Incorporating Convolution Designs into Visual Transformers
Links
- PDF Attachments: 2021’Incorporating Convolution Designs into Visual Transformers_Yuan et al_.pdf
- Zotero Links: Local library
- Codes: paperwithcode
My Comments and Inspiration
- 本文在 FFN 处引入卷积的操作比较有意思,通过 reshape + 卷积 的方式直接对 Token 进行操作
- 在应用卷积的时候,尽量保证 Conv +Pooling +BN 一起使用,最次也要有 Conv+BN,能够收获不错的结果(但是本文没有比较其他的归一化方法对于 Conv 的影响,注意接下来可以关注一下)
- 文中将卷积引入到了 FFN 和 Tokenization 中,而 CvT 是将卷积引入到了 MSA 中,结合文中提到的部分,还有一个 Encoder 部分,是不是有工作已经尝试将卷积引入到这里呢?我能不能尝试呢?
[! Note]- 文中可以借鉴的描述
- “Looking back to the convolution, the main characteristics are translation invariance and locality [22, 32]. Translation invariance is relevant to the weight sharing mechanism, which can capture information about the geometry and topology in vision tasks [23]. For the locality, it is a common assumption in visual tasks [11, 26, 9] that neighboring pixels always tend to be correlated.” (Yuan 等, 2021, p. 2)
- In CNNs, as the network deepens, the receptive field of the feature map increases. Similar observations are also found in ViT, whose “attention distance” increases with depth.
Cores, Contributions and Conclusions
Cores
- 在 Tokenization、FFN 两个部分分别引入卷积操作,希望能够带来卷积的一些比较好的性质。Tokenization 部分直接引入一个 conv. block 来获取 input token,FFN 则插入了 Depth-wise conv.
- 提出了 Layer-wise Class token Attention 操作 (不是很重要),将之前所有的 Transformer block 的 CLS Token 输出在最后汇总,进行一次 MHA 的操作,得到最终的 CLS Token
Contributions
- 提出了一个新的基于 Transformer 的 Backbone——CeiT。分别在 Tokenization 和 FFN 处引入了卷积操作,获取到了卷积的 locality 的能力并且保留了 Transformer 中的长距离依赖。
- 提出了一个简单的 LCA 操作,汇聚所有 CLS Token 的结果并考虑不同层的 CLS Token 的关系(做一次多头自注意力)
- 实验结果表明,CeiT 相比于纯 Transformer 在相同的数据库上有 3x 的收敛速度,训练速度更快。
Conclusions
- 直接引入 CNN 能够获得更好的 Inductive bias,同时学习的效率变得更高,体现在收敛更快上(和 DeiT 进行比较)
- 在应用卷积的时候,尽量保证 Conv +Pooling +BN 一起使用,最次也要有 Conv+BN,能够收获不错的结果
Motivation
- 纯 Transformer 没有 CNN 结构中固有的先验 (inductive bias)
- ViT 中很难提取到图像的 low-level features,These low-level features are from some fundamental structure in images.
- Self-attention modules focus on the extraction of long-range dependencies among tokens,ignoring the locality in the spatial dimension.
Methods
- 为了能够让基于 Transformer 的网络获取到 low-level 的信息,作者在进行 Tokenization 时引入了 Conv. Block 来进行
- 为了更好的引入 CNN 的 inductive bias,作者在 FFN 里插入了 CNN 结构
- 最后一个小的改进,提出 LCA 模块汇聚所有层的 CLS Token 的输出并进行多头自注意力
Tokenization (Image-to-Tokens, I2T Module)
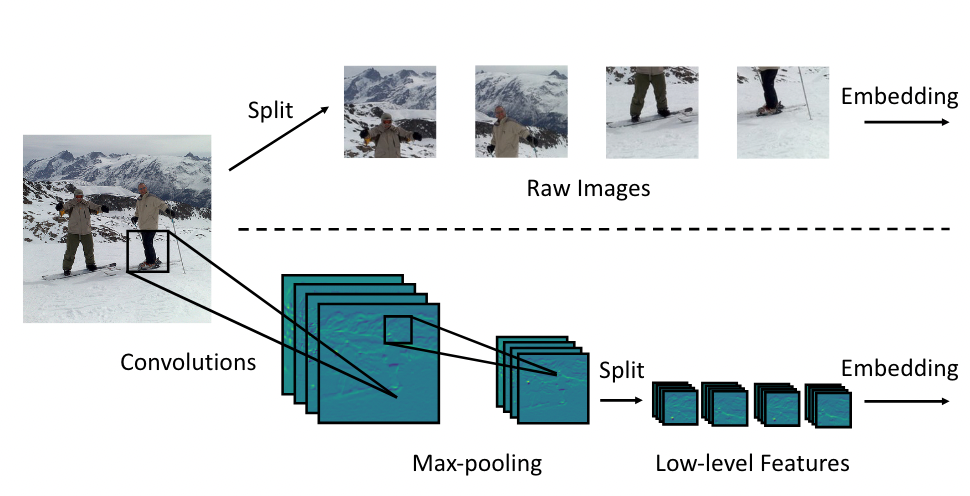
I2T (上图中下分支) 包含一个卷积层,MaxPooling 和 BN(没有激活函数?)
- 给定输入图像,I2T 的前向过程可以表示为
\mathbf{x’}=I2T(\mathbf{x})=\text{MaxPool(BN(Conv(\textbf{x})))}
$\mathbf{x'}\in R^{\frac{H}{S}\times \frac{W}{S}\times D}$ 是得到的特征图,$S$ 表示 stride,$D$ 表示经过卷积后得到的 channel 数量 (文中称为 the number of enriched channels) 2. 对 $\mathbf{x}'$ 切 patch > To keep the number of generated tokens consistent with ViT, we shrink the resolution of patches into ( P/S, P/S ). In practice, we set S = 4. ( 这里的 S 还是 Stride 吗?) > [! Question] 图中展示的 Embedding 怎么操作? **FFN (Locally-Enhanced Feed-Forward Network, LeFF Module)** 正常的 FFN 是经过一个 expansion 的 MLP 然后在 shrink 回来,这里的操作是在 expansion 和 shrink 的中间进行的 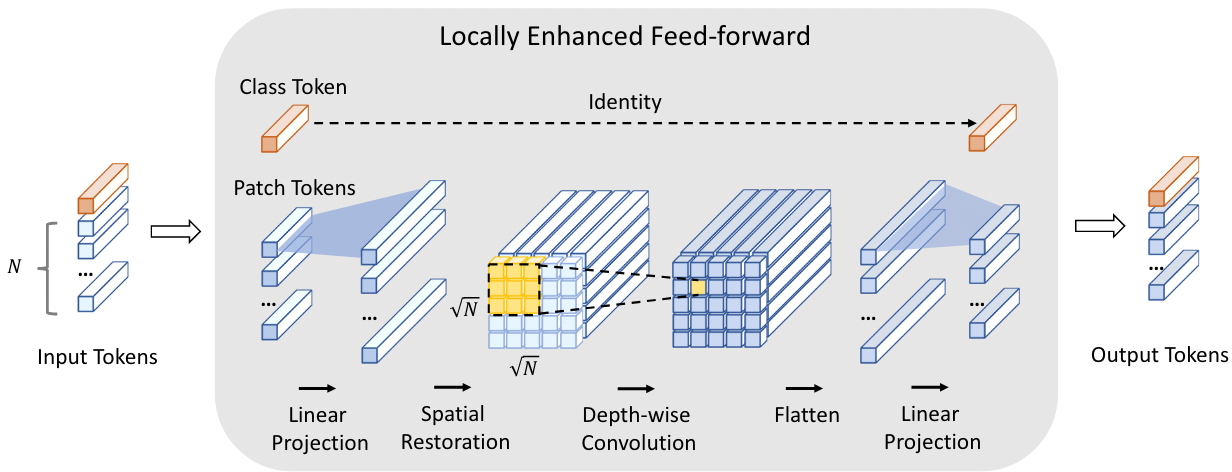 - 上图中前面的 Linear Projection 和最后的可以认为是 expansion 和 shrink,引入 CNN 的操作都是在其中间进行的 1. 将所有的 Expansion 之后的 patch tokens 按照原始的空间位置进行 reshape,这样就得到了一个特征图,而每个 token 的维度 $d$ 就是这个特征图的 channel 数量 2. 在这个特征图上做 depth-wise conv.,然后展平,reshape 成序列状的 tokens 3. 将得到的 Sequence tokens 进行 MLP shrink 到输入的尺寸,即得到输出。 **Layer-wise Class-Token Attention (LCA)** - 可以认为是一个小改进,并不是本文的重点 > “Unlike the standard ViT that takes the class token at the last $L$ -th layer as the final representation, LCA makes attention over class tokens at different layers.” (Yuan 等, 2021, p. 5) 一句话,取出所有层的 CLS Token 的输出,搞到一起,进行一次 Standard MSA,其输出视为最终的 CLS Token 用于分类。因为是将所有 cls token 拼接起来,其输出的 sequence 中对应最后一层的 token 的位置作为最终的 cls token #### 复杂度分析 暂略 #### 网络结构  ## Experiments #### 实验设置  #### ImageNet Results 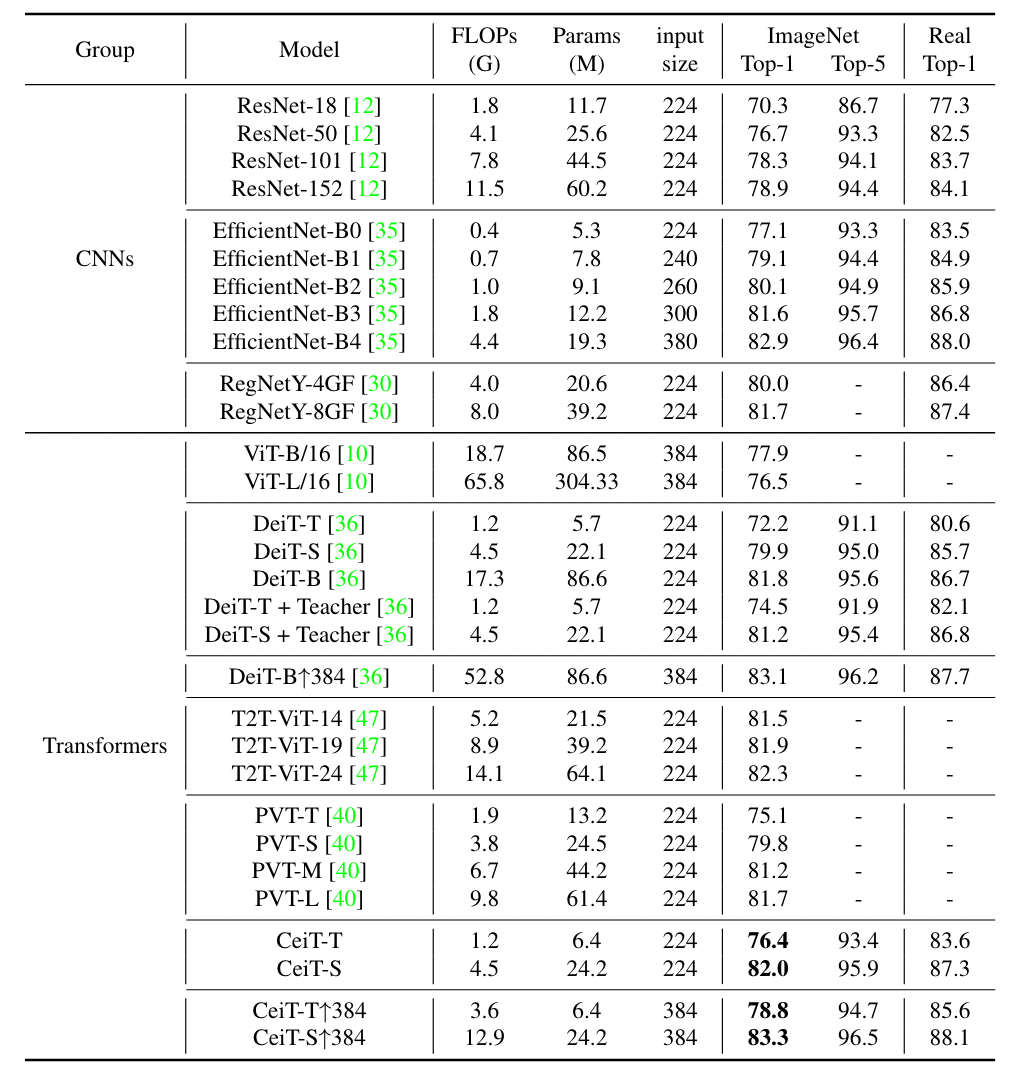 **与 CNN 比较** - ResNet50: CeiT 的参数量和计算量分别为其 1/3 和 1/4,却得到了接近的结果 - 输入尺寸差不多的情况下,可以压制 EfficientNet,但是此时的参数量和计算量更大 (即综合性能还是比不上 EfficientNet) #### Transfer-Learning (略) ### 消融实验 #### I2T 的结构和参数 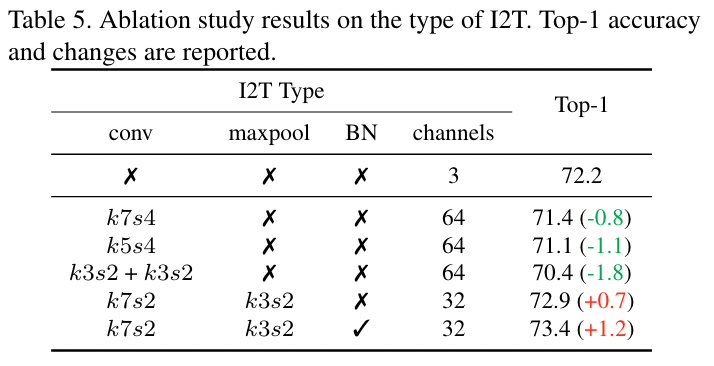 - MaxPooling 的提升好明显,BN 也是有一定的效果的 - 单独使用卷积效果不好 - 相同的输出通道下,减少 kernel size,即感受野,效果会越来越差。 > [! Note] 在应用卷积操作的时候,最好是==卷积+Pooling+BN== 的结构一起出现,能够获取到最好的结果 #### LeFF 的参数和结构 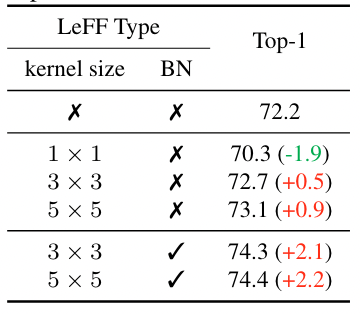 - 注意这是 depth-wise conv. - 同样感受野越大越好 - 虽然没有用 Maxpool ,但是 BN 同样带来了不可忽视的性能提升。值得注意的是,引入 BN 后,感受野的影响变得可以忽略了,因此文中使用 3x3 的卷积核 #### LCA 的有效性 引入 LCA 后结果提升了 0.6 个百分点 (72.2%➡72.8%) ### 收敛速度 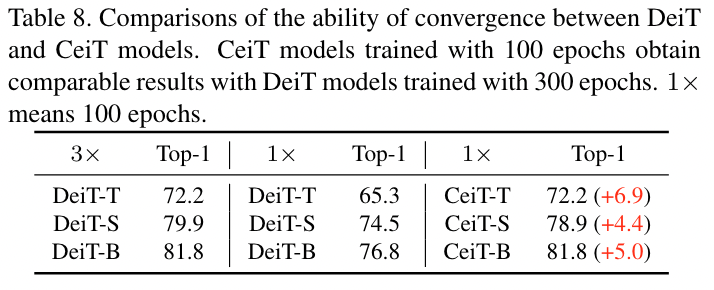 和 DeiT 相比收敛速度比较快 (感觉比较的模型少了点) DeiT 通过蒸馏的方式获取到 CNN 的 inductive bias,明显效率要比直接引入 CNN 的方式 (即本文的 CeiT) 效率要差 ## Some Descriptions - Transformers [38] have become the *de-facto standard* for natural language processing (NLP) tasks - Vision Transformer (ViT) [10] is the first pure Transformer architecture that is directly *inherited from* NLP - relies *heavily* - as the network *deepens* - But CeiT-T only requires *3× fewer* FLOPs and 4× fewer Params than ResNet-50. (如何描述倍数小于 1 的情况) - Looking back to the convolution, the main characteristics ... (回顾 CNN,主要的特点是....,(似乎发生了定语悬垂,注意这是合理的))