Leetcode Link: 647. 回文子串 - 力扣(LeetCode)
题目
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。
回文字符串 是正着读和倒过来读一样的字符串。
子字符串 是字符串中的由连续字符组成的一个序列。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。

从暴力递归到动态规划
暴力递归
实际上,由于左的模型大部分出现了情况重合的现象(由于最终求 min 或者 max,即使重合了也不会影响最终结果),因此在这种[L.. R]的范围上做情况分解变得十分棘手,如果出现情况重合,一定会出错,在求非最大最小值的时候,尽量避免使用左的范围尝试模型和样本对应模型。
因为到目前为止,样本对应模型和范围尝试模型都是求min和max的动归题,我无法有效的、清晰的、不重复的分解一般子问题的情况。
动态规划
直接一步到位思考 dp
虽然不能套用范围尝试模型,但是也能感觉出应该是一个二维 dp
因此,dp 五步走
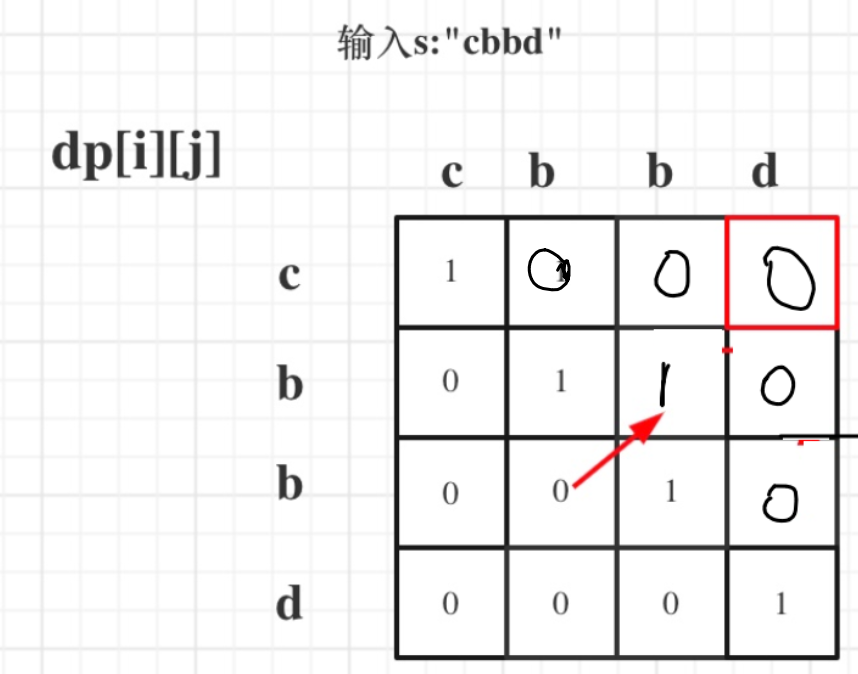
- 确定dp数组下标及含义:
dp[i][j]表示子串s[i..j](含边界)是不是回文子串,下标 i, j 表示范围,内容是 False 或者 True - 确定递推公式:一般情况下,
s[i..j]是不是回文子串,依赖于s[i+1..j-1]是不是回文子串,即递归公式为:dp[i][j]=True if dp[i+1][j-1]==True and s[i]==s[j] else False - 如何初始化?好像不用初始化?只需要判断就行?
- 确定遍历顺序:依赖左下,所以行倒着来,列正着来,同时只填写上三角
- 举例推导 dp 表
class Solution:
def countSubstrings(self, s: str) -> int:
dp = [[False for _ in range(len(s))] for _ in range(len(s))]
for i in range(len(s)-1, -1, -1):
for j in range (i, len (s)):
# 三个情况判断,缺一不可。
if i == j: # 对角线,即相等
dp[i][j] = True
elif i+1 > j-1: # 相邻位也能自己判定
dp[i][j] = True if s[i]==s[j] else False
else: # 一般情况
dp[i][j] = True if dp[i+1][j-1]==True and s[i]==s[j] else False
return sum([sum(row) for row in dp])解法二
思路:中心扩展法
从头遍历字符串,让其每一位、每一位及其下一位作为中心,计算两种情况下的回文子串的数量。
注意check()函数的编写。
题解:
class Solution:
def countSubstrings(self, s: str) -> int:
res = 0
for i in range(len(s)-1):
res += self.check(s, i, i) # p1. 以s[i]为中心扩展
res += self.check(s, i, i+1) # p2. 以s[i] 和 s[i+1] 为中心扩展
res += 1 # 把最后一个补上
return res
def check(self, s, i, j):
tmp_res = 0
if s[i] != s[j]: # 不相等的时候,说明一定是p1
return tmp_res
if s[i] == s[j]: # 相等的时候可能是p1或者p2, 但是p2中注意不能重复计算i和i+1单独位的回文
tmp_res += 1
i -= 1
j += 1
while(i>=0 and j<=len(s)-1):
if s[i] == s[j]:
tmp_res += 1
else:
break
i -= 1
j += 1
return tmp_res上面的 check 写复杂了,下面是简化的代码,其实不用判断中心是相邻还是重合。
def check(self, s, i, j):
tmp_res = 0
while(i>=0 and j<=len(s)-1 and s[i] == s[j]):
tmp_res += 1
i -= 1
j += 1
return tmp_res启发和联系
面对回文子串时,可以采用中心扩展法(递归、for),计算每一位/两位为中心的回文子串个数。
最后再考虑动态规划的方法