在这篇文章中,我们对网络中的 Normalization 进行一个总结。我们已经写了对应的详解,因此这篇文章更多的是从一个更高的角度去完成这样一个事情,并进行总结。(本文包括BN, LN, IN, GN。实际上,还有其他的归一化方法,我们慢慢补充)
为什么需要在网络中进行归一化?
BN 提出的动机,也适用于其他后续的归一化方法。虽然可能在对应的工作中已经淡化了这些最原始的动机,但是依然不妨碍我们去探讨它的本质。
- 网络中存在内部协变量偏移 (Internal covariate shift, ICS)
- 所有的网络层输出若都服从同一分布,可能会降低网络的表达能力。
在大的视角上去解决这些问题
既然有了动机,我们可以考虑如何去解决问题。
针对问题 1,我们可以通过进行归一化来让数据或者数据的某一个部分变换到同一个分布,具体为
在这里, 和 分别表示 的均值和方差, 表示数据。这个数据具体是一整个特征图还是特征图的某一个部分,根据归一化的方法来决定。
针对问题 2,我们只需要引入两个可学习的尺度和平移参数 和 即可,通过下面的变换改变数据的分布
在小的视角上去解决更多的问题
从小的视角上来看,不同的归一化方法主要在计算均值 和方差 的方法上不同,他们都出自不同的,更具体的动机。 我们在这里讨论 BN, LN, IN 和 GN 这几个方法,他们的异同我们放在最后一节进行总结。
首先,我们放一张图来展示不同的归一化方法在计算均值和方差上的区别,然后我们再简单的介绍每种归一化方法。
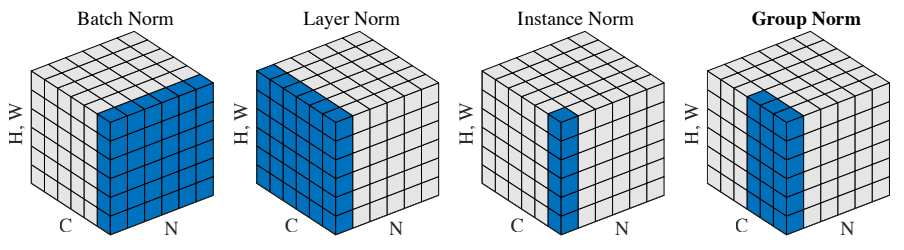
在开始前,我们假设需要归一化的特征图尺寸都为
Batch Normalization (BN)
BN 作为最早的归一化方法,在 InceptionNet V2 中被提出,流行至今。其动机就是为了解决我们上面说的两个问题。
均值 和方差 : 计算一个 batch 中所有特征图同一个通道的均值和方差,即会得到 个均值和方差。归一化时该 batch 的所有特征图的同一个通道与对应的均值方差进行归一化。
显然,BN 和 Batch size 有关,它是在 进行均值方差计算。
在推理时,BN 利用在训练时得到的均值方差对测试样本的均值方差做无偏估计,实际上与测试样本无关。
Layer Normalization (LN)
动机:BN 无法应用于 batch size 很小的情况,同时无法应用于 RNN 中序列长度变化的情况中
均值 和方差 : 计算一个 batch 中每个单一特征图整体的均值和方差,在上计算,即会得到 个均值和方差。归一化时每个样本的特征图整体进行归一化,只和自己有关。
和 Batch size 无关
推理时直接计算测试样本的对应均值方差
Instance Normalization (IN)
动机:在生成任务中,每一个pixel都是重要的;同时研究表明,跨通道的交互对于风格迁移类的任务十分重要。不同通道的信息可能表明了不同的风格,而BN和LN都直接进行跨通道的交互,这类操作过于粗糙,导致丢失了很多潜在的风格信息。
均值 和方差 : 计算每个样本特征图的每个通道的均值和方差,在 维度上计算,即会得到 个均值和方差。归一化时每个样本的每个通道单独进行归一化。
和 Batch size 无关
推理时直接计算测试样本的对应的均值方差
Group Normalization (GN)
动机:BN 在不能在小 batch size 上进行使用;同时,测试时 BN 是使用了在训练阶段保留的均值方差做测试数据的无偏估计,这可能就会导致在训练、测试、验证阶段的不连续性
GN首先将每个样本的按照通道分成了组,那么每组的特征图可以写为 .
均值 和方差 : 计算每个样本特征图的每组特征图的均值和方差,即会得到 个均值和方差。归一化时每个样本特征图的对应 group 单独进行归一化。
和 Batch size 无关
推理时直接计算测试样本的对应的均值方差。
各种归一化的异同
- 显然,这四种归一化中只有 BN 和 Batch size 有关。
- BN 无法用在 RNN 和小 Batch size 上,因为前者尺寸不定,后者一个 batch 内样本数量太少,可能与整体的均值方差偏差过大,导致网络变得不稳定,收敛速度变慢
- 由于 BN 受到 Batch 选择的影响,因此必需进行数据的 shuffle
- LN 常用在 RNN 中,注意在 Transformer 中 (包括ViT) 使用的也是 LN
- IN 常用在生成式任务和图像风格迁移的任务中,能够以更细的粒度进行操作
- LN 和 IN 可以认为是 GN 的两种特殊形式,分别对应 和 两种情况。
未解的问题
- GN 适合什么场景…
相关资料