CAT: Cross Attention in Vision Transformer
Links
- PDF Attachments: 2022’CAT_Lin et al_.pdf
- Zotero Links: Local library
- Official code: Github
My Comments and Inspiration
- 其 CPSA 比较有意思,通过较为复杂的变化,完成了 cross patch 的注意力,并且降低了计算复杂度
- 其 Projection layer 可以认为是一个比较常规的方法,但是应该是第一个用在这个地方的,属于消融实验的类似 slice 的操作
- 这个模型复杂度降低的真的很客观,所以多考虑考虑对于特征图的操作
❓能不能 shuffle 特征通道进行参数量的降低?
Preface
- 经典的将 Transformer 应用在图像上的工作是将图像中每个像素点视为一个 Token,但是这带来了极大的计算量。
- CNN 的特点是 shared weight, translation, rotation invariance and locality。这些内在特性使得 CNN 在图像上应用有天然的优势,并且统治 CV 长达十年的时间。
- 图像 patch 的内部信息在 CV 中也是十分重要的(要考虑为什么,这些文章怎么证明的)
“The relationship between internal information of the patch is vital in vision[52, 53].” (Lin 等, 2022, p. 3)
- 作者认为 TNT 和 Swin 的缺点如下:
- TNT:直接搞了两个 Transformer,计算量太大了
- Swin:局部信息交互与相邻块的交互导致 Swin 缺少整体上全局信息交互
- Hierarchical structure 在一些 CV 任务中是十分重要的,譬如检测、分割等等 (典型的是 FPN 网络,UNet 这种),有时也需要网络能够有类似多尺度、金字塔的一些功能,而 Swin 和 PVT 都通过在不同的 stage 中降低特征的分辨率。本文中也采用了类似的方法。
Motivation 类似 CvT, CeiT, DeiT, CrossViT 的工作,都是一股脑的将所有的 patch 送到 MSA 中提取全局信息,这样的操作一方面面对大尺寸的图像的时候,会有非常大的计算量 (TNT, CvT, CrossViT);另一方面是并没有关注到局部信息 (CvT, CrossViT),或者关注到了局部信息但是又缺少整体上的全局建模能力 (Swin)
Goal
- 网络能同时关注到 Patch 内部的信息交互,也能关注到 Patch 之间的信息交互(Global 和 Local)
- 网络具有层级结构
- 网络的计算量增加不会太快,同样的输入尺寸,该网络应该具有比较小的计算量
Contributions
Methods
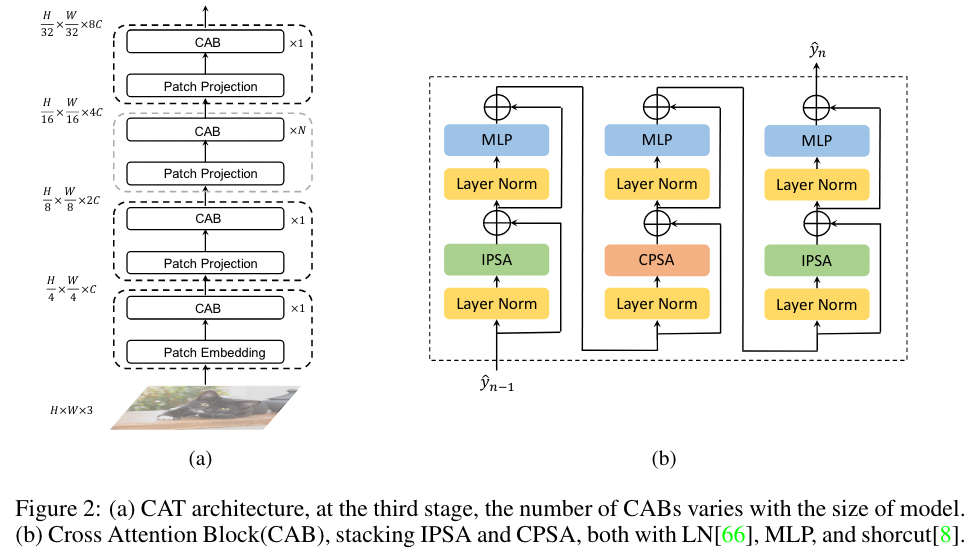
- 首先对输入的图像进行 4 倍的下采样,直接 Resize 到[H/4, W/4]
- 经过 patch embedding layer (同 ViT) 将其通道数扩增
- 逐次经过 4 个 Stage,后三个 Stage 由 Patch Projection + Cross Attention Block (CAB) 组成,CAB 的流程如上图。
Inner-Patch Self-Attention Block (IPSA) 该模块用于获取 patch 内部的交互(Local),即一个 patch 是实施注意力机制的范围,而不是整幅图像
(这里我感觉自己说的不是很清楚) 实际上就是做 MSA 时讲范围控制在一个 patch 内(是在 reshape 之后的 token map 上切的 patch)。在这个 patch 里做 MSA 时,就认为是一个像素点是一个 sub-token,那么一个 patch 内做 MSA 的时候,attn_map 尺寸就是[patch_size*patch_size]
在实现代码的时候,就是讲特征进行重组和维度上的变换。
[! Note]- 本部分的代码
# partition patches = partition (x, self. patch_size) # nP*B, patch_size, patch_size, C (nP 表示 patch nums, B 表示 batch size) patches = patches. view (-1, self. patch_size * self. patch_size, C) # nP*B, patch_size*patch_size, C . # IPSA if self. attn_type == "ipsa": # 这个 self. attn 似乎就是标准的 MSA 函数 attn = self. attn (patches) # nP*B, patch_size*patch_size, C def partition (x, patch_size): ''' Args: x: (B, H, W, C) patch_size (int): patch_size Returns: patches: (num_patches*B, patch_size, patch_size, C) ''' B, H, W, C = x.shape x = x.view (B, H // patch_size, patch_size, W // patch_size, patch_size, C) patches = x.permute (0, 1, 3, 2, 4, 5). contiguous (). view (-1, patch_size, patch_size, C) return patches
Cross-Patch Self-Attention Block 该模块用于 Patch 之间的交互,此时的 Attention 范围是整个图像。
本部分借鉴了 Depth-wise conv. 的思想,逐通道进行 self attn 每个通道的 patch 的 token embedding 就是当前通道的该 patch 内的所有像素点拉直 (dim = patch_size*patch_size)
具体的过程可以看下面的代码,通过维度的变化即可理解本操作
- 假设对当前输入的特征图进行 reshpe 后得到的尺寸为 [H, W, C]
- 我们对其进行切 patch 并重新整理维度,得到 x,尺寸为 [nPatch, patch_size*patch_size, C],显然有
- 按照上面的描述进行维度变换,得到的特征尺寸为 [C, nPatch, patch_size*patch_size]
此时类比标准的 attn 操作输入,C 对应 batch_size, nPatch 对应 Sequence length, patch_size*patch_size 对应 token dimension)
- 接下来进行标准的 MSA 操作,得到输出后按照维度将其反变换回去得到输出
[! Note]- 本部分代码
# partition (同上) patches = partition (x, self. patch_size) # nP*B, patch_size, patch_size, C patches = patches. view (-1, self. patch_size * self. patch_size, C) # nP*B, patch_size*patch_size, C # CPSA if self. attn_type == "cpsa": # 下面代码中两步维度变化[B, nP, patch_size*patch_size, C] -> [B, C, nP, patch_size*patch_size] patches = patches. view (B, (Hp // self. patch_size) * (Wp // self. patch_size), self. patch_size ** 2, C). permute (0, 3, 1, 2). contiguous () # 下面代码的维度输出 [B*C, nP, patch_size*patch_size] patches = patches. view (-1, (Hp // self. patch_size) * (Wp // self. patch_size), self. patch_size ** 2) # 下面代码的维度变化: # self. attn (patches) 得到的 attn map 维度为 [B*C, nP, patch_size*patch_size] # 接下来的变化为 -> [B, C, nP, patch_size*patch_size] attn = self. attn (patches). view (B, C, (Hp // self. patch_size) * (Wp // self.patch_size), self. patch_size ** 2) # 维度变化:[B, nP, patch_size*patch_size, C] -> [B*nP, patch_size*patch_size, C] attn = attn.permute (0, 2, 3, 1). ontiguous ().view (-1, self. patch_size ** 2, C)
Patch Projection (降维用) Patch Projection 用于引入 Hierarchical 结构
对于输入[H, W, C]的已经 reshape 的特征图,通过以 2 为步长进行采样得到 4 个尺寸为[H/2W/2, C]的子特征图,将其拼接成[H/2W/2, 4C],利用 FC 进行降维操作 (4C → 2C) , 即每次
实际上就是将 2*2*C 的子块特征重塑成 1*1*4C,之后线性映射到通道数为 2C
具体可以参考代码
class PatchProjection(nn.Module):
def __init__(self, dim, norm_layer=nn.LayerNorm):
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
'''
Args:
x: Input feature, tensor size (B, H*W, C).
H, W: Spatial resolution of the input feature.
'''
x = x.view(B, H, W, C)
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return xPosition embedding
ISPA:Relative position encoding CPSA:Absolute position encoding
计算复杂度 (略)
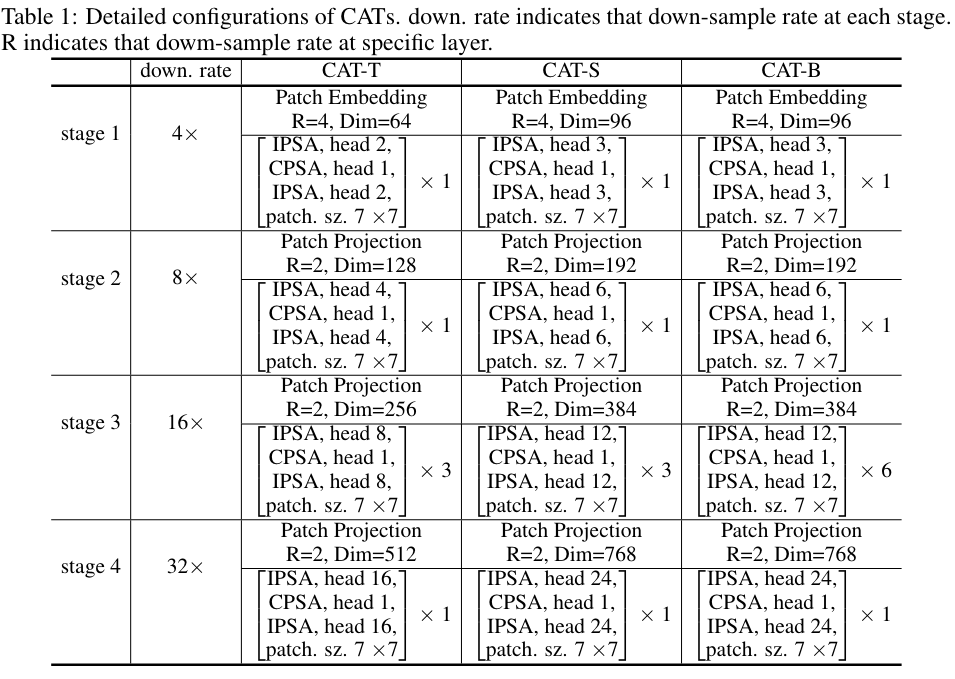
网络结构
Experiments
实验设置
- 实验设置同 DeiT 文章[38]
- bs = 1024
- lr = 0.001,cosine decay learning rate schedule,linear warm up 20 epochs
- AdamW, weight decay = 0.05
- epochs = 300
- stochastic depth = 0.1,0.2,0.3 for CAT- T, CAT-S, CAT- B
- dropout p = 0.2
- Same regularization strategies and augmentation with [38]
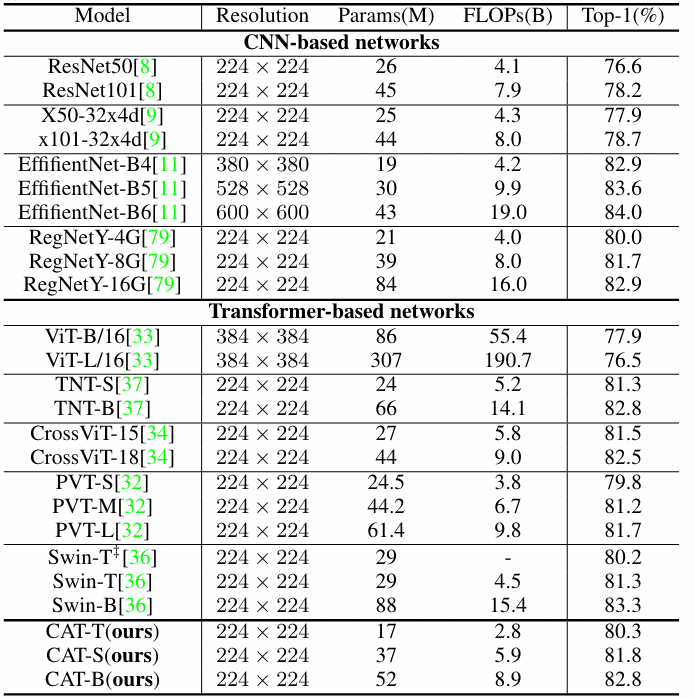
Classification task
Object detection
Semantic Segmentation
消融实验
Patch embedding function and Multi-head and shifted window

- Patch embedding 的两种方式(主要考虑如何降维到原图的 1/4)
- Slice:[H, W, C] → [H/4, W/4, 4C]
- Conv.: stride = 4, kernel_size = 4 对 [H, W, C]降维
- Setting the number of heads equal to patch size in each CPSA, which is useless to the performance (多头没用,所以上面的网络结构中,CPSA 的 heads 数设置为 1)
- shifted windows 几乎不起作用
实际上也能发现,这个消融实验做的,基本没有什么有效的信息,结果的变化都微乎其微。
Absolute position and dropout in self-attention of CPSA
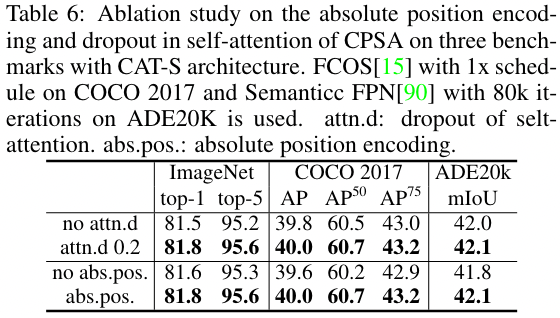
- dropout 有用
- 绝对位置编码有用
Some Descriptions
- which bottlenecks model training and inference
- we propose a new attention mechanism in Transformer termed Cross Attention
- Since 2012, CNN has dominated CV for a long time, as a crucial feature extractor in various vision tasks, and as a task branch encoder in other tasks.
- AlexNet laid the foundation for the later development of the CNN-based network.
参考资料