Leetcode Link: 332. 重新安排行程 - 力扣(LeetCode)
题目
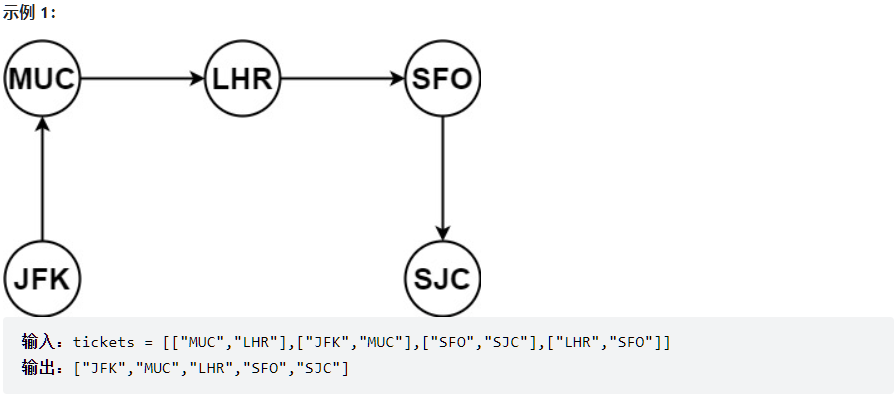
给你一份航线列表 tickets ,其中 tickets[i] = [from_i, to_i] 表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。
所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。
例如,行程 ["JFK", "LGA"] 与 ["JFK", "LGB"] 相比就更小,排序更靠前。
假定所有机票至少存在一种合理的行程。且所有的机票 必须都用一次 且 只能用一次。


本题难点 分析为何会超时;针对特殊的数据,如何改变输入的形式避免超时。
本题属于排列的问题,在给定的答案中选择满足要求的排列。
最好是程序能一次性找到这个满足要求的排列,然后算法停止遍历其他的子树(相当于剪枝把其他的子树都给剪没了,就走了一次正确的子树);而不是找到所有可能排列后,在从这排列中找到满足要求的(这样很容易超时)
解法一
思路:
最最 naive 的回溯,不考虑图(会超时,但是应该是没错的),走所有的子树,从所有可能排列中要到满足要求的。
超时的原因在于输入的 tickets 太长了,然后每次遍历的次数就非常非常大,虽然我已经优化了 for 中的步骤并且进行了剪枝
满足题目要求 到达叶子节点(不符合题目要求的会被剪枝)
回溯停止 到达叶子节点
剪枝
- 上一个站的终点和当前站的起点不一样
- 使用过当前的机票了
- 第一张机票需要从
"JFK"出发
题解:
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
def backtracking():
nonlocal tickets, res, true_path, lookup
# 条件满足 且 停止回溯
# 收集叶子节点信息
if len(tickets) == len(true_path)-1:
res.append(true_path.copy())
return
for idx, val in enumerate(tickets):
# 第一张票需要从JFK出发
if len(true_path) == 1 and val[0] != "JFK":
continue
# 上一个机票(要先保证有)的降落机场不等于这个机票的出发机场,剪枝 continue
# 使用过这个机票了, 剪枝,continue
if lookup[idx] == 1 or (len(true_path) > 1 and true_path[-1] != val[0]):
continue
true_path.append(val[1])
lookup[idx] = 1
backtracking()
true_path.pop()
lookup[idx] = 0
res = []
true_path = ["JFK"]
lookup = [0] * len(tickets)
backtracking()
# 如果直接append(val)会导致res输出是这样的:[[["JFK","MUC"],["MUC","LHR"],["LHR","SFO"],["SFO","SJC"]]]
# 然而我们的答案需要这样的:["JFK","MUC","LHR","SFO","SJC"],所以用的是 true_path
slim_res = res
# 只有一个路径,直接返回
if len(slim_res) == 1:
return slim_res[0]
# 多个路径需要获取字典序
# 多次提交发现本题字典序不是按照首字母来的,是所有站直接拼起来的字符串的字典序
candi = []
for cur in slim_res:
candi.append("".join(cur))
small_res = slim_res[candi.index(min(candi))]
return small_res
解法二
思路:实际上解法一超时的原因在于每次都要遍历整个 tickets,所以我们可以先构建一个图(用字典实现),记录起点对应的所有终点 {起点:[终点1, 终点2,...]},这样就可以快速的找到了。
但是同样需要注意不要重复使用一张票,否则会死循环
参考的别人的,在递归的过程中就完成了字典序排序
通过实验发现,只要不是遇到一个满足条件的叶子节点返回的(即使本解法也是一样的),一定会超时。也就是说,本题需要我们在代码中一次找到满足字典序的答案。
因此需要在程序运行时就处理好字典序,而不是找到全部的答案后在从中选到最小的字典序
怪不得难呢!
题解:
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
def backtracking ():
nonlocal tickets, graph
if len(path) - 1 == len(tickets):
return True
start = path[-1] # 起点
for i in range(len(graph[start])):
tar = graph[start].pop(i) # 必需弹出,防止死循环
path.append(tar)
if backtracking():
return True
path.pop()
graph[start].insert(i, tar) # 必需及时更新回来,保证同一棵树上不遗漏
return False
path = ['JFK'] # 直接放入起点
graph = collections.defaultdict(list)
for val in tickets:
graph[val[0]].append(val[1]) #{起点: [终点]}
for key in graph:
graph[key].sort() # 这样就是字典序排序了
backtracking()
return path启发和联系
本题解法二是最重要的!
Note
- 如何提前退出回溯函数? 利用 if True, 此时回溯函数里只有 True 和 False 的返回值
- 对一个字符串列表直接
sort(),得到的就是字典序排序。- 当我们发现似乎已经不能剪枝了,但是还是超时怎么办?
- 利用
Ture和False提前退出回溯函数,即得到答案后直接返回,此时可能需要提前对数据进行处理,需要结合题意- 改变数据的输入形式或者数据的组织形式,同时实现for循环遍历的次数减少来降低运算量。