BAM: Bottleneck Attention Module
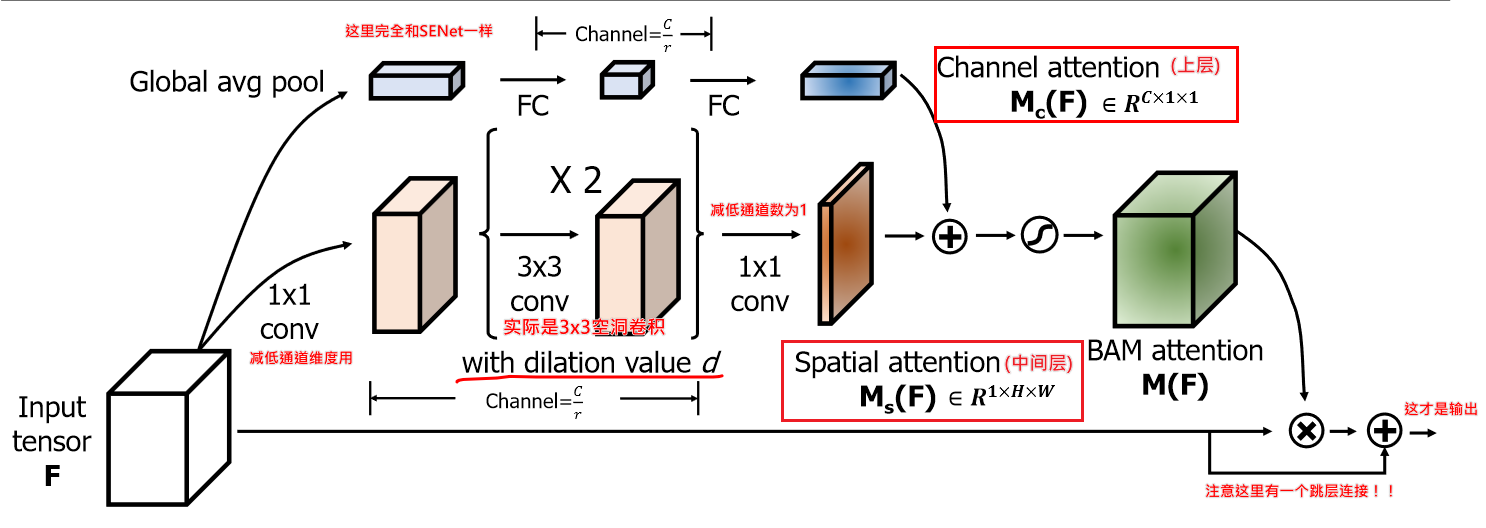 (动机不强)为了进一步增强网络的表达能力,作者提出BAM Block,将通道注意力和空间注意力进行了融合,得到统一的3D attention map,并引入跳层连接。与其他工作不同的是,作者将BAM模块仅仅放置于网络的bottleneck处。这使得网络增加的参数量比其他注意力网络都要少,同时性能却更好。
(动机不强)为了进一步增强网络的表达能力,作者提出BAM Block,将通道注意力和空间注意力进行了融合,得到统一的3D attention map,并引入跳层连接。与其他工作不同的是,作者将BAM模块仅仅放置于网络的bottleneck处。这使得网络增加的参数量比其他注意力网络都要少,同时性能却更好。
Links
- PDF Attachments: Park - BAM Bottleneck Attention Module.pdf
- Zotero Links: Local library
My Comments and Inspiration
Cores, Contributions and Conclusions
Preface
本文的动机,但是这个动机并不强。并且前面并没有很好的引子去引出这个动机,前面简单说了提升网络的表现可以通过设计更好的网络结构,增加网络层数。而作者要从注意力模块去做这个事情。
“While most of the previous works use attention with task-specific purposes, we explicitly investigate the use of attention as a way to improve network’s representational power in an extremely efficient way.” (Park, 2018, p. 2)
Methods
- 输入中间特征图
- 分别 经过通道注意力模块和空间注意力模块(两者并联)
- 将经过两个模块得到的两个结果(一个向量 一个是特征图 )广播后直接相加,并经过Sigmoid后得到,尺寸和 F 一样,为
- ,对应元素相乘后和输入相加(即跨层)
channel attention module:同 SENet 差不多,但是先 avgpooling, 然后两层全链接,然后再接一个 BN,无激活函数
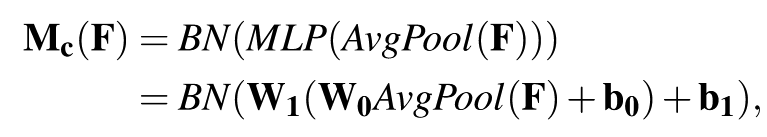
spatial attention module:
- 输入
- 经过 卷积将通道压缩至
- 连续经过两个 3x3 的空洞卷积层,dilation value = d
- 再经过 卷积将通道变成 1
以上四步的数学化表述
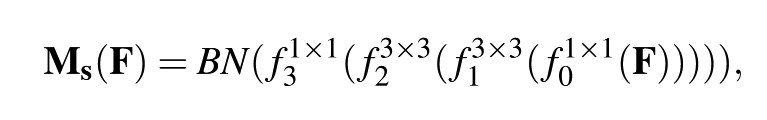
中间没有BN,只有最后一个有BN吗?ReLU应该有的把
为什么使用空洞卷积
因为空洞卷积能够提供更大的感受野,但是又不增加太多的参数量。 使用大的感受野操作能够获取更多上下文信息,对于构建好的空间注意力有很好的帮助。后面的实验也证实了在构建空间注意力图的问题上使用大感受野的卷积效果更好。(这里就和 CBAM 的实验结果对上了,两者说法一致)
Experiments
消融实验
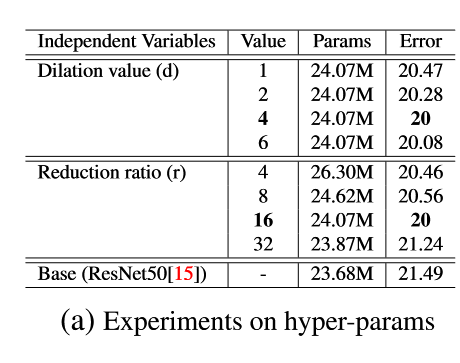
Dialation value 和 Reduction ratio 的参数实验
- the performance improvement with larger dilation values, though it is saturated at the dilation value of 4. Thus, dialation value = 4
- r = 16 效果最好
BAM比单独加任何一个都有效; 同时实验说明两个分支采用相加的形式合并表现最好
- PROD 指的是 element-wise product,对应元素相乘。
Element-wise product, which can assign a large gradient to the small input, makes the network hard to converge, yielding the inferior performance.
- MAX 指的是对应元素区最大值 element-wise maximum
Element-wise maximum, which routes the gradient only to the higher input, provides a regularization effect to some extent, leading to unstable training since our module has few parameters

其他实验
瓶颈:是stage和stage的交界部位,如图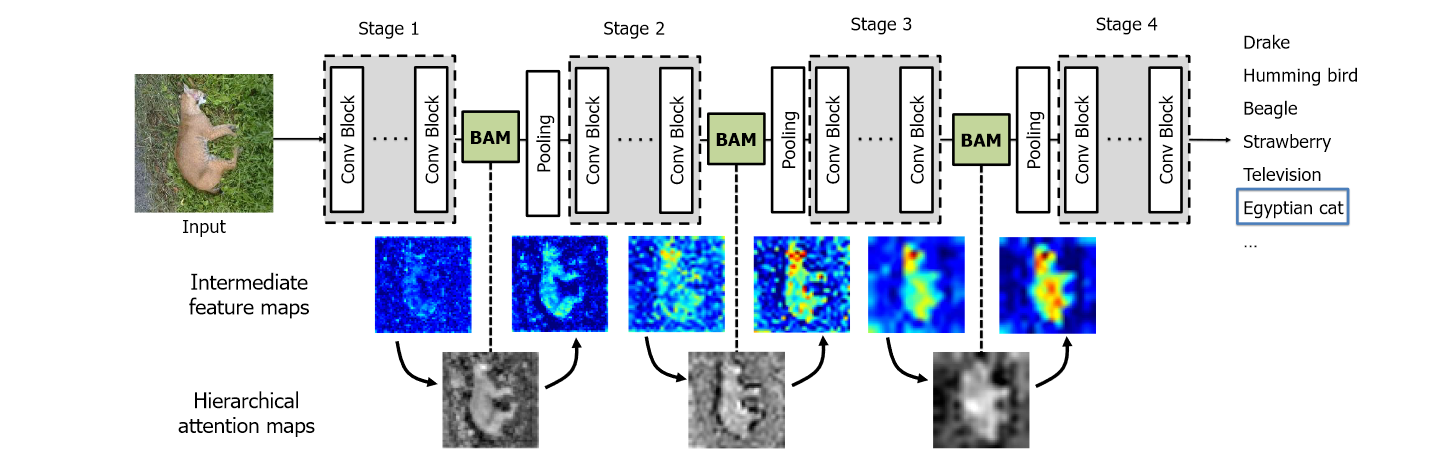
BAM 放置于瓶颈的位置效果最好,同时作者证明了这种效果的提升并不是由于深度的加深而导致的。
以往的 Attention 模块都是直接插入到 conv. block 的里面,如 CBAM,SENet 等等,而 BAM 则被作者证明插入到网络的 Bottleneck 处提升的效果最大
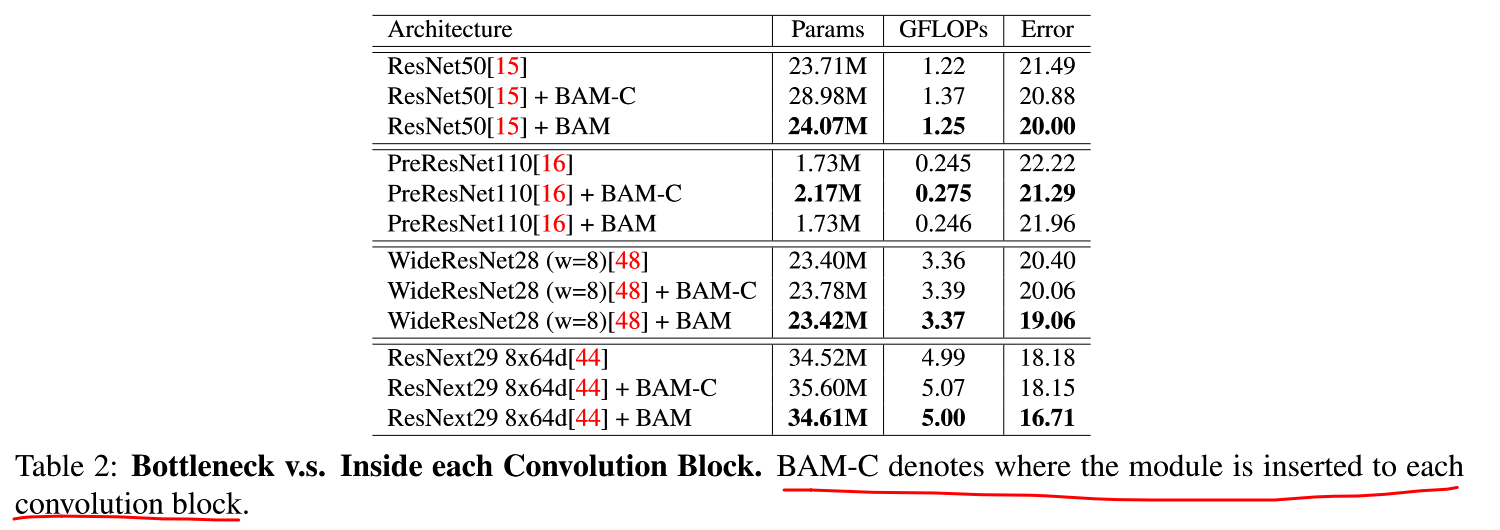
实际上,由于仅仅放置在 bottleneck 处,和放置在每个 conv block 的其他注意力相比,参数会更少,同时具有更好的表现。(作者在文中对比的是 SENet)
Our module requires slightly more GFLOPS but has much less parameters than SE, as we place our module only at the bottlenecks not every conv blocks.
此外,作者进一步进行了Image-1K和CIFAR-10分类实验,VOC 2007 Object Detection,MS COCO Object Detection的实验,结果都是SOTA(比较的是Baseline和加了BAM的结果,都有提升)