 表现的提升不是由于 head 数量的提升,作者也设置相同的 head 数和 , 在模型后添加”+“来指示
-
bs = 512
-
lr = 0.0004
ImageNet Classification
epoch = 300
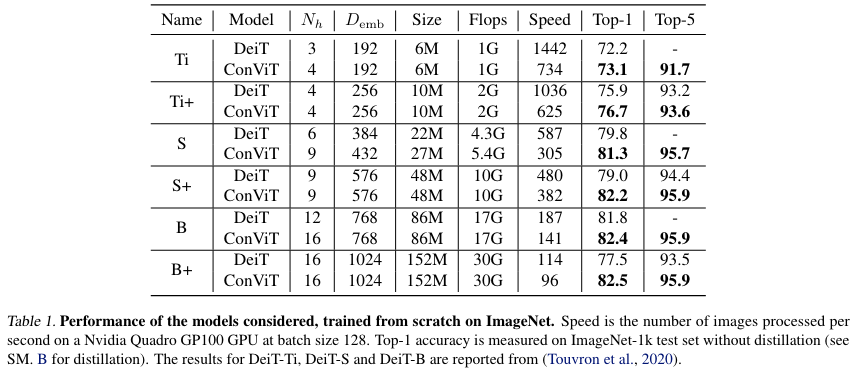
- ConViT 速度更慢了,但是结果上升,即 PSA 会拖慢速度
- ConViT 已经可以和蒸馏的模型媲美了,说明抓 inductive bias 的能力更强。
Sample-efficiency of the ConViT
通过对 ImageNet-1K 进行数据比例 的采样,改变 来保证模型看到的图像总数不变。
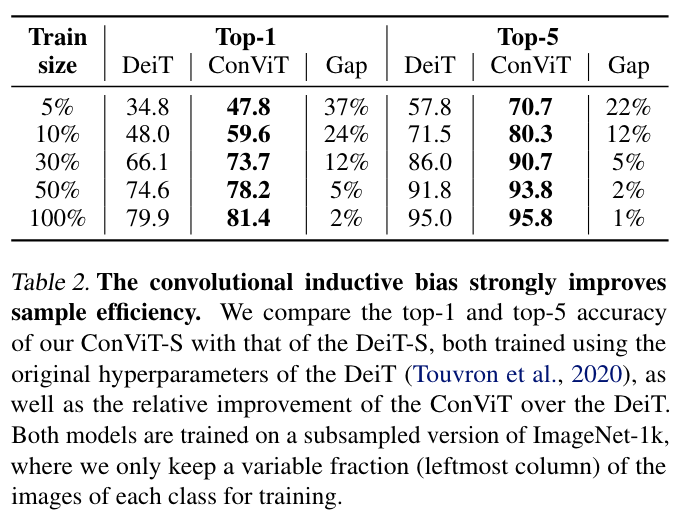
- 说明在小的数据库上,conv. Inductive bias 十分重要!
局部性的作用和体现
SA layer 和 PSA leayer 对于局部信息提取的倾向
作者想研究,看看 ViT 里的标准 SA layer 在不能从 position attention 中受益时,是不是像 PSA layer 一样天然的鼓励趋向于提取局部信息
衡量指标:A measure of “nonlocality”,通过求和每一个 patch 和所有 key 的距离 与其对应 Attention score 的乘积(类似加权求和,权是 attention score)。对于每个 head 来说,计算所有 query patch 的平均值作为衡量这个 head 的 nonlocality 的指标;对于每一层来说,取所有 head 的平均值。
is the number of patches between the center of attention and the query patch: the further the attention heads look from the query patch, the higher the nonlocality.
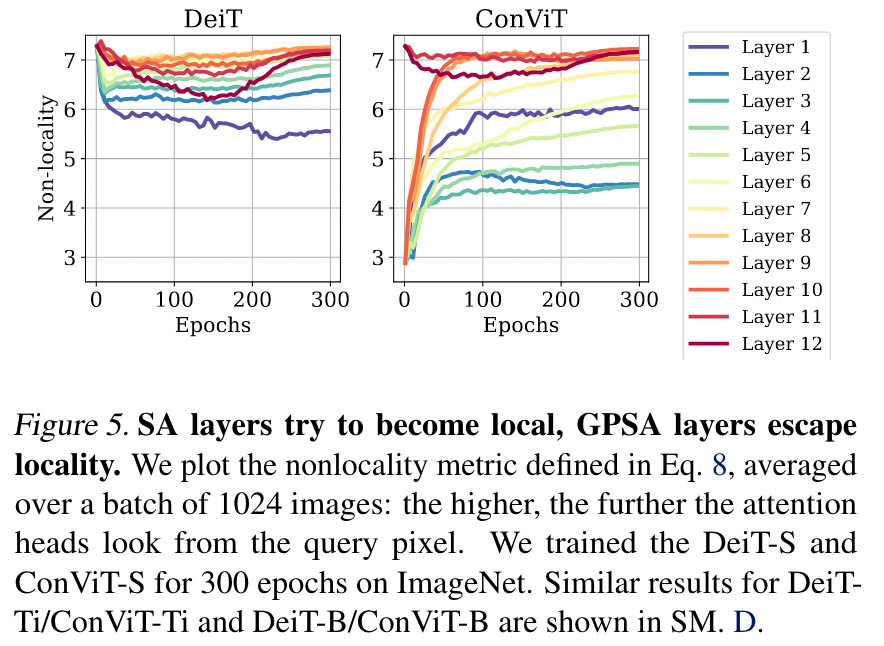
- 从 DeiT 的结果看,训练开始的阶段,大部分的 layer 都 nonlocality 指标都迅速下降,说明趋向“卷积化”
- DeiT 和 ConViT 都是浅层的时候更多的模仿卷积,即关注局部信息,而深层时,会捕捉更多的全局信息。
有一个奇怪的点是,ConViT 第一层反而并不是最局部的,而 2、3、4 都会比其更局部一些。这里能否认为,模型先”观察”一下整体的图像,看看考虑自己应该先关注”多局部”的信息。
GPSA 层对于卷积的逃逸作用 因为 GPSA 以初始化的方式赋予其强卷积模仿能力,作者设计本实验观察 GPSA 层有多大的程度摆脱”卷积”,去学习全局信息。
- 从上一个实验的右侧图像我们可以看出,第一层和最后一层 PSA 都在强烈的逃脱卷积的束缚,去捕捉更全局的信息。
此外,作者计算 ConViT 的每层所有的 gating paramater 的值,来观察不同层对于 content attention 和 position attention 侧重情况(根据公式知越大越关注 position attention)。
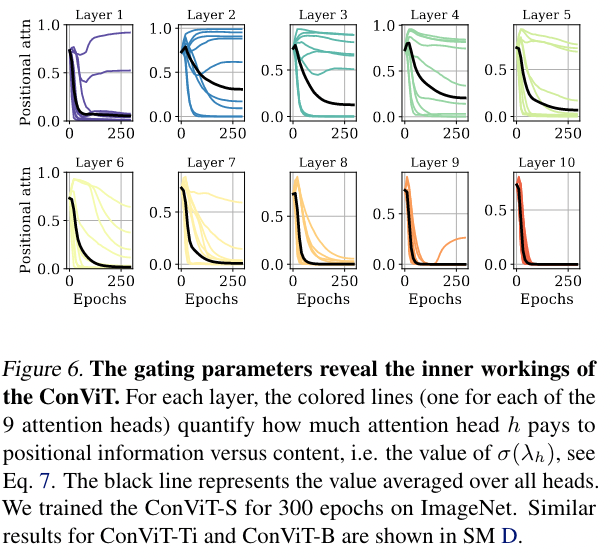
- 随着训练 epochs 的加深,网络对于 position information 的关注越来越低,说明所有的层都在尝试逃脱卷积的限制
- 而 6-10 层的 gating parameter 降低接近于 0,说明此时 PSA 已经部分忽略了 position information;而 1-5 层都还保留了一些对于 positional information 的关注,即利用了位置信息。
- 作者附录的实验有一个有趣的现象:ConViT-Ti 只有前 4 层利用了位置信息 明显大于 ,而 ConViT-B 的前 6 层却都能利用上。这说明大模型更需要、且更受益于 conv. prior。
接下来,为了展示其内部的工作情况,下图展示了 ConViT 的 attention map。
[! Note]- how to get this figure obtained by propagating an embedded input image through the layers and selecting a query patch at the center of the image3.
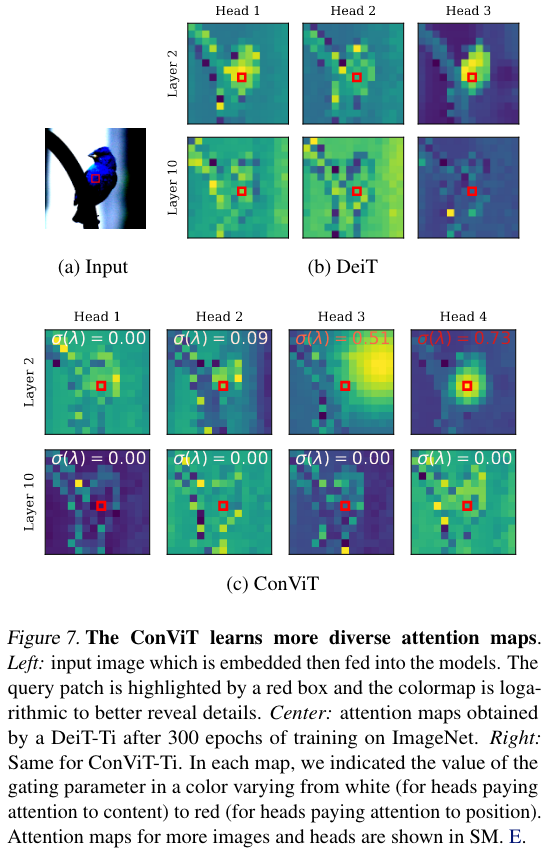
The inner workings of the ConViT are further revealed by the attention maps of Fig. 7, which are obtained by propagating an embedded input image through the layers and selecting a query patch at the center of the image3. In layer 10, (bottom row), the attention maps of DeiT and ConViT look qualitatively similar: they both perform content-based attention. In layer 2 however (top row), the attention maps of the ConViT are more varied: some heads pay attention to content (heads 1 and 2) whereas other focus mainly on position (heads 3 and 4). Among the heads which focus on position, some stay highly localized (head 4) whereas others broaden their attention span (head 3).
强局部性先验非常重要 这里作者调查了 locality strength 和 GPSA layer 的层数(替换对应的 SA layer)这两个参数对 ConViT 的表现的影响
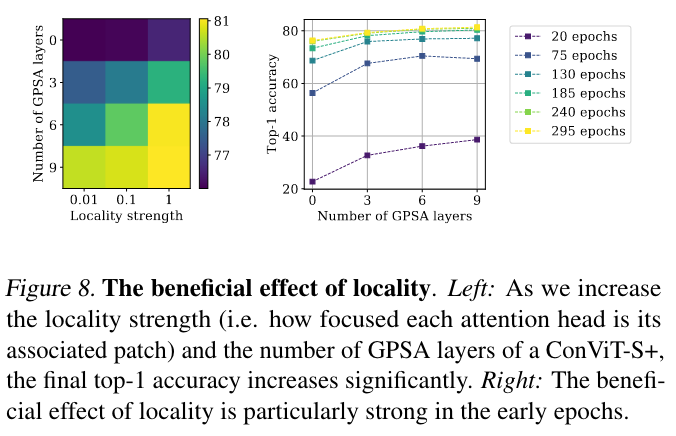
- 卷积先验越多,结果越好 (左图)
- GPSA 越多,施加的,前期获取的收益越明显,9 个相比于 0 表现接近 double 了,这说明卷积设置的初始化能够带来实质的“领先优势 (head strat)”,这也就解释了为啥数据量小的时候能够带来很好的结果。
消融实验
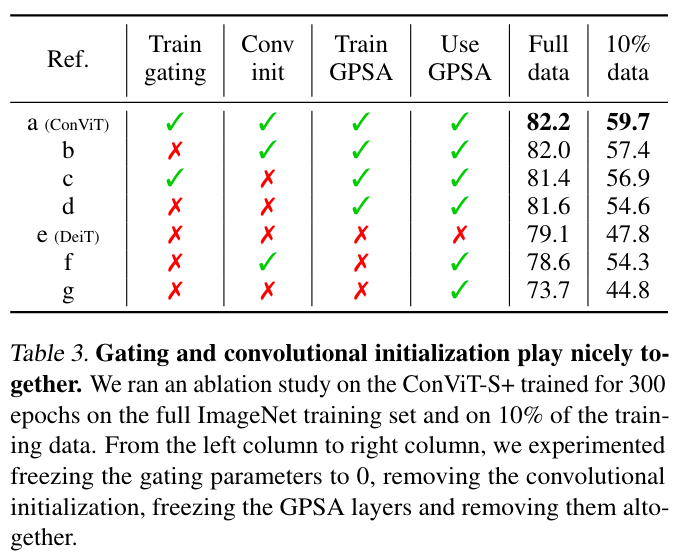
- [d] vs [e] 说明 GPSA 的表现比 SA 要好,即使仅仅是替换,而没有采用卷积设置的初始化,也能提升两个多点,非常明显。而采用了卷积初始化后 ([b]),能继续提升;然而注意的是,一旦使用门控而不卷积初始化,反而会轻微掉点,或者说影响不大(看 10%的数据,也会有提升,说明 gating 再全尺寸数据上影响不大,小数据上还是有影响的)
- 如果 + gating 也 + conv init,效果再次明显提升(全尺寸数据和小尺寸数据)
- [f] GPSA 卷积初始化,[g]的 GPSA 随机初始化,两者但是 freeze GPSA 层,只训练 FFN 层,可以看到 f 的提升非常明显,说明使用严格的卷积先验能够带来非常明显的结果的提升,在数据量较小的时候,这种情况更加明显。
“This naturally begs the question: is attention really key to the success of ViTs” (Ascoli 等, 2021, p. 9)
Some Descriptions
Footnotes
-
Sukhbaatar, S., Grave, E., Bojanowski, P., and Joulin, A. Adaptive attention span in transformers. arXiv preprint arXiv: 1905.07799, 2019. ↩