Cross-Modality Fusion Transformer for Multispectral Object Detection
Links
- PDF Attachments: Qingyun 等 - 2022 - Cross-Modality Fusion Transformer for Multispectra.pdf
- Zotero Links: Local library
- Official Code: GitHub
My Comments and Inspiration
- 关于融合的思考有趣,但是存在着缺陷,这是我可以参考和改进的点
- 融合较为普通,直接想加合理吗?
Preface
在多光谱图像融合的物体检测领域,存在着如下问题
- 如何令提取的特征能够充分利用不同模态之间的内在互补关系
- 如何设计高效的跨模态融合机制来尽可能的提升表现
为此,作者提出了 Cross-Modality Fusion Transformer (CFT) 模块 (其实是个融合模块而不是网络) 。
Methods
本文的实际上主体使用的是 YOLOv5,并采用了双流网络的结构,每个 stream 接受一个模态的输入。然后插入了 CFT 模块对两个分支进行融合。可以视为对 YOLOv5 的扩展。
本文中一共有两个模态,RGB 和 thermal modalities,两者的图像是对齐的。
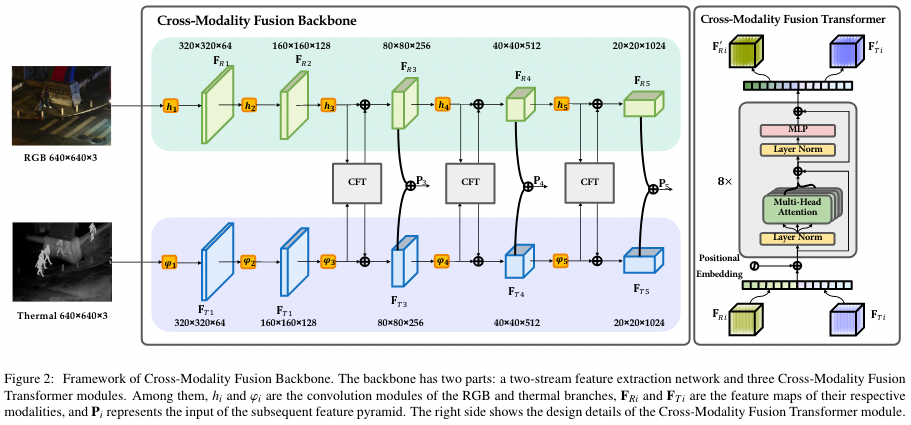
上图右侧展示了本工作中 CFT 的机构,非常浅显易懂。
左右两个分支同一级的输出特征图 () 进行 reshape ,并且进行 cat,然后送入一个 MHSA 中进行融合(含 pos. embed.),得到的结果再直接从中间 split 回到自己分支中 (相加回去)
Why
这里作者的解释挺有意思的。
我们给定两个模态在同一级的输出并将其 reshape,可得 , ;进行 cat 可以得到
当我们进行 self-attention 时可以得到其 attention map , 如下
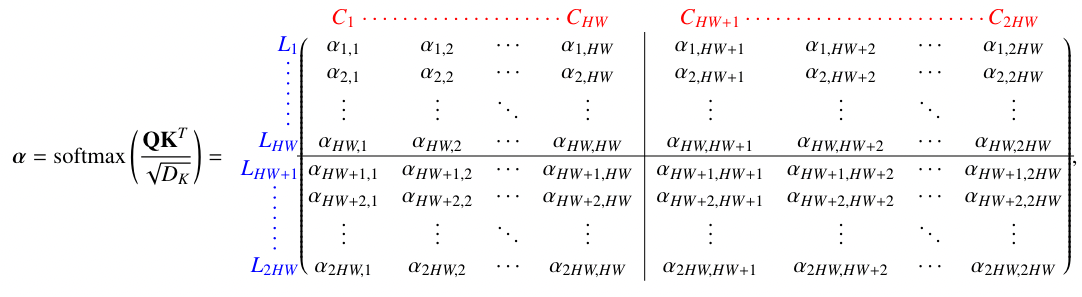
我们可以把其分成 4 块,每一块子矩阵都具有明确的含义
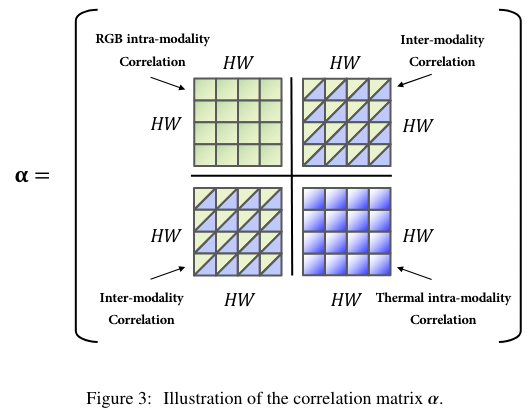
- 左上角:模态 1 的内部相关关系
- 右下角:模态 2 的内部相关关系
- 左下角:模态 1 和模态 2 之间的相互关系(模态 1 为 Query,模态 2 为Key)
- 右上角:模态 2 和模态 1 之间的相互关系(模态 2 为 Query,模态 1 为 Key)
作者认为,使用这种方式进行融合,能够充分利用 Transformer 的特点,其能够自动同时完成模态内和模态间的信息融合和隐式的信息交互,一句两个。
[! Warning] 可能存在的问题
- 实际上 Q 和 K 不是原始的 Tokens,而是经过了一次映射的 query embedding 和 key embedding。经过这次映射,模态 1 和模态 2 的信息已经发生过信息的交互了,所以得到的 无法按照上面的 4 个分区进行意义的总结,是不严谨的。
- 如果上述成立,在做 softmax 的时候,是按照行进行概率归一化的,这样就会导致模态内的相关性和模态间的相关性被同时归一化了,这可能会受到数量级的影响,导致其中一种相关性被完全压制
- 这个矩阵并不是对称的(因为实际使用的 Q 和 K 不是一样的;若 Q=K,则是对称的了),如上所述,至少左下角和右上角的矩阵是不一样的,作者使用了相同的符号画图并不严谨。并且其中一个为 query 另一个为 key 和一个为 key 另一个为 query,两者具体有什么意义呢?
Experiments
Some Descriptions
中间的特征图如何描述: intermediate RGB convolution feature maps